13python数据分析分类算法– Knn算法 – 决策树 – 贝叶斯分类器 – 支持向量机 – 神经网络
分类
什么是分类
– 分类模型:输入样本的属性值,输出对应的类别,将每个样本映射到预先定义好的类别
常用分类算法
– Knn算法
– 决策树
– 贝叶斯分类器
– 支持向量机
– 神经网络
5种算法!!
分类:分为娱乐新闻、民生新闻、
识别到各个类别之间的差距,对于新给的一个新闻,根据历史信息预测到它的类别
有监督的学习:类别是已经确定的
根据训练集数据模型的创建、模型的使用
类别是给定的
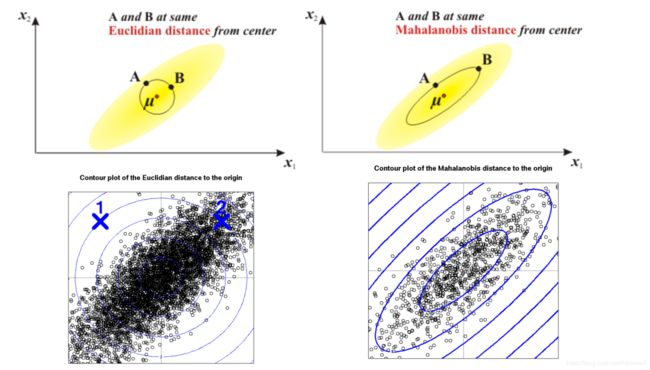
距离
马氏距离与欧氏距离
最近邻算法Knn
算法主要思想:
1 选取k个和待分类点距离最近的样本点
2 看1中的样本点的分类情况,投票决定待分类点所属的类
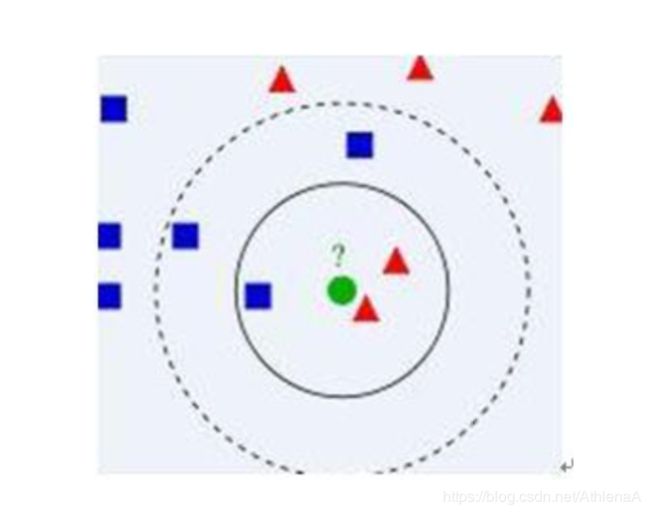
先看看自己身边的朋友是怎么样的。
k=3归为红色类
k=5归为蓝色类
但是没有给出k到底取多少
距离的概念
欧式距离 直线间距离
马氏距离 点与点的相似度
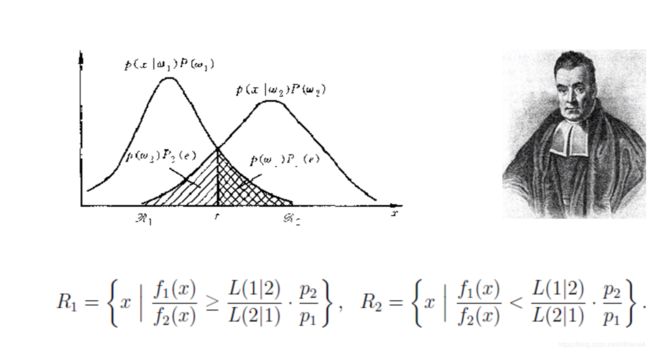
贝叶斯分类器
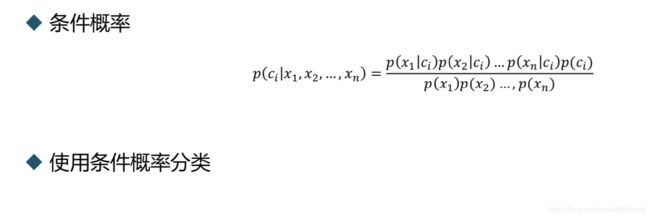
贝叶斯公式:条件概率
原理:不知道确切的分类,但是可以看到表现出来的属性
到底落在分布1的概率高还是落在分布2的概率高
根据先决条件,判断样本是落在哪一类的
要求属性之间相互独立
可能会有一些因果关系的存在



根据所表现出来的,反推出它归于某一个类的概率
贝叶斯网络也适用于多分类的情况
决策树 decision tree
什么是决策树
输入:学习集
输出:分类规则(决策树)
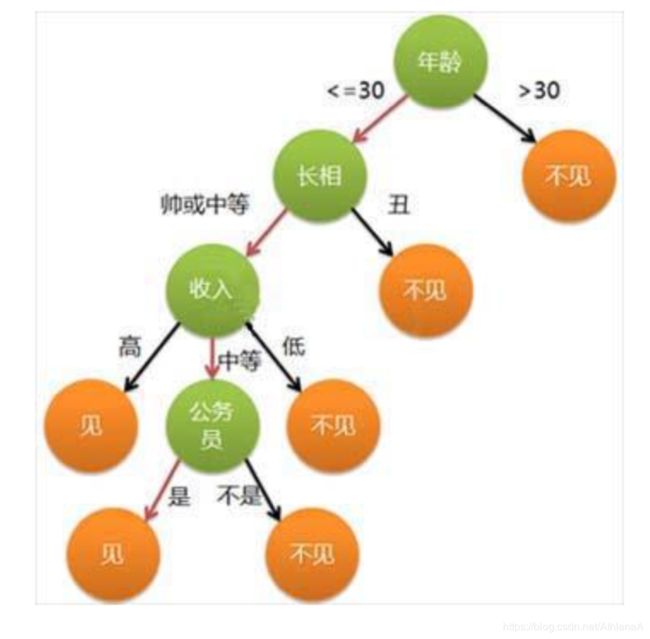
树中每一个非叶节点表示一个决策,该决策的值导致不同的决策结果(叶节点)或者影 响后面的决策选择。
根据给定的未知分类的元组X,根据其属性值跟踪一条由根节点到叶节点的路径,该 叶节点就是该元组的分类结果预测。
常见的决策树算法有:
ID3(->C4.5->C5.0)
CART(Classification And Regression Tree)
这两类算法的主要区别在于分裂属性时的选择方法。
在构建决策树时,这两类算法的流程基本一样,都采用贪心方法,自顶而下递归构建决策树。
名词解释
数据分区D
