8086汇编学习之寻址方式、数据类型以及几个数据操作指令
(一)、8086汇编学习之基础知识、通用寄存器、CS/IP寄存器与Debug的使用
(二)、8086汇编学习之DS寄存器、SS/SP寄存器
(三)、8086汇编学习之[BX],CX寄存器与loop指令,ES寄存器等
(四)、8086汇编学习之代码段、数据段、栈段与段地址寄存器
一、and、or指令与应用:
1、描述:
and指令:按位与
or指令:按位或
and register value
or register value
其按位操作关系与C、C++等是一样的,无需赘言。
eg:
mov al,01011010B ;AL=01011010B=5AH
mov ah,01011010B ;AH=01011010B=5AH
and al,10100101B ;10100101B=A5H AL = A5H & 5AH = 0H
or ah,10100101B ;10100101B=A5H AH = A5H | 5AH = FFH2、应用:
如何将程序中的数据段的前26个字母中的大写字母全部变成小写字母,将后26个字母中的小写字母变成大写字母。
我们知道几个重要的ASCII值与对应字符:
0 30H 0011 0000 48
1 31H 0011 0001 49
A 41H 0100 0001 65
a 61H 0110 0001 97 ;小写a比大写A权重为5的位多了一个1,即多了2^5=32=20H大写字母与小写字母一一对应,相差61H-41H = 20H = 32,大写向小写转换加个32,小写向大写转换减个32,但是需要区分是否是大小写。我们要使用and和or指令就不能使用这种方式了。我们可以采用如下方式:
小写->大写:and value,1101 1011B 或者 and value,DFH
大写->小写:or value,0010 0000B 或者 or value,20H
那么只要我们对前26个字符每个都或一个20H(相当于对小写字母加上一个20H,但大写字母本来就有按位或的结果还是不变),后26个字母均与一个DFH。
eg:
A->a(41H->61H):or 41H,20H == 0100 0001B | 0010 0000B == 0110 0001B = 61H(大写变小写)
b->b(62H->62H):or 62H,20H == 0110 0010B | 0010 0000B == 0110 0010B = 62H(小写依旧是原值)
a->A(61H->41H):and 61H,DFH == 0110 0001B & 1101 1111B == 0100 0001B = 41H(小写变大写)
B->B(42H->42H):and 42H,DFH == 0100 0010B & 1101 1111B == 0100 0010B = 42H(大写依旧是原值)测试代码:
assume cs:code,ds:data
data segment
db 'AbCdEfGhIjKlMnOpQrStUvWxYz' ;大写变小写
db 'aBcDeFgHiJkLmNoPqRsTuVwXyZ' ;小写变大写
data ends
code segment
start:
mov ax,data
mov ds,ax
mov bx,0
mov cx,26
BigToLittle:
mov al,20H
or ds:[bx],al
inc bx
loop BigToLittle
mov cx,26
LittleToBig:
mov al,0DFH
and ds:[bx],al
inc bx
loop LittleToBig
mov ax,4C00H
int 21H
code ends
end start上面的程序可以优化一下(合并两个循环):
code segment
start:
mov ax,data
mov ds,ax
mov bx,0
mov cx,26
BTL_LTB:
;关于下面的ds:idata[bx]的写法我们之后会提到
mov al,20H
or ds:0[bx],al
mov al,0DFH
and ds:26[bx],al
inc bx
loop BTL_LTB
mov ax,4C00H
int 21H
code ends
end start测试结果:
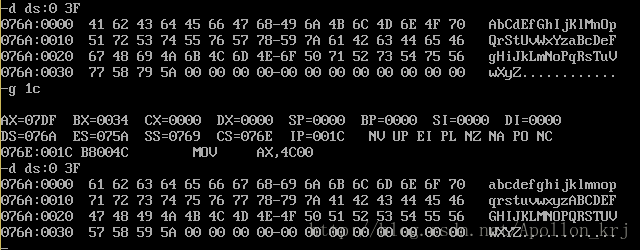
二、数据类型:
1、bx、bp与si、di寄存器:
BX、BP、DI、SI可以出现在[…]进行偏移地址寻址。其它寄存器不能放到[]中去
而这四个寄存器的组合也只有四种:
第一种:bx与si组合:[bx+si+idata] == [bx][si].idata == [bx].idata[si] == idata[bx][si]
