鉴于即将启程旅行,先上传篇简单的图像检索介绍,与各位一起学习opencv的同学共勉
一.特征检测
图片的特征主要分为角点,斑点,边,脊向等,都是常用特征检测算法所检测到的图像特征・
1.Harris角点检测
先将图片转换为灰度模式,再使用以下函数检测图片的角点特征:
dst=cv2.cornerHarris(src, blockSize, ksize, k[, dst[, borderType]])
重点关注第三个参数,这里使用了Sobel算子,简单来说,其取为3-31间的奇数,定义了角点检测的敏感性,不同图片需要进行调试。
k 是 Harris 角点检测方程中的自由参数,取值参数为[0,04,0.06].
2.DoG角点检测及SIFT特征变换
Harris角点检测在面对图像尺度性发生改变时极其容易丢失图像细节,造成检测失误。因此在检测图像特征时,常常我们需要一些拥有尺度不变性的特征检测算法。
DoG角点检测即将两幅图像在不同参数下的高斯滤波结果相减,得到DoG图。步骤:用两个不同的5x5高斯核对图像进行卷积,然后再相减的操作。重复三次得到三个差分图A,B,C。计算出的A,B,C三个DOG图中求图B中是极值的点。图B的点在当前由A,B,C共27个点组成的block中是否为极大值或者极小值。若满足此条件则认为是角点。
SIFT对象会使用DoG检测关键点,并对每个关键点周围的区域计算特征向量。事实上他仅做检测和计算,其返回值是关键点信息(关键点)和描述符。
#下列代码即先创建一个SIFT对象,然后计算灰度图像 sift = cv2.xfeatures2d.SIFT_create() keypoints, descriptor = sift.detectAndCompute(gray, None) #sift对象会使用DoG检测关键点,对关键点周围的区域计算向量特征,检测并计算
需要注意的是,返回的是关键点和描述符
关键点是点的列表
描述符是检测到的特征的局部区域图像列表
介绍一下关键点的属性:pt: 点的x y坐标 size: 表示特征的直径 angle: 特征方向 response: 关键点的强度 octave: 特征所在金字塔层级,算法进行迭代的时候, 作为参数的图像尺寸和相邻像素会发生变化octave属性表示检测到关键点所在的层级 ID: 检测到关键点的ID
SIFT特征不只具有尺度不变性,即使改变旋转角度,图像亮度或拍摄视角,仍然能够得到好的检测效果。
3.SURF提取和检测特征
SURF是SIFT的加速版算法,采用快速Hessian算法检测关键点
借用下度娘的说法:SURF算法原理:
1.构建Hessian矩阵构造高斯金字塔尺度空间
2.利用非极大值抑制初步确定特征点
3精确定位极值点
4选取特征点的主方向
5构造surf特征点描述算子
具体应用看代码
import cv2
import numpy as np
img = cv2.imread('/home/yc/Pictures/jianbin.jpg')
#参数为hessian矩阵的阈值
surf = cv2.xfeatures2d.SURF_create(4000)
#设置是否要检测方向
surf.setUpright(True)
#输出设置值
print(surf.getUpright())
#找到关键点和描述符
key_query,desc_query = surf.detectAndCompute(img,None)
img=cv2.drawKeypoints(img,key_query,img)
#输出描述符的个数
print(surf.descriptorSize())
cv2.namedWindow("jianbin",cv2.WINDOW_NORMAL)
cv2.imshow('jianbin',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
这是检测效果,图中已标志出特征点,不要问我为什么选这种鬼畜样图,可能是因为情怀(滑稽)

样图
需要注意的是,需要安装之前版本的opencv-contrib库才可以使用,surf及sift均受专利保护
4.orb特征提取
ORB算法使用FAST算法寻找关键点,然后使用Harris角点检测找到这些点当中的最好的N个点,采用BRIEF描述子的特性。ORB算法处于起步阶段,速度优于前两种算法,也吸收了其优点,同时他是开源的。