代表了节点上的数据
元组属性列表
属性A
结点N
类别C
贪心算法构建决策树
1.创建一个结点N。
如果D中的元组都在同一个类别C中,则N作为叶结点,以C标记;
如果属性列表为空,则N作为叶节点,以D中最多的类别C作为标记。
2.根据分裂准则找出“最好”的分裂属性A,并用该分裂属性标记N。
1)A是离散的,则 A的每个已知值都产生一个分支;
2)A是连续的,则产生A≤s和A>s两个分支;
3)若A是连续的,并且必须产生二叉树,则产生A∈A1和A∈A2两个分支,其中A1,A2非空且 A1∪A2=A
3.若给定的分支中的元组非空,对于D的每一个分支Dj,重复步骤1,2
属性选择度量
如果我们根据分裂准则把D划分为较小的分区,最好的情况是每个分区都是纯的,即落 在一个给定分区的所有元组都是相同的类。最好的分裂准则就是令到每个分区尽量的纯。
属性选择度量给学习集中的每个属性提供了评定。具有最好度量得分的属性被选为分裂 属性。
熵
ID3系列算法:基于熵
1948年,香农提出了“信息熵”的概念,解决了对系统信息的量化度量问题。
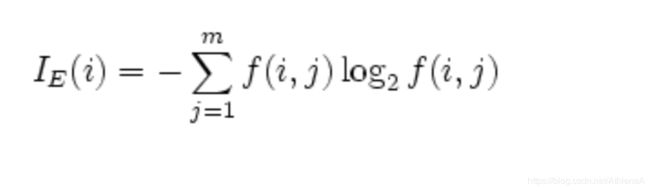
ID3——信息增益

信息增益定义为原来的信息需求与新的信息需求之间的差,即
Gain(A)=Info(D)-InfoA(D)
Gain(A)表示知道A的值而导致的信息需求的期望减少。 选择具有最大信息增益的属性作为分裂属性
连续值的信息增益
对于连续值属性A,要计算它的信息增益,其实也等价于寻找A的“最佳”分裂点。
1.将A的值按递增排序
2. 每对相邻值的中点(v个)是一个可能的分裂点。将A按照这些分裂点做v-1次划分,
计算每次划分的InfoA(D)
3.选择具有最小期望信息需求的点作为A的分裂点,并根据该分裂点计算A的信息增益
ID3算法的缺陷
信息增益存在着一定的局限性,它会倾向于选择具有大量值的属性,但是有时候这种属 性对分类其实没有多大作用。
例如每个学生的学号对其成绩高低的分类没有作用,但是 如果利用信息增益来选择分裂属性,学号这一属性的划分会导致大量分区,每一个分区 都只有一个学生所以每个分区都是纯的,但是这样的划分对分辨学生成绩的高低并没有 用。
C4.5——增益率

CART
与ID3算法的差异:
1.不是基于信息熵,而是基于不纯度来评定属性
2.严格的二元划分。使用ID3算法有可能会产生多叉树,但是使用CART算法只产生二叉树
3.根据y值类型的不同可分为回归树和分类树
