PyTorch1.0搭建卷积神经网络实现MNIST手写数字识别
还是把所有代码放在三个.py文件里:
- net.py用来定义卷积网络
- readpic.py用来读取自己手动画的一张图片,测试着玩
- CNN.py就是代码的主体部分
net.py
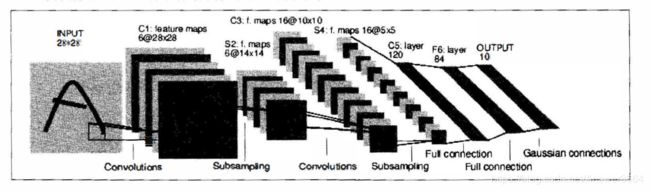
这里使用的是LeNet,LeNet是整个神经网络的开山之作,1998年由LeCun提出,它的结构特别简单。
import torch
import torch.nn as nn
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 6, 3, padding=1), # 6@28*28
nn.MaxPool2d(2, 2) # 6@14*14
)
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, 5), # 16@10*10
nn.MaxPool2d(2, 2) # 16@5*5
)
self.layer3 = nn.Sequential(
nn.Linear(400, 120), # 16*5*5=400
nn.Linear(120, 84),
nn.Linear(84, 10)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.size(0), -1)
x = self.layer3(x)
return xreadpic.py
实现对图片的读取和show
from PIL import Image
import matplotlib.pyplot as plt
from torchvision import datasets, transforms
def readImage(path='./3.jpg', size=28):
mode = Image.open(path).convert('L') # 转换成灰度图
transform1 = transforms.Compose([
transforms.Resize(size),
transforms.CenterCrop((size, size)), # 切割
transforms.ToTensor()
])
mode = transform1(mode)
return mode
def showTorchImage(image):
mode = transforms.ToPILImage()(image)
plt.imshow(mode)
plt.show()CNN.py
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import net # 自定义的网络模块
import readpic # 读自己手写的图片
# hyperparameters
batch_size = 128
learning_rate = 1e-2
num_epoches = 5
# 标准化
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])]
)
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_tf, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_tf)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
model = net.LeNet()
if torch.cuda.is_available():
model = model.cuda()
# 定义loss函数和优化方法
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(num_epoches):
model.train()
for data in train_loader: # 每次取一个batch_size张图片
img, label = data # img.size:128*1*28*28
# img = img.view(img.size(0), -1) # 展开成128 *784(28*28)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
output = model(img)
loss = loss_fn(output, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print('epoch:', epoch, '|loss:', loss.item())
# 在测试集上检验效果
model.eval() # 将模型改为测试模式
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
out = model(img)
loss = loss_fn(out, label)
# print(label.size(0))
eval_loss += loss.item() * label.size(0) # lable.size(0)=128
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Epoch:{}, Test loss:{:.6f}, Acc:{:.6f}'.format(epoch, eval_loss/(len(test_dataset)), eval_acc/(len(test_dataset))))
网络训练之后,下面是我用画图写了一个数字,把这个图片放在相同目录下,然后识别看看效果:

figure = readpic.readImage(path='./3.png', size=28) # figure dim=[1, 28, 28]
figure = figure.unsqueeze(0) # figure dim = [1, 1, 28, 28]
figure = figure.cuda()
y_pred = model(figure)
_, pred = torch.max(y_pred, 1)
print('prediction = ', pred.item())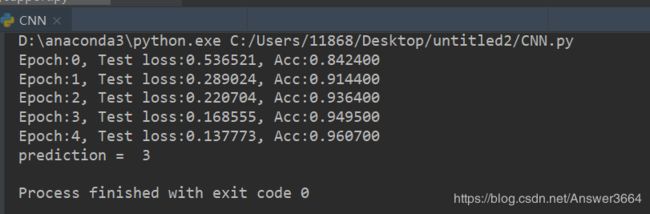
训练了5次,识别效果还可以。源码还是放在GitHub
遇到的问题:

读取图片是3维的[1,28,28],但是CNN应该输入4维,所以应该插入一维。
figure = figure.unsqueeze(0) # figure dim = [1, 1, 28, 28][1, 1, 28, 28]:一张图片,一个通道,长宽是28*28