Android框架源码分析——以Arouter为例谈谈学习开源框架的最佳姿势
得意于众多项目和第三方库的开源,开发中使用几行代码即可实现复杂的功能,但使用只是源码库的搬运工,源码中真正牛逼的技术并不属于我们,所以对源码和开源库的学习成了Android开发者提升技能的必经之路,笔者也曾经认真学习了常用开源框架的原理和实现,足以在开发和面试中的问题,就此以为掌握了源码(有没有同道?),直到有一天自己去编写库,当面对框架设计、任务调度、任务并发、线程切换、缓存、文件等系列问题时,才发现自己的不足,也在反思自己的学习深度;其实框架中很多知识和代码都是经过时间的验证和优化过的,如:Glide的缓存、okhttp拦截实现、Retrofit的注解等,其细节完全可以帮助解决开发中的类似问题,源码的思想固然重要,但细节优秀的实现同样不容忽视,这里给出笔者总结的开源框架的学习方法:
- 了解开源框架的作用
- 掌握框架的使用方法
- 分析框架的工作原理
- 分析框架源码的架构和实现
- 深入框架细节分析功能模块的实现
- 总结收获
1、ARouter作用
谈起Arouter便不得不说组件化,随着项目的发展,开发的功能模块增多,项目和团队都会逐渐增大,即使分包和版本管理做的再好,还是无法避免在开发过程中所面临的问题:
- 开发过程中编译和修改的过程中会变得更加复杂,编译事件明显变长
- 整个项目为一个整体,代码牵一发而动全身,项目的维护难度将会增大;
- 伴随开发团队也会增加,严重耦合的代码和业务造成冲突不断,极大降低开发效率
为了解决这些问题组件化应运而生,相信组件化的使用和优势开发者深有体会,它很针对性的解决了以上问题:
- 组件可以独立开发、编译调试,缩短编译时间提高开发效率
- 组件间的解耦和代码的隔离,使功能模块和开发团队之间互不影响
但世界上没有绝对完美的事,它带来方便的同时也带来了一个问题:
- 组件解耦、代码隔离的同时也阻断了彼此的通信
那么实现组件间通信变成了首要要解决的问题,Android原生虽然可以实现脱离界面实现导航的目的,但真实使用时发现代码严重耦合,违背了我们组件化的目的,那么有没有一种简单易管理的通信方案呢?ARouter就是为此诞生,这里借用官方关于原生和路由的对比图:

关于ARouter的介绍这里提供一个官方的演讲内容:
- Android平台页面路由框架ARouter
2、ARouter的使用简介
知道了框架的作用,下面自然就是看看如何去使用,本文侧重于框架的源码和执行流程,不详细介绍框架的使用,因为下面分析源码的需要,这里只给出界面跳转使用,详细使用方法可以阅读Arouter的项目介绍:
- ARouter项目地址
- 实现界面跳转:根据跳转的功能需求,ARouter提供以下界面跳转方法
- 普通界面跳转
ARouter.getInstance().build("/login/activity").navigation()- 携带Key—Value参数传递
//ARouter提供withString()方法,参数传入对应的Key、Value
ARouter.getInstance().build("/login/activity")
.withString("Name", "USer")
.withInt("Age", 10)
.navigation()
//使用Autowired注解自动转换,参数name为传递参数的Key(当变量名和Key相同时可不设置name)
@Autowired(name = "Name")
@JvmField var name : String? = null
@Autowired(name = "Age")
@JvmField var age = 03、ARouter工作原理
- ARouter的工作流程图

一行代码就搞定了组件间的通信,是不是充满了疑惑和期待?下面看看这一行代码究竟如何路由起来的?本文的分析基于编写的组件化Demo中的ARouter的使用,这里不对它的编写和使用做介绍,只分析它编译生成的文件和执行流程进行分析,本篇以Activity执行为例分析源码,先看一下项目的结构和编译生成的文件:
- 项目结构:包含base、app、login、share、componenbase组件
- 编译文件:编译生成routes和modularization包
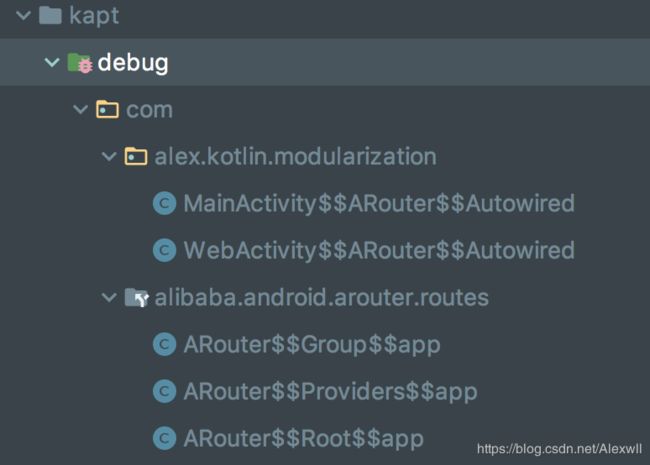
- Android组件化Demo
3.1、ARouter执行流程
由上面使用知道,界面的路由跳转有一行代码完成,那流程的分析也就从这行神奇的代码开始:
ARouter.getInstance().build("/login/activity").navigation()- build(String path)
ARouter.getInstance()单利获取ARouter实例,在ARouter.build()方法中使桥接模式将任务交给_ARouter的build()方法,方法中重点的就是最后一句话,直接调用build()创建PostCard实例:
//_ARouter.build()
protected Postcard build(String path, String group) {
if (TextUtils.isEmpty(path) || TextUtils.isEmpty(group)) {
throw new HandlerException(Consts.TAG + "Parameter is invalid!");
} else { ......}
return new Postcard(path, group);//创建PostCard保存路径和group
}
}- PostCard.navigation():build()方法只创建了一个PostCard实例,貌似所有的任务都留给了navigation
protected Object navigation(final Context context, final Postcard postcard, final int requestCode, final NavigationCallback callback) {
