L8机器学习进阶20180505
fig = plt.figure()
fig.set(alpha = 0.2)#设置
图表颜色alpha参数plt.subplot2grid((2,3),(0,0))#在一张大图里分列
几个小图data_train.Survived.value_counts()。plot(kind ='bar')#绘制一个条形图,表示那些有生之年的人与那些没有过的人。
plt.title(u“获救情况(1为获救)”)#在我们的图上放置一个标题
plt.ylabel(u“
人数”) plt.subplot2grid((2,3),(0,1))
data_train.Pclass .value_counts()。plot(kind =“bar”)
plt.ylabel(u“人数”)plt.title(u“
乘客等级分布”)
plt.subplot2grid((2,3),(0,2))
plt .scatter(data_train.Survived,data_train.Age)
plt.ylabel(u“年龄”)#设置y轴标记
plt.grid(b = True,which ='major',axis ='y')#格式化图表的网格线样式
plt.title(u“按年龄看获得分布(1为获救)”)
plt.subplot2grid ((2,3),(1,0),colspan = 2)
data_train.Age [data_train.Pclass == 1] .plot(kind ='kde')#绘制第一类子集的核心密度估计值年龄
data_train.Age [data_train.Pclass == 2] .plot(kind ='kde')
data_train.Age [data_train.Pclass == 3] .plot(kind ='kde')
plt.xlabel(u“年龄” )
#plots an axis lable plt.ylabel(u“密度”)
plt.title(u“各等级的
乘客年龄分布”)plt.legend((u'头等舱',u'2等舱',u'3等舱'),loc ='best')#为我们的图表设置我们的图例。
plt.subplot2grid((2,3),(1,2))
data_train.Embarked。
plt.ylabel(U “人数”)
plt.show()
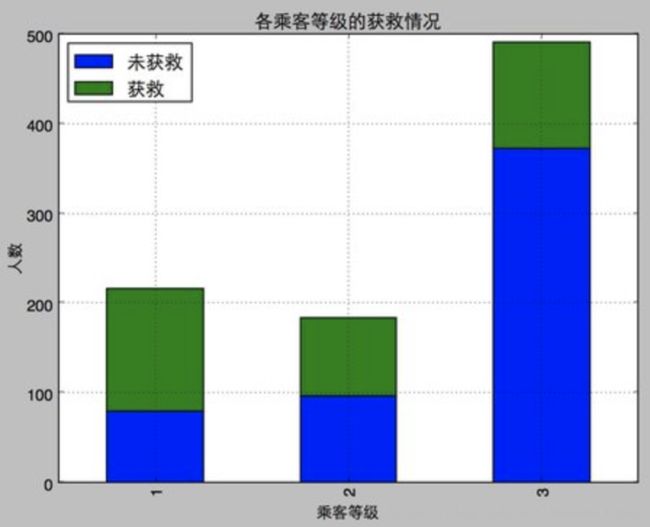
#看看各乘客等级的获得情况
fig = plt.figure()
fig.set(alpha = 0.2)#设置
图表颜色alpha参数Survived_0 = data_train.Pclass [data_train.Survived == 0] .value_counts()Survived_1
= data_train.Pclass [data_train.Survived == 1] .value_counts()
df = pd.DataFrame({u'获救':Survived_1,u'未获救':
Survived_0 })df.plot(kind ='bar',stacked =真)
plt.title(u“各乘客等级的获救情况”)
plt.xlabel(u“
乘客等级”) plt.ylabel(u“人数”)
plt.show()
#然后我们再来看看各种舱级别情况下各性别的获救情况
fig = plt.figure()
fig.set(alpha = 0.65)#设置图像透明度,无所谓
plt.title(u“根据舱等级和性别的获得情况“)
ax1 = fig.add_subplot(141)
data_train.Survived [data_train.Sex =='female'] [data_train.Pclass!= 3] .value_counts()。plot(kind ='bar',label =”female (最好是“高级舱”),color ='#FA2479')
ax1.set_xticklabels([u“获救”,u“未获救”],rotation = 0)
ax1.legend([u“女性/高级舱”], )
ax2 = fig.add_subplot(142,sharey = ax1)
data_train.Survived [data_train.Sex =='female'] [data_train.Pclass == 3] .value_counts()。plot(kind ='bar',label ='女,低班',color ='pink')
ax2.set_xticklabels([u“未获救”,u“获救”],rotation = 0)
plt。legend([u“女性/低级舱”],loc ='best')
ax3 = fig.add_subplot(143,sharey = ax1)
data_train.Survived [data_train.Sex =='male'] [data_train.Pclass!= 3] .value_counts()。plot(kind ='bar',label ='male,high class',color ='lightblue')
ax3 .set_xticklabels([u'未获救“,u”获救“],rotation = 0)
plt.legend([u'男性/高级舱”],loc ='best')
ax4 = fig.add_subplot(144,sharey = ax1)
data_train.Survived [data_train.Sex =='male'] [data_train.Pclass == 3] .value_counts()。plot(kind ='bar',label ='male low class',color ='steelblue')
ax4.set_xticklabels([u'未获救“,u”获救“],rotation = 0)
plt.legend([u”男性/低级舱“],loc ='best')
plt.show()

先用scikit-learn里面的preprocessing模块对Age和Fare两个属性做一个scaling,所谓scaling,其实就是将一些变化幅度较大的特征化到[-1,1]之内。
# 接下来我们要接着做一些数据预处理的工作,比如scaling,将一些变化幅度较大的特征化到[-1,1]之内
# 这样可以加速logistic regression的收敛
import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(df['Age']) # 标准化参数
df['Age_scaled'] = scaler.fit_transform(df['Age'], age_scale_param) # 执行标准化
fare_scale_param = scaler.fit(df['Fare'])
df['Fare_scaled'] = scaler.fit_transform(df['Fare'], fare_scale_param)
df


我们把需要的feature字段取出来,转成numpy格式,使用scikit-learn中的LogisticRegression建模。
# 我们把需要的feature字段取出来,转成numpy格式,使用scikit-learn中的LogisticRegression建模
from sklearn import linear_model
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.as_matrix()
# y即Survival结果
y = train_np[:, 0]
# X即特征属性值
X = train_np[:, 1:]
# fit到RandomForestRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(X, y)
clf

import numpy as np
import matplotlib.pyplot as plt
from sklearn.learning_curve import learning_curve
# 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib画出learning curve
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1,
train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
n_jobs : 并行的的任务数(默认1)
"""
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
if plot:
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel(u"训练样本数")
plt.ylabel(u"得分")
plt.gca().invert_yaxis()
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="b")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="r")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"训练集上得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"交叉验证集上得分")
plt.legend(loc="best")
plt.draw()
plt.gca().invert_yaxis()
plt.show()
midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2
diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_std[-1])
return midpoint, diff
plot_learning_curve(clf, u"学习曲线", X, y)