连续变量。回归树
离散变量。分类树
分类树和回归树
分类树:y值是类别
回归树:y值是实数
异同:1.所用算法思路一致
2.评定分裂标准不一样
分类树



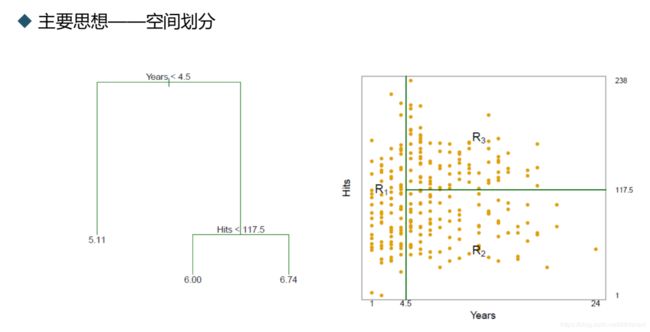
回归树
将空间中的点划分成不同的区域,同一个 区域中的点拥有相同的水平
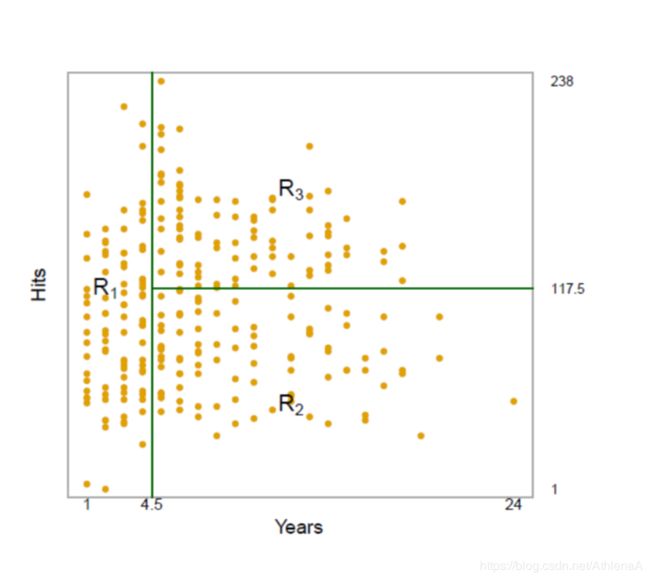


例子
Hitters数据集
根据篮球球员的各种 数据来预测篮球员的 薪酬的对数值(log salary)

树的修剪
为什么要修剪:避免过度拟合,简化模型
两种修剪方法:先剪枝与后剪枝
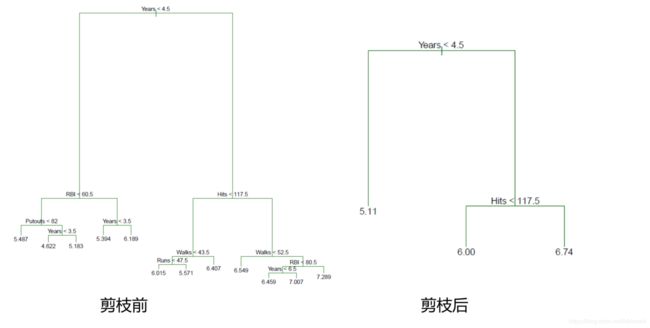
先剪枝:通过设定一定的阀值来停止树的生长
例如,在构建树模型时,使用信息增益、基尼指数来度量划分的优劣。可以 预先设定一个阀值,当划分一个结点的元组到时低于预设的阀值时,停止改 子集的划分
后剪枝:等树完全生成后再通过删除结点去修剪决策树。由于先剪枝中,选择合适的 阀值存在一定的困难,所以后剪枝更加常用
后剪枝

决策树的优缺点
优点:
1. 树模型十分通俗易懂,解释起来简单明了
2. 相对于其他模型,树模型可以通过图形模型展示,即使不具备相应专业知识的人可以一名了然
3.树模型可以直接处理定性变量,不需要增加虚拟变量
缺点:
准确率不够高
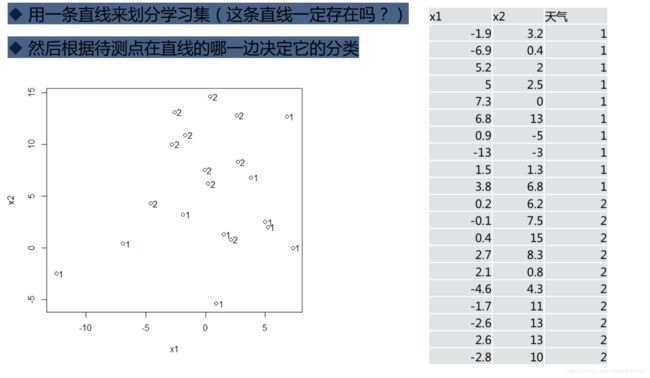
从线性判别法说起
用一条直线来划分学习集(这条直线一定存在吗?)
然后根据待测点在直线的哪一边决定它的分类
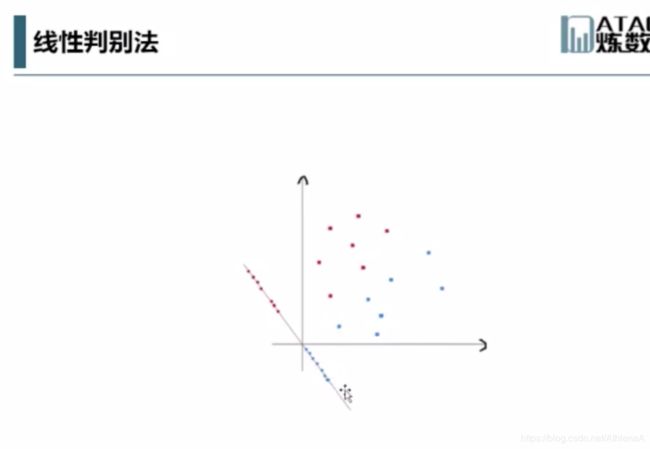
支持向量机SVM
支持向量机SVM
– 原创性(非组合)的具有明显直观几何意义的分类算法,具有较高的准确率
– 思想直观,但细节异常复杂,内容涉及凸分析算法,核函数,神经网络等高深的领域,几乎可以写成单独的大部头与著。大部分非与业人士会觉得难以理解。
两种情况
– 简单情况:线性可分,把问题转化为一个凸优化问题,可以用拉格朗日乘子法简化,然后用既有的算法解决
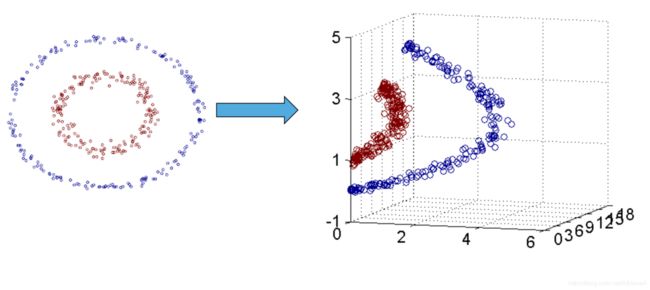
– 复杂情况:线性不可分,用映射函数将样本投射到高维空间,使其变成线性可分的情形。利用核函数来减少高维 度计算量
最优分隔平面

最大边缘超平面(MMH)
