网站不再单单迎合人类读者。许多站点现在支持一些 API,这些 API 使计算机程序能够获取信息。屏幕抓取 ―― 将 HTML 页面解析为更容易理解的表单的省时技术 ― 仍然很方便。但使用 API 简化 Web 数据提取的机会在快速增多。根据 ProgrammableWeb 的信息,在本文发表时,已存在 10,000 多个网站 API ― 在过去的 15 个月中增加了 3,000 个。(ProgrammableWeb 本身提供了一个 API,可从其目录中搜索和检索 API、mashup、成员概要文件和其他数据。)
本文首先介绍现代的 Web 抓取并将它与 API 方法进行比较。然后通过 Ruby 示例,展示如何使用 API 从一些流行的 Web 属性中提取结构化信息。您需要基本理解 Ruby 语言、具象状态传输 (REST),以及 JavaScript 对象表示法 (JSON) 和 XML 概念。
抓取与 API
现在已有多种抓取解决方案。其中一些将 HTML 转换为其他格式,比如 JSON,这样提取想要的内容会更加简单。其他解决方案读取 HTML,您可将内容定义为 HTML 分层结构的一个函数,其中的数据已加了标记。一种此类解决方案是 Nokogiri,它支持使用 Ruby 语言解析 HTML 和 XML 文档。其他开源抓取工具包括用于 JavaScript 的 pjscrape 和用于 Python 的 Beautiful Soup。pjscrape 实现一个命令行工具来抓取完全呈现的页面,包括 JavaScript 内容。Beautiful Soup 完全集成到 Python 2 和 3 环境中。
假设您希望使用抓取功能和 Nokogiri 来识别 CrunchBase 所报告的 IBM 员工数量。第一步是理解 CrunchBase 上列出了 IBM 员工数量的特定 HTML 页面的标记。图 1 显示了在 Mozilla Firefox 中的 Firebug 工具中打开的此页面。该图的上半部分显示了所呈现的 HTML,下半部分显示了感兴趣部分的 HTML 源代码。
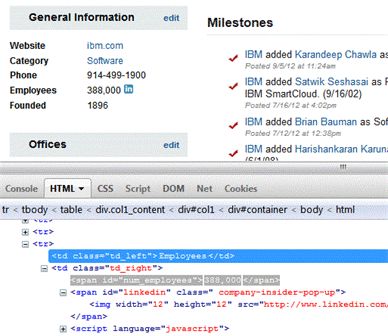
清单 1 中的 Ruby 脚本使用 Nokogiri 从图 1 中的网页抓取员工数量。
清单 1. 使用 Nokogiri 解析 HTML (parse.rb)
#!/usr/bin/env ruby
require 'rubygems'
require 'nokogiri'
require 'open-uri'
# Define the URL with the argument passed by the user
uri = "http://www.crunchbase.com/company/#{ARGV[0]}"
# Use Nokogiri to get the document
doc = Nokogiri::HTML(open(uri))
# Find the link of interest
link = doc.search('tr span[1]')
# Emit the content associated with that link
puts link[0].content
在 Firebug 显示的 HTML 源代码中(如 图 1 所示),您可看到感兴趣的数据(员工数量)嵌入在一个 HTML 唯一 ID 标记内。还可看到 标记是两个 ID 标记中的第一个。所以,清单 1 中的最后两个指令是,使用 link = doc.search('tr span[1]') 请求第一个 标记,然后使用 puts link[0].content 发出这个已解析链接的内容。
CrunchBase 还公开了一个 REST API,它能够访问的数据比通过抓取功能访问的数据要多得多。清单 2 显示了如何使用该 API 从 CrunchBase 站点提取公司的员工数。
清单 2. 结合使用 CrunchBase REST API 和 JSON 解析 (api.rb)
#!/usr/bin/env ruby
require 'rubygems'
require 'json'
require 'net/http'
# Define the URL with the argument passed by the user
uri = "http://api.crunchbase.com/v/1/company/#{ARGV[0]}.js"
# Perform the HTTP GET request, and return the response
resp = Net::HTTP.get_response(URI.parse(uri))
# Parse the JSON from the response body
jresp = JSON.parse(resp.body)
# Emit the content of interest
puts jresp['number_of_employees']
在清单 2 中,您定义了一个 URL(公司名称作为脚本参数传入)。然后使用 HTTP 类发出一个 GET 请求并返回响应。响应被解析为一个 JSON 对象,您可通过一个 Ruby 数据结构引用感兴趣的数据项。
清单 3 中的控制台会话显示了运行 清单 1 中的抓取脚本和 清单 2 中基于 API 的脚本的结果。
清单 3. 演示抓取和 API 方法
