前言
常见的自定义流有四种,Readable(可读流)、Writable(可写流)、Duplex(双工流)和 Transform(转换流),常见的自定义流应用有 HTTP 请求、响应, crypto 加密,进程 stdin 通信等等。
stream 模块介绍
在 NodeJS 中要想实现自定义流,需要依赖模块 stream ,直接引入,不需下载,所有种类的流都是继承这个模块内部提供的对应不同种类的类来实现的。
实现一个自定义可读流 Readable
1、创建自定义可读流的类 MyRead
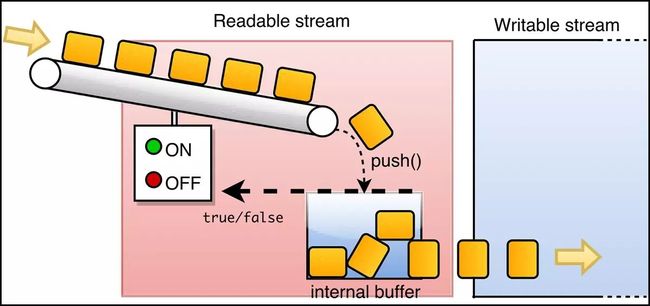
实现自定义可读流需创建一个类为 MyRead ,并继承 stream 中的 Readable 类,重写 _read 方法,这是所有自定义流的固定套路。
let { Readable } = require("stream");
// 创建自定义可读流的类
class MyRead extends Readable {
constructor() {
super();
this.index = 0;
}
// 重写自定义的可读流的 _read 方法
_read() {
this.index++;
this.push(this.index + "");
if (this.index === 3) {
this.push(null);
}
}
}
我们自己写的 _read 方法会先查找并执行,在读取时使用 push 方法将数据读取出来,直到 push 的值为 null 才会停止,否则会认为没有读取完成,会继续调用 _read 。
2、验证自定义可读流
let myRead = new MyRead();
myRead.on("data", data => {
console.log(data);
});
myRead.on("end", function() {
console.log("读取完成");
});
//
//
//
// 读取完成
实现一个自定义可写流 Writable
1、创建自定义可写流的类 MyWrite
创建一个类名为 MyWrite ,并继承 stream 中的 Writable 类,重写 _write 方法。
let { Writable } = require("stream");
// 创建自定义可写流的类
class MyWrite extends Writable {
// 重写自定义的可写流的 _write 方法
_write(chunk, encoding, callback)) {
callback(); // 将缓存区写入文件
}
}
写入内容时默认第一次写入直接写入文件,后面的写入都写入缓存区,如果不调用 callback 只能默认第一次写入文件,调用 callback 会将缓存区清空并写入文件。
2、验证自定义可写流
let myWrite = new MyWrite();
myWrite.write("hello", "utf8", () => {
console.log("hello ok");
});
myWrite.write("world", "utf8", () => {
console.log("world ok");
});
// hello ok
// world ok
实现一个自定义双工流 Duplex
1、创建自定义可双工流的类 MyDuplex
双工流的可以理解为即可读又可写的流,创建一个类名为 MyDuplex ,并继承 stream 中的 Duplex 类,由于双工流即可读又可写,需重写 _read 和 _write 方法。
let { Duplex } = require("stream");
// 创建自定义双工流的类
class MyDuplex extends Duplex {
// 重写自定义的双工流的 _read 方法
_read() {
this.push("123");
this.push(null);
}
// 重写自定义的双工流的 _write 方法
_write(chunk, encoding, callback)) {
callback();
}
}
双工流分别具备 Readable 和 Writable 的功能,但是读和写互不影响,互不关联。
2、验证自定义双工流
let myDuplex = new MyDuplex();
myDuplex.on("readable", () => {
console.log(myDuplex.read(1), "----");
});
setTimeout(() => {
myDuplex.on("data", data => {
console.log(data, "xxxx");
});
}, 3000);
// ----
// xxxx
// ----
// xxxx
如果 readable 和 data 两种读取方式都使用默认先通过 data 事件读取,所以一般只选择一个,不要同时使用,可读流的特点是读取数据被消耗掉后就丢失了(缓存区被清空),如果非要两个都用可以加一个定时器(绝对不要这样写)。
实现一个自定义转化流 Transform
1、创建自定义可转化流的类 MyTransform
转化流的意思是即可以当作可读流,又可以当作可写流,创建一个类名为 MyTransform ,并继承 stream 中的 Transform 类,重写 _transform 方法,该方法的参数和 _write 相同。
let { Transform } = require('stream');
// 创建自定义转化流的类
class MyTransform extends Transform {
// 重写自定义的转化流的 _transform 方法
_transform(chunk, encoding, callback)) {
console.log(chunck.toString.toUpperCase());
callback();
this.push('123');
}
}
在自定义转化流的 _transform 方法中,读取数据的 push 方法和 写入数据的 callback 都可以使用。
2、验证自定义转化流
// demo.js let myTransForm = new MyTransform(); // 使用标准输入 process.stdin.pipe(myTransForm).pipe(process.stdin);
打开命令行窗口执行 node demo.js ,然后输入 abc ,会在命令窗口输出 ABC 和 123 ,其实转换流先作为一个可写流被写入到标准输入中,而此时 stdin 的作用是读流,即读取用户的输入,读取后转换流作为一个可读流调用 pipe ,将用户输入的信息通过标准输出写到命令行窗口,此时 stdout 的作用是写流。
总结
以上所述是小编给大家介绍的NodeJS实现自定义流,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对脚本之家网站的支持!