Solr 7.2.1 配置中文分词器 IK Analyzer
一、什么是中文分词器?
为什么不来个英文分词器呢?
“嘿,小伙子,就是你,说的就是你,你那么有才咋不上天呢!”
首先我们来拽一句英文:“He is my favorite NBA star”
然后我们再来一句中文:“他是我最喜欢的NBA球星”
从英文的结构我们很容易区分每个单词,因为,每个单词之间都是空格隔开的,你肯定不会这样写英文的吧
"HeismyfavoriteNBAstar",我去,你如果这么写,你要翻译软件如何是好

但是,中文就不一样了了,上一篇我们讲到solr的配置,我们知道solr是做搜索的,做搜索可不是全字符串匹配啊,而是关键字匹配,还拿这句中文来说
“他是我最喜欢的NBA球星”
针对这句话,我们把其拆分成多个我们已知的且具有实际意义的中文单词,每个单词之间空格隔开以示区分
比如,上面这句经过我们拆分后就成了
“他 是 我 最 最喜欢 喜欢 喜欢的 NBA球星 球 球星 星”
没毛病吧,比如“我最喜欢的”,就包含了多种单词组合,因为搜索不是全字匹配(再次强调一遍)因此,用户在搜索框中可能
只输入了一个 “星”字,就会搜索到整句话 -----> “他是我最喜欢的NBA球星”
当然,中国人对自家的中文是OK的,再比如
"门把手"这三个字,可以拆分为“门把手 门 把手 手”四个不同的词义
你要老外去拆,估计你会急死,如果,你换成让计算机去拆,什么?
“拆个毛线哟,没规律而言,你让我计算机干瞪眼吗???”
哈哈哈哈哈哈,于是,林先生(林良益)便开发了一款开源中文分词器的工具包IK Analyzer
注:林先生在2012年就停止了对IK Analyzer的维护和更新,不过,利用现有的网络资源下载下来的IK包,还是可以满足我们高版本的Solr的
中文分词器工具包下载(配置+Jar包)
二、什么是停用词(Stop Words)?
停用词(Stop Words) ,词典译为“电脑检索中的虚字、非检索用字”。在SEO中,为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词)。
停用词一定程度上相当于过滤词(Filter Words),不过过滤词的范围更大一些,包含黄色、政治等敏感信息的关键词都会被视做过滤词加以处理,停用词本身则没有这个限制。通常意义上,停用词(Stop Words)大致可分为如下两类:
停用词一定程度上相当于过滤词(Filter Words),不过过滤词的范围更大一些,包含黄色、政治等敏感信息的关键词都会被视做过滤词加以处理,停用词本身则没有这个限制。通常意义上,停用词(Stop Words)大致可分为如下两类:
1、使用十分广泛,甚至是过于频繁的一些单词。比如英文的“i”、“is”、“what”,中文的“我”、“就”之类词几乎在每个文档上均会出现,查询这样的词搜索引擎就无法保证能够给出真正相关的搜索结果,难于缩小搜索范围提高搜索结果的准确性,同时还会降低搜索的效率。因此,在真正的工作中,Google和百度等搜索引擎会忽略掉特定的常用词,在搜索的时候,如果我们使用了太多的停用词,也同样有可能无法得到非常精确的结果,甚至是可能大量毫不相关的搜索结果。
2、文本中出现频率很高,但实际意义又不大的词。这一类主要包括了语气助词、副词、介词、连词等,通常自身并无明确意义,只有将其放入一个完整的句子中才有一定作用的词语。如常见的“的”、“在”、“和”、“接着”之类,比如“SEO研究院是原创的SEO博客”这句话中的“是”、“的”就是两个停用词。
下载上面提供的中文分词器的资源,我们可以打开其中的stopword.dic文件进行查看

当然,这里面的内容你是可以进行修改的,如果不够你用,你甚至可以在扩展一个stopword.dic
我们再来看一下ext.dic分词器字典里面都藏了些什么(将原来的内容改为如下)
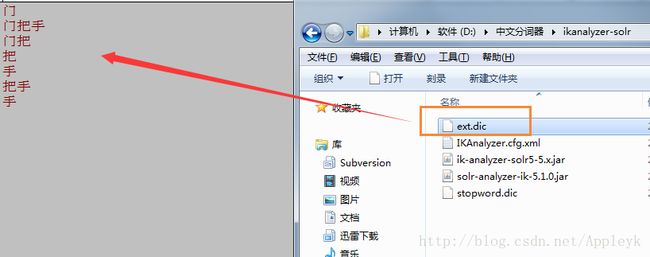
如果我们的ext.dic不够我们用了,或者我们想扩展其他词库,我们可以打开IKAnalyzer.cfg.xml进行配置
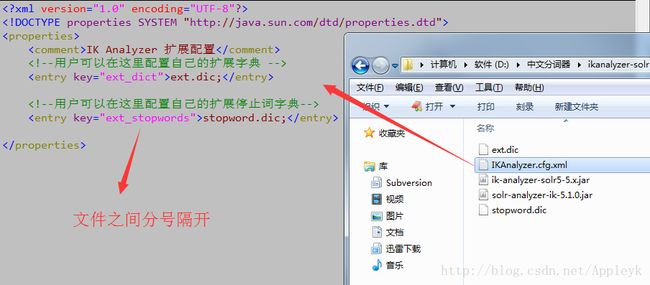
而剩下的那两个jar包,我们从名字上就知道,这是IK打通solr的“通道啊”