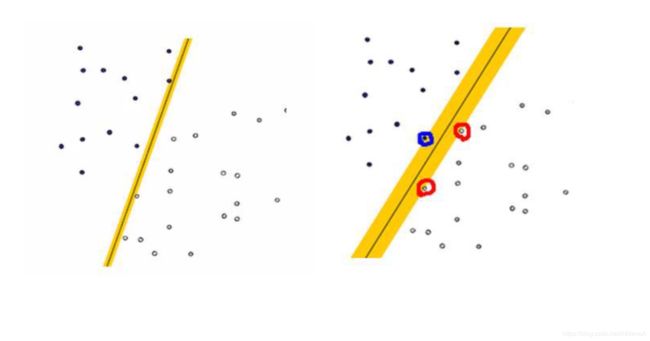
非线性情况
代码
# -*- coding: utf-8 -*-
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import classification_report
from sklearn.naive_bayes import BernoulliNB
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cross_validation import train_test_split
import matplotlib.pyplot as plt
import pandas as pd
####knn最邻近算法####
inputfile = 'd:/data/sales_data.xls'
data = pd.read_excel(inputfile, index_col = u'序号') #导入数据
#数据是类别标签,要将它转换为数据
#用1来表示“好”、“是”、“高”这三个属性,用-1来表示“坏”、“否”、“低”
data[data == u'好'] = 1
data[data == u'是'] = 1
data[data == u'高'] = 1
data[data != 1] = -1
x = data.iloc[:,:3].as_matrix().astype(int)
y = data.iloc[:,3].as_matrix().astype(int)
#拆分训练数据与测试数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
#训练KNN分类器
clf = KNeighborsClassifier(algorithm='kd_tree')
clf.fit(x_train, y_train)
#测试结果
answer = clf.predict(x_test)
print(x_test)
print(answer)
print(y_test)
print(np.mean( answer == y_test))
#准确率
precision, recall, thresholds = precision_recall_curve(y_train, clf.predict(x_train))
print(classification_report(y_test, answer, target_names = ['高', '低']))