$ ./parse.rb ibm 388,000 $ ./api.rb ibm 388000 $ ./parse.rb cisco 63,000 $ ./api.rb cisco 63000 $ ./parse.rb paypal 300,000 $ ./api.rb paypal 300000 $
抓取脚本运行时,您接收一个格式化的计数,而 API 脚本会生成一个原始整数。如清单 3 所示,您可推广每种脚本的使用,从 CrunchBase 跟踪的其他公司请求获得员工数。每种方法提供的 URL 的一般结构使这种通用性成为可能。
那么,我们使用 API 方法能获得什么?对于抓取,您需要分析 HTML 以理解它的结构并识别要提取的数据。然后使用 Nokogiri 解析 HTML 并获取感兴趣的数据就会很简单。但是,如果 HTML 文档的结构发生变化,您可能需要修改脚本才能正确解析新结构。根据 API 契约,API 方法不存在该问题。API 方法的另一个重要优点是,您可访问通过接口(通过返回的 JSON 对象)公开的所有数据。通过 HTML 公开且可供人使用的 CrunchBase 数据要少得多。
现在看看如何使用其他一些 API 从 Internet 提取各类信息,同样要借助 Ruby 脚本。首先看看如何从一个社交网络站点收集个人数据。然后将看到如何通过其他 API 来源查找更少的个人数据。
通过 LinkedIn 提取个人数据
LinkedIn 是一个面向专业职业的社交网络网站。它对联系其他开发人员,寻找工作,研究一家公司,或者加入一个群组,就有趣的主题进行协作很有用。LinkedIn 还整合了一个推荐引擎,可根据您的概要文件推荐工作和公司。
LinkedIn 用户可访问该站点的 REST 和 JavaScript API,从而获取可通过其人类可读网站访问的信息:联系信息、社交分享流、内容群组、通信(消息和联系邀请),以及公司和工作信息。
要使用 LinkedIn API,您必须注册您的应用程序。注册后会获得一个 API 密钥和秘密秘钥,以及一个用户令牌和秘密秘钥。LinkedIn 使用 OAuth 协议进行身份验证。
执行身份验证后,您可通过访问令牌对象发出 REST 请求。响应是一个典型的 HTTP 响应,所以您可将正文解析为 JSON 对象。然后可迭代该 JSON 对象来提取感兴趣的数据。
清单 4 中的 Ruby 脚本为进行身份验证后的 LinkedIn 用户提供了要关注的公司推荐和工作建议。
清单 4. 使用 LinkedIn API (lkdin.rb) 查看公司和工作建议
#!/usr/bin/ruby
require 'rubygems'
require 'oauth'
require 'json'
pquery = "http://api.linkedin.com/v1/people/~?format=json"
cquery='http://api.linkedin.com/v1/people/~/suggestions/to-follow/companies?format=json'
jquery='http://api.linkedin.com/v1/people/~/suggestions/job-suggestions?format=json'
# Fill the keys and secrets you retrieved after registering your app
api_key = 'api key'
api_secret = 'api secret'
user_token = 'user token'
user_secret = 'user secret'
# Specify LinkedIn API endpoint
configuration = { :site => 'https://api.linkedin.com' }
# Use the API key and secret to instantiate consumer object
consumer = OAuth::Consumer.new(api_key, api_secret, configuration)
# Use the developer token and secret to instantiate access token object
access_token = OAuth::AccessToken.new(consumer, user_token, user_secret)
# Get the username for this profile
response = access_token.get(pquery)
jresp = JSON.parse(response.body)
myName = "#{jresp['firstName']} #{jresp['lastName']}"
puts "\nSuggested companies to follow for #{myName}"
# Get the suggested companies to follow
response = access_token.get(cquery)
jresp = JSON.parse(response.body)
# Iterate through each and display the company name
jresp['values'].each do | company |
puts " #{company['name']}"
end
# Get the job suggestions
response = access_token.get(jquery)