try {
LogisticsCenter.completion(postcard);//执行复杂的解析和配置
} catch (NoRouteFoundException ex) {......}
if (null != callback) {
callback.onLost(postcard);//如果回调Callback不为null,回调onLast()
}
......
if (!postcard.isGreenChannel()) { //如果没有设置绿色通道,要回调事件拦截
......
} else {
return _navigation(context, postcard, requestCode, callback);
}
return null;
}整个流程执行到这里,好像就做了三件事,但这三件事却完成了整个的导航过程:
- 在build()中创建PostCard实例储存路径
- 调用complete()方法解析postCard
- 调用_navigation()执行界面的跳转
- LogisticsCenter.completion(postcard)
在看详细的代码之前,先介绍下源码中出现的RouteMeta和Warehouse两个类,很容易看出这两个类都是保存数据的类:
- RouteMeta:保存每个跳转信息,如:路径、group、RouteType、优先级、参数等信息
- Warehouse:主要在初始化时缓存注解的Activity、IProvider、IInterceptor,主要用于缓存所有的路由信息
class Warehouse {
//保存group对应的IRouteGroup文件类
static Map> groupsIndex = new HashMap<>();
//保存路径path对应的RouteMeta信息
static Map routes = new HashMap<>();
//保存IProvider信息
static Map providers = new HashMap<>();
static Map providersIndex = new HashMap<>();
//保存拦截器IInterceptor信息
static Map> interceptorsIndex = new UniqueKeyTreeMap<>("More than one interceptors use same priority [%s]");
static List interceptors = new ArrayList<>();
} 下面查看completion(Postcard postcard)解析的代码:
public synchronized static void completion(Postcard postcard) {
RouteMeta routeMeta = Warehouse.routes.get(postcard.getPath()); // 根据路径从Warehouse.routes中获取RouteMeta
if (null == routeMeta) { //若未获取实例,根据设置的group组获取groupMeta
Class groupMeta = Warehouse.groupsIndex.get(postcard.getGroup());
if (null == groupMeta) { //若没有获取到分组则跑出异常
throw new NoRouteFoundException(TAG + "There is no route match the path [" + postcard.getPath() + "], in group [" + postcard.getGroup() + "]");
} else {
try {
IRouteGroup iGroupInstance = groupMeta.getConstructor().newInstance();//反射创建实例
iGroupInstance.loadInto(Warehouse.routes); //调用lodaInfo()将信息加载到Warehouse.groupsIndex中
Warehouse.groupsIndex.remove(postcard.getGroup());
} catch (Exception e) {
throw new HandlerException(TAG + "Fatal exception when loading group meta. [" + e.getMessage() + "]");
}
completion(postcard); // 在第一次根据path获取为空后会根据group添加,添加之后会再次获取
}
} else {
postcard.setDestination(routeMeta.getDestination()); //设置postcard数据
postcard.setType(routeMeta.getType());
postcard.setPriority(routeMeta.getPriority());
postcard.setExtra(routeMeta.getExtra());
}
}上面代码注释很清楚,completion()方法主要是根据初始化时加载的group组,去加载要导航的RouteMeta信息,这里采用按需加载的方式,先只初始化缓存每个group对应的类文件,然后在第一次执行跳转时才初始化每个group中所有路径的信息并缓存在Warehouse中,避免了在开始时初始化太多的问题,简单来说就是执行三步:
- 根据路径path获取目标注解的RouteMeta,如果未获取则根据group去查询当前组编译生成的类文件
- 反射调用类文件的loadInto()加载所有注解信息到Warehouse.routes中
- 初始化Warehouse.routes后,再次加载查询RouteMeta信息并设置跳转的PostCard
到这里我们先提出第一个疑问:
- Warehouse.groupsIndex中的数据是在什么时候加载的?从哪加载的?