第二种:bx与di组合:[bx+si+idata] == [bx][di].idata == [bx].idata[di] == idata[bx][di]
第三种:bp与si组合:[bp+si+idata] == [bp][si].idata == [bp].idata[si] == idata[bp][si]
第四种:bp与di组合:[bp+di+idata] == [bp][di].idata == [bp].idata[di] == idata[bp][di]
也就是说bx和bp不能同时出现在[]中,并且si和di也不能同时出现在[]中
以上16个写法三个值位置可以相互调换,但是要注意的是:
[bx].[si].[3]、[bx].3[si]、[si].[bx].3等都是正确的
[bx].si.3、si[bx].3、bx[si].3等都是错误的
因为寄存器要加[],这似乎是没有必要强调的,凡是寄存器要加[],数字可加可不加(数字皆不加,形成一种规则)。
默认段地址问题:
当段地址没有给出时:
当[]中用的是BX时,默认的是DS寄存器存储段地址
当[]中用的是BP时,默认的是SS寄存器存储段地址
当[]中既没有BX也没有BP时默认的是DS寄存器存储段地址
指定段地址寄存器,则按指定走,不指定则按默认走(bx->ds,bp->ss)
eg:
[bx][si].3 : ((ds*16)+bx+si+3)
[bp][di].5 : ((ss*16)+bp+di+5)
ss:[bx][si].3 : ((ss*16)+bx+si+3)
es:[bx][si].3 : ((es*16)+bx+si+3)
ds:[bp][di].5 : ((ds*16)+bp+di+5)关于这些写法,上面说and与or指令的时候就简单用过了。我们再用一个例子看来检验一下and指令、cx寄存器、栈段、bx、si等的混合使用,题目与代码如下:
;Question:修改每个单词的前4个字母为大写
assume cs:codeseg,ds:dataseg,ss:stackseg
dataseg segment
db '1. display ' ;16个字符
db '2. brows '
db '3. replace '
db '4. modify '
dataseg ends
stackseg segment
dw 0,0,0,0,0,0,0,0
;栈用来存储临时性变量,保存临时变量可以用寄存器、普通内存、栈,但是寄存器有限,普通空间需要记住地址,而栈不需要所以用栈存储临时变量更为优秀
stackseg ends
codeseg segment
start:
mov ax,dataseg
mov ds,ax
mov ax,stackseg
mov ss,ax
mov sp,16
mov cx,4 ;四行数据循环四次
mov bx,0
mov al,0DFH ;变大写,为减32即与0DFH
change_one:
push cx ;用栈暂存外层循环的循环次数,腾挪CX空间以备内层循环使用
mov cx,4 ;修改每行单词的前四个,也是循环四次
mov si,0
change_two:
and [bx][si+3],al
;[bx].3[si]更清晰:[bx]表示第(bx)/16+1行,3表示第(bx)/16+1行,偏移3+1的位置开始算起,[si]表示相对于3的偏移量
inc si
loop change_two
pop cx ;将外层循环的次数移动到CX中,回到外层循环自减
add bx,16
loop change_one
mov ax,4C00H
int 21H
codeseg ends
end start测试结果:

在举个例子说明一下[bx].idata[si]:
struct Class{
int sex;
int age;
char name[20];
};
//对于C语言:
struct Class stu;
stu.name[7]='?' ;//mov byte ptr [bx].idata[si],'?'类似于结构体中取数组成员,再对数组偏移。
//对于汇编:
[bx]/[bp]:定位结构体
idata:定位结构体中某一数据项
[si]/[di]:来访问数据项中的某个元素2、数据表示形式:
(1)、db、dw、dd、dup:
db:define byte,定义字节型数据(1Byte)
dw:define word,定义字型数据(2Byte)
dd:define double word,定义双字型数据(4Byte)
dup:复制n份数据,eg:db 4 dup (‘abcd’) <==> db ‘abcdabcdabcdabcd’定义四个相同的内容
我们要定义256个字节的空间时,不能像“db 0,0,0,0,…”那样写256个0,即使是“dd 0,0,0,0…”那样写256/4=64个0也十分麻烦,而采用“db 256 dup 0就显得十分简单方便。