# 创建ORB特征检测器和描述符 orb = cv2.ORB_create() kp = orb.detect(img,None) # 对图像检测特征和描述符 kp, des = orb.compute(img, kp) #注意kp是一个包含若干点的列表,des对应每个点的描述符 是一个列表, 每一项都是检测>到的特征的局部图像
二、特征匹配
1.BF暴力匹配
暴力匹配的算法难以进行优化,是一种描述符匹配方法,将每个对应的描述符的特征进行比较,每次比较给出一个距离值,最好的结果贼被认为是一个匹配。
# 暴力匹配BFMatcher,遍历描述符,确定描述符是否匹配,然后计算匹配距离并排序 # BFMatcher函数参数: # normType:NORM_L1, NORM_L2, NORM_HAMMING, NORM_HAMMING2。 # NORM_L1和NORM_L2是SIFT和SURF描述符的优先选择,NORM_HAMMING和NORM_HAMMING2是用于ORB算法 bf = cv2.BFMatcher(normType=cv2.NORM_HAMMING, crossCheck=True) matches = bf.match(des1,des2) matches = sorted(matches, key = lambda x:x.distance) # matches是DMatch对象,具有以下属性: # DMatch.distance - 描述符之间的距离。 越低越好。 # DMatch.trainIdx - 训练描述符中描述符的索引 # DMatch.queryIdx - 查询描述符中描述符的索引 # DMatch.imgIdx - 训练图像的索引。
2.K-最近邻匹配
KNN算法可能是最简单的机器学习算法,即给定一个已训练的数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,则判定该输入实例同属此类。
概念比较冗长,大致可以理解为如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,我个人简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。
这里我们直接调用opencv库中的KNN函数,使用较简单。该KNN匹配利用BF匹配后的数据进行匹配。
完整代码:
# coding:utf-8
import cv2
# 按照灰度图像读入两张图片
img1 = cv2.imread("/home/yc/Pictures/cat.jpg", cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread("/home/yc/Pictures/cat2.jpg", cv2.IMREAD_GRAYSCALE)
# 获取特征提取器对象
orb = cv2.ORB_create()
# 检测关键点和特征描述
keypoint1, desc1 = orb.detectAndCompute(img1, None)
keypoint2, desc2 = orb.detectAndCompute(img2, None)
"""
keypoint 是关键点的列表
desc 检测到的特征的局部图的列表
"""
# 获得knn检测器
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.knnMatch(desc1, desc2, k=1)
"""
knn 匹配可以返回k个最佳的匹配项
bf返回所有的匹配项
"""
# 画出匹配结果
img3 = cv2.drawMatchesKnn(img1, keypoint1, img2, keypoint2, matches, img2, flags=2)
cv2.imshow("cat", img3)
cv2.waitKey()
cv2.destroyAllWindows()
也许这里得到的结果与match函数所得到的结果差距不大,但二者主要区别是KnnMatch所返回的是K个匹配值,可以容许我们继续处理,而match返回最佳匹配。
以下为样图
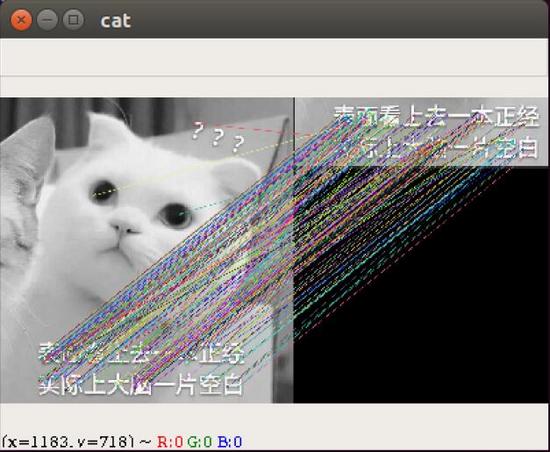
cat
实现简单的图像检索功能时,此类特征匹配算法对硬件的要求较低,效率较高,但是准确度有待考量
与一起学习opencv的同学共勉,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。