- _navigation(context, postcard, requestCode, callback):最终完成Activity的启动
private Object _navigation(final Context context, final Postcard postcard, final int requestCode, final NavigationCallback callback) {
final Context currentContext = null == context ? mContext : context;
switch (postcard.getType()) {
case ACTIVITY: //如果PostCard的目的是Activity,使用Intent启动Activity
final Intent intent = new Intent(currentContext, postcard.getDestination());
intent.putExtras(postcard.getExtras());
int flags = postcard.getFlags();
if (-1 != flags) {
intent.setFlags(flags);
} else if (!(currentContext instanceof Activity)) { // Non activity, need less one flag.
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
}
String action = postcard.getAction();
if (!TextUtils.isEmpty(action)) {
intent.setAction(action);
}
runInMainThread(new Runnable() {
@Override
public void run() {
startActivity(requestCode, currentContext, intent, postcard, callback);
}
});
break;
}
return null;
}从_navogation()执行中看出,Activity的启动过程和平时使用的一样,最终也是创建Intent,执行startActivity()完成的,到这里整个执行的流程就结束了,所执行的步骤和逻辑也很容易理解;
3.2、ARouter的初始化
在上面分析的过程中,我们提出了一个疑问就是Warehouse.groupsIndex的初始化问题,上面查看Warehouse类中知道Warehouse.groupsIndex保存的是group对应的生成类,现在看看Arouter的初始化;
- 初始化使用
ARouter.init(this)- 初始化流程
//调用init()方法初始化
public static void init(Application application) {
if (!hasInit) {//设置标志确保只会初始化一次
hasInit = _ARouter.init(application);//桥接模式调用_ARouter.init()
if (hasInit) {
_ARouter.afterInit();
}
}
}
//_ARouter.init()
protected static synchronized boolean init(Application application) {
LogisticsCenter.init(mContext, executor);//真正执行初始化的地方
hasInit = true;
return true;
}ARouter初始化和执行逻辑一样,都是桥接模式直接交给_ARouter处理,在ARouter方法中使用了LogisticsCenter.init()方法,所以初始化的所有过程都是在LogisticsCenter.init()中完成的;
- LogisticsCenter.init(mContext, executor)
public static final String ROUTE_ROOT_PAKCAGE="com.alibaba.android.arouter.routes";
public synchronized static void init(Context context, ThreadPoolExecutor tpe) throws HandlerException {
try {Set routerMap;
routerMap = ClassUtils.getFileNameByPackageName(mContext, ROUTE_ROOT_PAKCAGE);
//扫描指定包下面的所有ClassName
for (String className : routerMap) {//遍历HashSet反射加载配置文件
if (className.startsWith(ROUTE_ROOT_PAKCAGE + DOT + SDK_NAME + SEPARATOR + SUFFIX_ROOT)) {
//如果是Root就调用loadInto,将IRouteGroup类加载到Warehouse.groupsIndex中,这里采用按需加载先只加载到group
((IRouteRoot) (Class.forName(className).getConstructor().newInstance())).loadInto(Warehouse.groupsIndex);
} else if (className.startsWith(ROUTE_ROOT_PAKCAGE + DOT + SDK_NAME + SEPARATOR + SUFFIX_INTERCEPTORS)) {
//如果是Intercept,将IInterceptorGroup类添加到Warehouse.interceptorsIndex中
((IInterceptorGroup) (Class.forName(className).getConstructor().newInstance())).loadInto(Warehouse.interceptorsIndex);