jresp = JSON.parse(response.body)
puts "\nSuggested jobs for #{myName}"
# Iterate through each suggested job and print the company name
jresp['jobs']['values'].each do | job |
puts " #{job['company']['name']} in #{job['locationDescription']}"
end
puts "\n"
清单 5 中的控制台会话显示了运行 清单 4 中的 Ruby 脚本的输出。脚本中对 LinkedIn API 的 3 次独立调用有不同的输出结果(一个用于身份验证,其他两个分别用于公司建议和工作建议链接)。
清单 5. 演示 LinkedIn Ruby 脚本
$ ./lkdin.rb Suggested companies to follow for M. Tim Jones Open Kernel Labs, Inc. Linaro Wind River DDC-I Linsyssoft Technologies Kalray American Megatrends JetHead Development Evidence Srl Aizyc Technology Suggested jobs for M. Tim Jones Kozio in Greater Denver Area Samsung Semiconductor Inc in San Jose, CA Terran Systems in Sunnyvale, CA Magnum Semiconductor in San Francisco Bay Area RGB Spectrum in Alameda, CA Aptina in San Francisco Bay Area CyberCoders in San Francisco, CA CyberCoders in Alameda, CA SanDisk in Longmont, CO SanDisk in Longmont, CO $
可将 LinkedIn API 与任何提供了 OAuth 支持的语言结合使用。
使用 Yelp API 检索业务数据
Yelp 公开了一个富 REST API 来执行企业搜索,包含评分、评论和地理搜索(地段、城市、地理编码)。使用 Yelp API,您可搜索一种给定类型的企业(比如 “饭店”)并将搜索限制在一个地理边界内;一个地理坐标附近;或者一个邻居、地址或城市附近。JSON 响应包含了与条件匹配的企业的大量相关信息,包括地址信息、距离、评分、交易,以及其他类型的信息(比如该企业的图片、移动格式信息等)的 URL。
像 LinkedIn 一样,Yelp 使用 OAuth 执行身份验证,所以您必须向 Yelp 注册才能通过该 API 获得一组用于身份验证的凭据。脚本完成身份验证后,可构造一个基于 REST 的 URL 请求。在清单 6 中,我硬编码了一个针对科罗拉多州 Boulder 的饭店请求。响应正文被解析到一个 JSON 对象中并进行迭代,从而发出想要的信息。注意,我排除了已关闭的企业。
清单 6. 使用 Yelp API (yelp.rb) 检索企业数据
#!/usr/bin/ruby
require 'rubygems'
require 'oauth'
require 'json'
consumer_key = 'your consumer key'
consumer_secret = 'your consumer secret'
token = 'your token'
token_secret = 'your token secret'
api_host = 'http://api.yelp.com'
consumer = OAuth::Consumer.new(consumer_key, consumer_secret, {:site => api_host})
access_token = OAuth::AccessToken.new(consumer, token, token_secret)
path = "/v2/search?term=restaurants&location=Boulder,CO"
jresp = JSON.parse(access_token.get(path).body)
jresp['businesses'].each do | business |
if business['is_closed'] == false
printf("%-32s %10s %3d %1.1f\n",
business['name'], business['phone'],
business['review_count'], business['rating'])
end
end
清单 7 中的控制台会话显示了运行 清单 6 脚本的示例输出。为了简单一些,我只显示了所返回的前面一组企业,而不是支持该 API 的限制/偏移特性(以执行多个调用来检索整个列表)。这段示例输出显示了企业名称、电话号码、收到的评论数和平均评分。
清单 7. 演示 Yelp API Ruby 脚本