####贝叶斯分类器####
#训练贝叶斯分类器
clf = BernoulliNB()
clf.fit(x_train,y_train)
#测试结果
answer = clf.predict(x_test)
print(x_test)
print(answer)
print(y_test)
print(np.mean( answer == y_test))
print(classification_report(y_test, answer, target_names = ['低', '高']))
####决策树####
from sklearn.tree import DecisionTreeClassifier as DTC
dtc = DTC(criterion='entropy') #建立决策树模型,基于信息熵
dtc.fit(x_train, y_train) #训练模型
#导入相关函数,可视化决策树。
#导出的结果是一个dot文件,需要安装Graphviz才能将它转换为pdf或png等格式。
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
with open("tree.dot", 'w') as f:
f = export_graphviz(dtc, out_file = f)
#测试结果
answer = dtc.predict(x_test)
print(x_test)
print(answer)
print(y_test)
print(np.mean( answer == y_test))
print(classification_report(y_test, answer, target_names = ['低', '高']))
####SVM####
from sklearn.svm import SVC
clf =SVC()
clf.fit(x_train, y_train)
#测试结果
answer = clf.predict(x_test)
print(x_test)
print(answer)
print(y_test)
print(np.mean( answer == y_test))
print(classification_report(y_test, answer, target_names = ['低', '高']))