} else if (className.startsWith(ROUTE_ROOT_PAKCAGE + DOT + SDK_NAME + SEPARATOR + SUFFIX_PROVIDERS)) {
//如果是Provider,将IInterceptorGroup类添加到Warehouse.providersIndex中
((IProviderGroup) (Class.forName(className).getConstructor().newInstance())).loadInto(Warehouse.providersIndex);
}
}
} catch (Exception e) {
throw new HandlerException(TAG + "ARouter init logistics center exception! [" + e.getMessage() + "]");
}
} 上面执行的代码注释很清楚,执行方法如下:
- 首先扫面com.alibaba.android.arouter.routes包下的所有文件,并将信息保存在routerMap中
- 遍历routerMap()中所有保存的所有类
- 根据className使用反射分别调用alibaba包下的loadInto()方法,将生成的IRouteRoot文件中每个组对应的文件保存在Warehouse.groupsIndex中,IInterceptorGroup和IProviderGroup的加载方式也一样
在(Class.forName(className).getConstructor().newInstance())).loadInto(Warehouse.groupsIndex)的参数中看到了Warehouse.groupsIndex,点击类中方法查看:
//rootApp 保存app组对应的ARouter$$Group$$app类
public class ARouter$$Root$$app implements IRouteRoot {
@Override
public void loadInto(Map> routes) {
routes.put("app", ARouter$$Group$$app.class);
}
} loadInto()是把方法中的数据保存到传入的参数中,到这里上面提的第一个疑问也解释清楚了,Warehouse.groupsIndex的加载过程是在初始化的时候执行的,现在我们在回头总结一下真个ARouter的整个执行流程:
- 在ARouter初始化时,调用init()反射获取alibaba包下的所有类,并调用类中的loadInto()将信息保存在Warehouse中
- 调用ARouter.getInstance().build("/login/activity”)方法,传入路径path
- 调用_ARouter的build()根据传入的path、group创建Postcard实例
- 调用_ARouter的navigation()方法发送导航请求,根据path、group从Warehouse中获取保存信息的RouteMeta
- 调用_navigation()方法,根据PostCard的目标Type创建或启动目标
这里提出两个疑问:
- ARouter$ $Root$ $app 是如何产生的?
- IRouteRoot是什么?为什么实现它?(答案其实已经体现)
4、ARouter源码架构和实现
上面ARouter的初始化和工作过程都介绍完毕,知道了整个ARouter的工作流程,但却有几个疑问:
- @Route、@Autowired、@Interceptor注解如何起作用?如何和Activity等绑定在一起?
带着这几个问题,也带着对编写框架的期待,一起分析ARouter组件框架的编写,源码分为arouter-annotation、arouter-api、arouter-compiler三部分,下面依次看看每个部分的功能和实现:
4.1、annotation:声明ARouter使用的Route、Autowired、Interceptor注解(本文分析以Route为例)
- Route注解:标记项目中Activity、IProvider的路由路径,在使用时按照路径导航加载对应的界面
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.CLASS)
public @interface Route {
String path(); // 声明路由地址
String group() default “"; // 声明路由组
String name() default “”; // 声明名称
int extras() default Integer.MIN_VALUE;
int priority() default -1; // 声明路由等级
}4.2、arouter-compiler
implementation 'com.google.auto.service:auto-service:1.0-rc3'
implementation 'com.squareup:javapoet:1.8.0'看到上面的引入就知道,ARouter框架使用APT和javapoet技术,根据注解自动生成代码,我们常用的框架中很多都有这个技术的身影,关于这两点点击以下连接查看:
- Java反射、注解
- Java注解代码生成
以Route注解生成为例,由上面的例子知道Route注解最后生成了RouterApp和GroupApp两个类,具体代码如下:
//groupApp 保存路径path对应的RouteMeta信息
public class ARouter$$Group$$app implements IRouteGroup {
@Override
public void loadInto(Map atlas) {
atlas.put("/app/webActivity", RouteMeta.build(RouteType.ACTIVITY, WebActivity.class, "/app/webactivity", "app", new java.util.HashMap(){{put("url", 8); }}, -1, -2147483648));
}
} 这里提出第四个疑问:IRouteGroup是什么?为什么也实现它?