$ ./yelp.rb Frasca Food and Wine 3034426966 189 4.5 John's Restaurant 3034445232 51 4.5 Leaf Vegetarian Restaurant 3034421485 144 4.0 Nepal Cuisine 3035545828 65 4.5 Black Cat Bistro 3034445500 72 4.0 The Mediterranean Restaurant 3034445335 306 4.0 Arugula Bar E Ristorante 3034435100 48 4.0 Ras Kassa's Ethiopia Restaurant 3034472919 101 4.0 L'Atelier 3034427233 58 4.0 Bombay Bistro 3034444721 87 4.0 Brasserie Ten Ten 3039981010 200 4.0 Flagstaff House 3034424640 86 4.5 Pearl Street Mall 3034493774 77 4.0 Gurkhas on the Hill 3034431355 19 4.0 The Kitchen 3035445973 274 4.0 Chez Thuy Restaurant 3034421700 99 3.5 Il Pastaio 3034479572 113 4.5 3 Margaritas 3039981234 11 3.5 Q's Restaurant 3034424880 65 4.0 Julia's Kitchen 8 5.0 $
Yelp 提供了一个具有出色文档的 API,以及数据描述、示例、错误处理等。尽管 Yelp API 很有用,但它的使用有一定的限制。作为软件原始开发人员,您每天最多可执行 100 次 API 调用,出于测试用途可执行 1,000 次调用。如果您的应用程序满足 Yelp 的显示需求,每天可执行 10,000 次调用(也可能执行更多次)。
包含一个简单 mashup 的域位置
下一个示例将两段源代码连接起来,以生成信息。在本例中,您要将一个 Web 域名转换为它的一般地理位置。清单 8 中的 Ruby 脚本使用 Linux? host 命令和 OpenCrypt IP Location API Service 来检索位置信息。
清单 8. 检索 Web 域的位置信息
#!/usr/bin/env ruby
require 'net/http'
aggr = ""
key = 'your api key here'
# Get the IP address for the domain using the 'host' command
IO.popen("host #{ARGV[0]}") { | line |
until line.eof?
aggr += line.gets
end
}
# Find the IP address in the response from the 'host' command
pattern = /\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$/
if m = pattern.match(aggr)
uri = "http://api.opencrypt.com/ip/?IP=#{m[0]}&key=#{key}"
resp = Net::HTTP.get_response(URI.parse(uri))
puts resp.body
end
在清单 8 中,您首先使用本地的 host 命令将域名转换为 IP 地址。(host 命令本身使用一个内部 API 和 DNS 解析将域名解析为 IP 地址。)您使用一个简单的正则表达式(和 match 方法)从 host 命令输出中解析 IP 地址。有了 IP 地址,就可使用 OpenCrypt 上的 IP 位置服务来检索一般地理位置信息。OpenCrypt API 允许您执行最多 50,000 次免费 API 调用。
OpenCrypt API 调用很简单:您构造的 URL 包含您要定位的 IP 地址和 OpenCrypt 注册过程提供给您的密钥。HTTP 响应正文包含 IP 地址、国家代码和国家名称。
清单 9 中的控制台会话显示了两个示例域名的输出。
清单 9. 使用简单的域位置脚本
$ ./where.rb www.baynet.ne.jp IP=111.68.239.125 CC=JP CN=Japan $ ./where.rb www.pravda.ru IP=212.76.137.2 CC=RU CN=Russian Federation $
Google API 查询
Web API 方面一个无可争辩的优胜者是 Google。Google 拥有如此多的 API,以至于它提供了另一个 API 来查询它们。通过 Google API Discovery Service,您可列出 Google 提供的可用 API 并提取它们的元数据。尽管与大部分 Google API 的交互需要进行身份验证,但您可通过一个安全套接字连接访问查询 API。出于此原因,清单 10 使用 Ruby 的 https 类来构造与安全端口的连接。已定义的 URL 指定了 REST 请求,而且响应采用了 JSON 编码。迭代响应并发出一小部分首选的 API 数据。
清单 10. 使用 Google API Discovery Service (gdir.rb) 列出 Google API
#!/usr/bin/ruby
require 'rubygems'
require 'net/https'
require 'json'