三、Solr配置IK Analyzer
(1)拷贝两个jar包至:
C:\tomcat-8\webapps\solr\WEB-INF\lib
文件夹下
(2)拷贝剩余三个资源文件至:
C:\tomcat-8\webapps\solr\WEB-INF\classes
文件夹下

(3)定位到目录:
D:\solr_home\newcore\conf
下 (%SOLR_HOME%)

修改managed-schema文件,在文件内容的最后添加IK分词filed,名称为“text_ik”(也可以自己定义)

四、重启tomcat,访问Solr,验证IK分词器
(1)

(2)有了text_ik,我们要怎么用呢?
我们先来看一下,stopword.dic是怎么影响中文分词的
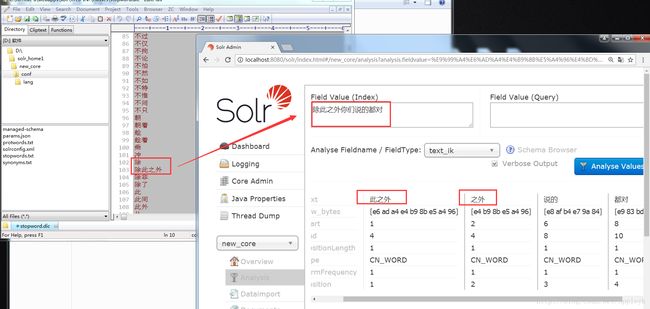
图中,我们看到,对于“除此之外你们说的都对”这句话,IK分词后的效果按理说应该是
"除此之外 此之外 之外" 而有了stopword停用词“除此之外”后,IK分析的结果就成了
“此之外 之外”
如果们把停用词从stopword.dic里面删除掉,重启tomcat后,再次访问solr,我们会发现

现在,我们来看一下ext.dic是怎么作用到中文语句上分词的
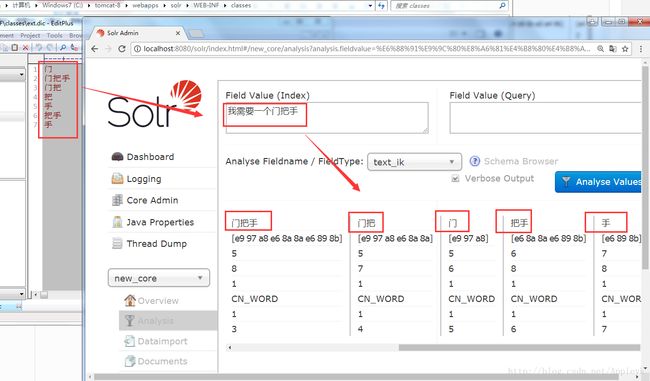
如果去掉ext.dic里面的部分内,重启tomcat,再次访问solr,会发现
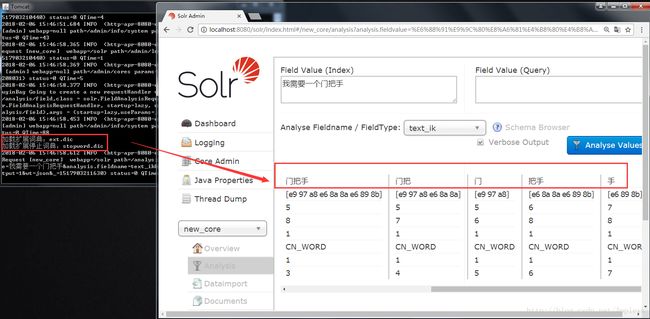
好吧,只能说低估了IK的分词能力(自身的词库),我们可以用下面的例子进行演示
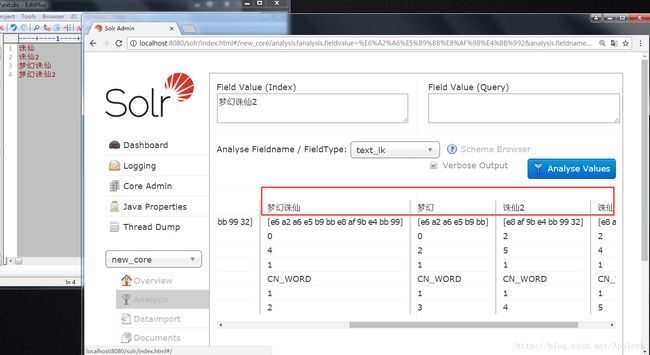
这个例子可行,至此,IK中文分词器成功配置到Solr 7.2.1中
下一篇:
Spring-Boot+Solr搜索应用(索引数据创建+关键字高亮+thymeleaf静态html模板渲染跳转)