Route生成两个类的过程
连接APT技术的都知道,框架编写的主要内容就在process(Set annotations, RoundEnvironment roundEnv)中,它生成类文件的所有代码,ARouter的process中直接调用了parseRoutes()进行代码编写:
- parseRoutes(Set routeElements)
//创建Group类中方法的参数类型:Map
ParameterizedTypeName inputMapTypeOfGroup = ParameterizedTypeName.get(
ClassName.get(Map.class),
ClassName.get(String.class),
ClassName.get(RouteMeta.class)
);
//创建loadInto方法中的参数名称
ParameterSpec groupParamSpec = ParameterSpec.builder(inputMapTypeOfGroup, "atlas").build();
//创建loadInto方法
MethodSpec.Builder loadIntoMethodOfRootBuilder = MethodSpec.methodBuilder(METHOD_LOAD_INTO)
.addAnnotation(Override.class)
.addModifiers(PUBLIC)
.addParameter(rootParamSpec);
上面代码在APT在编写的框架中很常见,代码也只做了一件事:创建生成类文件中的loadInto()方法;
- 循环解析所有的注解类:获取每个注解的信息保存到Route实例中
//循环遍历所有注解
for (Element element : routeElements) {
TypeMirror tm = element.asType(); //获取注解类型
Route route = element.getAnnotation(Route.class); //获取注解的Route.class
if (types.isSubtype(tm, type_Activity)) { //根据注解类型分别处理,已Activity为例
routeMeta = new RouteMeta(route, element, RouteType.ACTIVITY, paramsType);//创建 RouteMeta保存属性值和属性信息
categories(routeMete) //解析保存所有信息的routeMeta
}
}- categories(RouteMeta routeMete):将RouteMeta实例保存到groupMap中
//1、将每个创建的RouteMeta保存在 Set中,然后将Set以group为健保存在groupMap中
private void categories(RouteMeta routeMete) {
if (routeVerify(routeMete)) {
Set routeMetas = groupMap.get(routeMete.getGroup());//判断是否保存过次Group组
if (CollectionUtils.isEmpty(routeMetas)) {
Set routeMetaSet = new TreeSet<>(new Comparator() {......});
routeMetaSet.add(routeMete); //将routeMete添加到结合routeMetaSet中
groupMap.put(routeMete.getGroup(), routeMetaSet);//将routeMetaSet使用group为键存储到groupMap中
} else {
routeMetas.add(routeMete);
}
} else {
}
} 上面执行代码见注释,简单来说就是将相同group组注解的信息保存在Set中,然后以group为键将set集合保存到groupMap中,现在所有的注解信息都存储在groupMap中,接下来你应该想到了就是遍历groupMap,生成方法中对应的代码语句,那下面接着看parseRoutes()源码:
//遍历groupMap,将其中的每个group组添加初始化代码
for (Map.Entry> entry : groupMap.entrySet()) {
String groupName = entry.getKey();
//循环遍历group对应的每个Set中保存的元素,为每个元素添加一行加载的代码
Set groupData = entry.getValue();
for (RouteMeta routeMeta : groupData) {
。。。。。。
loadIntoMethodOfGroupBuilder.addStatement(
"atlas.put($S, $T.build($T." + routeMeta.getType() + ", $T.class, $S, $S, " + (StringUtils.isEmpty(mapBody) ? null : ("new java.util.HashMap(){{" + mapBodyBuilder.toString() + "}}")) + ", " + routeMeta.getPriority() + ", " + routeMeta.getExtra() + "))",
routeMeta.getPath(),
routeMetaCn,
routeTypeCn,
className,
routeMeta.getPath().toLowerCase(),
routeMeta.getGroup().toLowerCase());
}
//保存每个group和对应的文件名
String groupFileName = NAME_OF_GROUP + groupName;
rootMap.put(groupName, groupFileName); //rootMap保存每个组对应生成的文件类名
}
//遍历rootMap在root类中的loadInto()方法中添加每个组的执行语句
if (MapUtils.isNotEmpty(rootMap)) {
for (Map.Entry entry : rootMap.entrySet()) {
//添加每个group对应loadInto()方法中的代码 routes.put("app", ARouter$$Group$$app.class);
loadIntoMethodOfRootBuilder.addStatement("routes.put($S, $T.class)", entry.getKey(), ClassName.get(PACKAGE_OF_GENERATE_FILE, entry.getValue()));//保存每个Group组类
}
} 上面的代码是从源码中抽取出来的部分主要代码,短短的代码中出现了三个for循环,这里每个循环就是在添加代码语句:
- 第一个循环从groupMap中获取每个group组对应的Set集合
- 从Set集合中遍历每个RouteMeta,并创建loadInto()方法中的语句,并将每个group生成的类保存在rootMap中
- 遍历root Map中的元素,添加Root类的loadInto()方法中的语句
到这里我们按照了解一个框架的顺序,分析了整个框架的编写和执行过程,上面所提出的第二个问题也找到了答案,这里总结一下:
- 在使用时为目标的Activity添加@Route注解
- 编译时使用APT根据注解信息生成Root和Group类及其中的方法体
- 在初始化时反射将root类中的所有group信息,加载到Warehouse中
- 在使用navigation中导航时,从Warehouse中加载并获取注解信息