url = 'https://www.googleapis.com/discovery/v1/apis'
uri = URI.parse(url)
# Set up a connection to the Google API Service
http = Net::HTTP.new( uri.host, 443 )
http.use_ssl = true
http.verify_mode = OpenSSL::SSL::VERIFY_NONE
# Connect to the service
req = Net::HTTP::Get.new(uri.request_uri)
resp = http.request(req)
# Get the JSON representation
jresp = JSON.parse(resp.body)
# Iterate through the API List
jresp['items'].each do | item |
if item['preferred'] == true
name = item['name']
title = item['title']
link = item['discoveryLink']
printf("%-17s %-34s %-20s\n", name, title, link)
end
end
清单 11 中的控制台会话显示了运行清单 10 中脚本得到的响应示例。
清单 11. 使用简单的 Google 目录服务 Ruby 脚本
$ ./gdir.rb adexchangebuyer Ad Exchange Buyer API ./apis/adexchangebuyer/v1.1/rest adsense AdSense Management API ./apis/adsense/v1.1/rest adsensehost AdSense Host API ./apis/adsensehost/v4.1/rest analytics Google Analytics API ./apis/analytics/v3/rest androidpublisher Google Play Android Developer API ./apis/androidpublisher/v1/rest audit Enterprise Audit API ./apis/audit/v1/rest bigquery BigQuery API ./apis/bigquery/v2/rest blogger Blogger API ./apis/blogger/v3/rest books Books API ./apis/books/v1/rest calendar Calendar API ./apis/calendar/v3/rest compute Compute Engine API ./apis/compute/v1beta12/rest coordinate Google Maps Coordinate API ./apis/coordinate/v1/rest customsearch CustomSearch API ./apis/customsearch/v1/rest dfareporting DFA Reporting API ./apis/dfareporting/v1/rest discovery APIs Discovery Service ./apis/discovery/v1/rest drive Drive API ./apis/drive/v2/rest ... storage Cloud Storage API ./apis/storage/v1beta1/rest taskqueue TaskQueue API ./apis/taskqueue/v1beta2/rest tasks Tasks API ./apis/tasks/v1/rest translate Translate API ./apis/translate/v2/rest urlshortener URL Shortener API ./apis/urlshortener/v1/rest webfonts Google Web Fonts Developer API ./apis/webfonts/v1/rest youtube YouTube API ./apis/youtube/v3alpha/rest youtubeAnalytics YouTube Analytics API ./apis/youtubeAnalytics/v1/rest $
清单 11 中的输出显示了 API 名称、它们的标题,以及进一步分析每个 API 的 URL 路径。
结束语
本文中的示例演示了公共 API 在从 Internet 提取信息方面的强大功能。与 Web 抓取和爬取 (spidering) 相比,Web API 提供了访问有针对性的特定信息的能力。Internet 上在不断创造新价值,这不仅通过使用这些 API 来实现,还通过用新颖的方式组合它们,从而向越来越多的 Web 用户提供新数据来实现。
但是请记住,使用 API 需要付出一定的代价。限制问题就常让人抱怨。同样,可能在不通知您的情况下更改 API 规则这一事实,因此在构建应用程序时必须加以考虑。最近,Twitter 更改了它的 API 来提供 “一种更加一致的体验”。这一更改对许多可能被视为典型 Twitter Web 客户端竞争对手的第三方应用程序而言,无疑是一场灾难。