(2)、地址单元类型指定:
我们可以用ax、al指定不同类型数据,ax指定字型16位,al指定字节型8位,但是如果一条指令中不存在ax/al/ah/等寄存器,而是用段地址加偏移地址,如何指定一个地址单元是字型还是字节型?格式:”操作符(指令)+X+ptr”指明单元长度是X(word/byte)类型的:
eg:
mov ax,1 //word
add bl,1 //byte
mov word ptr ds:[0],1 //word型数据1存放到ds:[0]、ds:[1]的地址单元(字型单元)
mov byte ptr es:[1],2 //byte型数据2存放到es:[0]的地址单元(字节型单元)只要牵扯到数据类型(byte、word)的就可以进行类似的声明式指定存放数据的类型。在没有寄存器参与的内存单元访问中,用word ptr/byte ptr显性声明某单元是字节型还是字型的。但是要注意:push、pop指令操作(且只能操作)的是字型单元,不能人为指定。
(3)、div除法指令:
div指令或许是我们至今遇到的最为复杂的指令,因为其牵扯到不同的数据类型,以及两个寄存器AX和DX。
规则描述:
对于除法有除数、被除数、商、余数四个值,那么这四个值是如何存储的呢?有两种形式:
当被除数比较大时,一般一个寄存器放不下放在两个寄存器中(不排除一个寄存器能放下但仍放在两个寄存器中(AX和DX中)的情况)。
①:当被除数放在两个寄存器中时,DX存高16位,AX存低16位(首先得转换成十六进制才方便分解成高低不分)。在此种情况下(被除数为32位的情况),除数只能是16位的,计算的结果,商会被放到AX寄存器中,余数被放到DX寄存器中。
②:当被除数占16位时(放在AX中),除数只能为8位。最终商放在AL中,余数放在AH中。
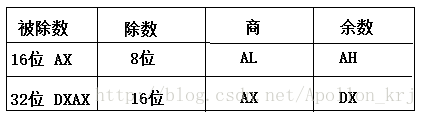
div 除数指定除数位置(寄存器/内存)以及类型(寄存器8/16位,内存byte/word型)后,CPU自己去DX和AX寄存器中读取被除数,将计算结果放在AX/DX或AL/AH中。
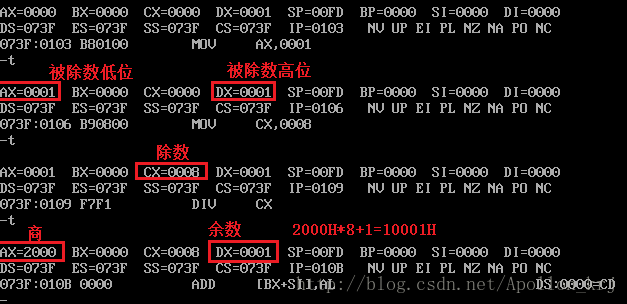
测试:
;运行前后查看dx与ax的值
;65537大于16位,要放到两个寄存器中65537=1 0001H
mov dx,1H
mov ax,1H
mov cx,8
div cx
;258H放在16位寄存器中足矣
mov ax,258H
mov cx,8
div cx测试结果如下:

上面是除数在寄存器中的情况,如果除数不在寄存器中,而在内存中就需要指定除数类型:
eg:
mov dx,1H
mov ax,1H
mov word ptr ds:[bx][si].idata,8
div word ptr ds:[bx][si].idata
;等效于:
;商:(AX)=((DX)*10000H + (AX)) / ((ds)*16 + (bx) + (si) + idata)
;余数:(DX)=((DX)*10000H + (AX)) % ((ds)*16 + (bx) + (si) + idata)
mov ax,258H
mov byte ptr ds:[bx][si].idata
div byte ptr ds:[bx][si].idata
;等效于:
;商:(AL)=((AX) / ((ds)*16 + (bx) + (si) + idata)
;余数:(AH)=(AX) % ((ds)*16 + (bx) + (si) + idata)测试时先在div之前查看ds:[bx][si].idata的值和寄存器的值,在执行div指令之后查看寄存器的值,这里就不再测试了。
三、综合应用:
题目:王爽《汇编语言·第三版》实验七-P172
;将data中分开的:年份、公司收入、员工人数按照先后顺序写入table表段
;年份(4B)+(空格1B)+收入(4B)+(空格1B)+员工人数(2B)+(空格1B)+平均工资(2B)+(空格1B)
;总共16B即在Debug中一年的信息记录,占一行,21年共占21行
;员工平均工资=收入/员工人数(取整)
assume cs:codeseg
data segment
;年份:0~84
db '1975','1976','1977','1978','1979','1980','1981'
db '1982','1983','1984','1985','1986','1987','1988'
db '1989','1990','1991','1992','1993','1994','1995'
;公司收入:84~168
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514,345980