- 从注解信息中获取目标Activity,从而调用startActivity实现界面跳转
5、深入框架细节
上面从整体的角度了解了框架的源码和执行,这个过程对于你了解、使用和学习框架来说至关重要,相信走到这一步的人很多,但相信停在这一步的更多;到此已经可以说你熟悉或掌握了这个框架的原理,但学习去没有结束,如果想真正成为开发框架的人,可能更重要的两步是:细节和总结;
5.1、拦截器
- 拦截器源码生成
for (Element element : elements) {
if (verify(element)) {
Interceptor interceptor = element.getAnnotation(Interceptor.class);
Element lastInterceptor = interceptors.get(interceptor.priority());
if (null != lastInterceptor) {
throw new IllegalArgumentException( //这里当两个拦截起设置相同的优先级时回触发异常(在哪理按照优先级运算?)
String.format(Locale.getDefault(), "More than one interceptors use same priority [%d], They are [%s] and [%s].",
interceptor.priority(),
lastInterceptor.getSimpleName(),
element.getSimpleName())
);
}
interceptors.put(interceptor.priority(), element); //保存数据
}
}拦截起源码的生成和上面Root、Group的流程一样,保存每个拦截器的注解,然后编译生成类文件,值得注意的是拦截器的优先级不能相同否则抛出异常,因为保存注解的键就是设置的优先级;
- 拦截器的初始化:在ARouter初始化时将所有的信息保存在Warehouse.interceptorsIndex中,然后遍历初始化所有的拦截器并缓存在Warehouse.interceptors中
IInterceptor iInterceptor = interceptorClass.getConstructor().newInstance();
iInterceptor.init(context); //初始化每个IInterceptor
Warehouse.interceptors.add(iInterceptor);- 拦截器执行
CancelableCountDownLatch interceptorCounter = new CancelableCountDownLatch(Warehouse.interceptors.size());
interceptorCounter.await(postcard.getTimeout(), TimeUnit.SECONDS);//调用锁锁住当前线程
if (index < Warehouse.interceptors.size()) {
IInterceptor iInterceptor = Warehouse.interceptors.get(index);
iInterceptor.process(postcard, new InterceptorCallback() {//执行每个线程的process()
@Override
public void onContinue(Postcard postcard) {
counter.countDown(); //调用锁 -1
_excute(index + 1, counter, postcard); //循环递归调用
}
@Override
public void onInterrupt(Throwable exception) {
postcard.setTag(null == exception ? new HandlerException("No message.") : exception.getMessage());
counter.cancel();//拦截事件
}
});
}使用CountDownLatch锁住当前线程,然后使用线程池递归执行所有拦截器的process()方法,当所有拦截器执行完毕后继续执行调用线程;
5.2、Autowired参数解析
在使用使用方法提到ARouter携带参数跳转时,只需要在目标Activity的属性中添加@Autowired注解,即可实现属性的自动赋值,在源码中关于@Autowired的注解编译过程和@Route一样,具体细节在源码中查看,这里直接给出生成的类:
public class WebActivity$$ARouter$$Autowired implements ISyringe {
private SerializationService serializationService;
@Override
public void inject(Object target) {
serializationService = ARouter.getInstance().navigation(SerializationService.class);
WebActivity substitute = (WebActivity)target;
substitute.url = substitute.getIntent().getStringExtra("url”); //调用getIntent()为属性负值
}
}从类中的inject()直接看出数据的赋值也是使用getIntent()实现的,那么此方法在何时被调用的呢?其实在使用指南中介绍,使用参数注解时要在onCreate中添加:ARouter.getInstance().inject(this);正是这个初始化了数据的复制;在_ARouter.inject()中直接调用了AutowiredService的实现类:
static void inject(Object thiz) {
AutowiredService autowiredService = ((AutowiredService) ARouter.getInstance().build("/arouter/service/autowired").navigation());
if (null != autowiredService) {
autowiredService.autowire(thiz);//调用autowire方法
}
}看到这是不是感觉有点意思,在框架中就使用框架!作者的设计巧妙啊!下面根据路径找到实现类的autowire方法:
String className = instance.getClass().getName(); //获取当前类名
ISyringe autowiredHelper = classCache.get(className); //判断缓存是否含有
if (null == autowiredHelper) {
autowiredHelper = (ISyringe) Class.forName(instance.getClass().getName() + SUFFIX_AUTOWIRED).getConstructor().newInstance();//按照规则生成编译文件名,并反射创建实例}
autowiredHelper.inject(instance); //调用inject()传入Activity实例
classCache.put(className, autowiredHelper); //缓存反射的实例
autowire方法根据传入的Activity,获取生成的文件类,反射调用其中的inject()进行数据的赋值,这个有没有给你点启发呢?有没有想到ButterKnife呢?
5.3、PathReplaceService
PathReplaceService用于在程序执行过程中动态的修改路由或实现重定向功能,它的使用也很简单直接实现PathReplaceService接口重写其中方法即可,其实在_ARouter.build()方法有几句代码上面没有贴出,首先会使用路由获取实现接口的子类,调用其中方法修改传递的path,后面所有的过程都是在新的路径上执行:
PathReplaceService pService = ARouter.getInstance().navigation(PathReplaceService.class);
if (null != pService) {
path = pService.forString(path);
}5.4、DegradeService
在路由执行过程中,可能会因为路由地址错误而找不到目标,从而引起整个跳转的失败,如果我们想所有的失败都显示固定的界面,此时就可以使用DegradeService实现页面的降级问题,其实也是一种完全意义的重定向:
try {
LogisticsCenter.completion(postcard);
} catch (NoRouteFoundException ex) {
if (null != callback) {
callback.onLost(postcard); //如果设置回调调用回调方法
} else {
DegradeService degradeService = ARouter.getInstance().navigation(DegradeService.class); //获取设置的重定向实例
if (null != degradeService) {
degradeService.onLost(context, postcard); // 调用重定向的方法
}
}
return null;
}在调用navigation()时,如果没有找到Route注解对应的类,则会抛出异常,捕获到异常后执行两个选择:
- 如果设置跳转监听,则会掉callback.onLost()
- 如果未设置回调,使用路由获取DegradeService的实现并调用onLost()重新执行跳转
6、总结收获
分析完整个源码执行和编写后,有没有自己的收获和心得呢?如果让你来写或者以后会遇到同样的需求是否能实现同样的功能呢?哪些细节实现值得我们借鉴呢?下面我们就总结一下本篇源码的收获与思考,细节都在源码当中这里只列出几点:
- 如何使用APT和javapoet技术编写源码
- 相信很多人都已经掌握此项技术,上面的连接也提供学习内容
- 如何扫描指定包下的文件
- 生成的类属于不同的包和类,如何集中管理他们?如何初始化?(本条也是回答上面的问题)
- 答案就是分别实现了IRouteGroup或IRouteRoot接口,这样所有的生成类就都是接口的实现类
- 初始化时只需根据类名反射获取接口实例,反射调用方法即可
- 如何避免初始化问题?
- 采用按需加载的方式,避免初始化过于繁重;ARouter执行如下:
- 这里将每个group组的所有路由信息保存在一个类中,比如类A、B、C分别对应3个组
- 将group生成的类A、B、C,分别以键值对形式保存在Map中
- 当第一次使用某个group时,找到Map中保存的类,调用类中方法缓存同组的数据
- 拦截器处理
- 使用CountDownLatch阻塞调用线程,然后递归调用所有的拦截器方法,最后唤醒线程
- 此处有没有想到okhttp的拦截器呢?它是如何让实现呢?
- 重定向和降级
- 这里使用实现接口的方式,通过路由获取实例,在程序执行时统一管理,是不是有点类似AOP?如果使用AOP如何实现呢?
相信每一篇源码中都会有很多优秀的细节,如果我们能一点点积累起来,相信一定能更快的提升自己,这是笔者重新审视源码学习的第一篇,后面有时间会针对过去学过的开源框架,从不同的角度对比分析细节的实现,希望可以提高自己开发框架的能力!