dd 590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;员工人数:168~210
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793
dw 4037,5635,8226,11542,14430,15257,17800
data ends
table segment
db 21 dup ('year summ ne ?? ')
table ends
codeseg segment
start:
mov ax,data
mov ds,ax
mov ax,table
mov es,ax
mov bx,0
mov bp,0
mov cx,21
mov di,0
loop_one:
mov ax,cx
mov cx,2
mov si,0
loop_two:
mov dx,ds:[bp].0[si] ;年份复制,注意:要通过寄存器复制
mov es:[bx].0[si],dx
mov dx,ds:[bp].84[si] ;公司总收入复制
mov es:[bx].5[si],dx
add si,2
loop loop_two
mov cx,ax ;提前转回来,因为后面要用到ax
mov dx,ds:168[di]
mov es:[bx].10,dx;员工人数
mov dx,es:[bx].7 ;总收入的高16位
mov ax,es:[bx].5 ;总收入的低16位
div word ptr es:[bx].10 ;进行除法运算计算工资,word ptr指定被除数在AX与DX寄存器中
mov es:[bx].13,ax ;将商移动到最终平均工资的内存中
add di,2
add bp,4
add bx,16 ;bx自加进行下一年度运算
loop loop_one
mov ax,4C00H
int 21H
codeseg ends
end start上面程序的简单优化:
;用栈做
;并且将简单的循环去掉(该循环并没有减少太多代码,拆开即可)
;牵扯到中间转换的均可用压栈出栈代替
assume cs:codeseg
data segment
;年份:0~84
db '1975','1976','1977','1978','1979','1980','1981'
db '1982','1983','1984','1985','1986','1987','1988'
db '1989','1990','1991','1992','1993','1994','1995'
;公司收入:84~168
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514,345980
dd 590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;员工人数:168~210
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793
dw 4037,5635,8226,11542,14430,15257,17800
data ends
table segment
db 21 dup ('year summ ne ?? ')
table ends
stack segment
dd 0,0,0,0
stack ends
codeseg segment
start:
mov ax,data
mov ds,ax
mov ax,table
mov es,ax
mov ax,stack
mov ss,ax
mov sp,16
mov bx,0
mov bp,0
mov cx,21
mov di,0
loop_one:
push ds:[bp].0 ;年份复制,注意:要通过寄存器复制
pop es:[bx].0
push ds:[bp].2
pop es:[bx].2
mov dx,ds:[bp].86 ;公司总收入复制
mov ax,ds:[bp].84
mov es:[bx].5,ax ;总收入的低16位
mov es:[bx].7,dx ;总收入的高16位
push ds:168[di]
pop es:[bx].10;员工人数
div word ptr es:[bx].10 ;进行除法运算计算工资,word ptr指定被除数在AX与DX寄存器中
mov es:[bx].13,ax ;将商移动到最终平均工资的内存中
add di,2
add bp,4
add bx,16 ;bx自加进行下一年度运算
loop loop_one
mov ax,4C00H
int 21H
codeseg ends
end start内存与BX、BP、SI、DI寄存器的大致关系:

前三个数据是需要对应复制的,而第四个平均工资只需要div计算并用BX寄存器与SI寄存器定位并存储即可。