本文实例讲述了C#实现简单的Http请求的方法。分享给大家供大家参考。具体分析如下:
通过.Net中的两个类HttpWebRequest类,HttpWebResponse类来实现Http的请求,响应处理。
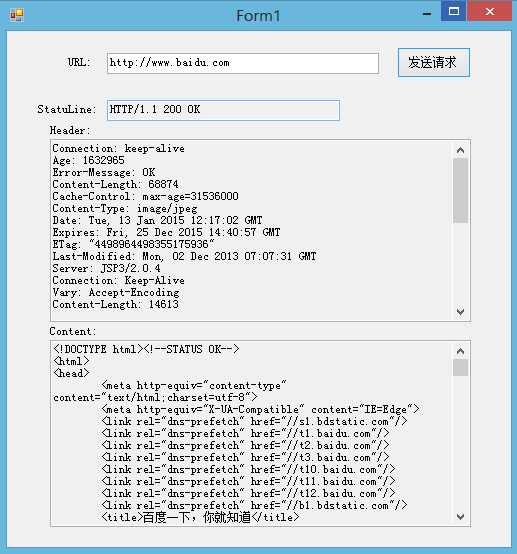
第一个小测试是请求百度首页(http://www.baidu.com)的内容,也就是要获得百度首页的html内容,
实现步骤:
1.通过WebRequest类创建一个HttpWebRequest的对象,该对象可以包含Http请求信息。
(这里有点供大家思考:为什么要通过父类WebRequest来创建这个对象,而不能new一个HttpWebRequest来创建,在HttpWebRequest类中的构造函数是:protected HttpWebRequest(SerializationInfo serializationInfo, StreamingContext streamingContext); )
2.设置HttpWebRequest对象,其实就是设置Http请求报文的信息内容。
3.从HttpWebRequest对象中获取HttpWebResponse对象,该对象包含Http响应信息。
4.从响应信息中获取响应头信息和响应主体信息。
部分实现代码如下:
创建HttpWebRequest请求,设置请求报文信息
string uri = http://www.baidu.com;
HttpWebRequest request = HttpWebRequest.Create(uri) as HttpWebRequest;
request.Method = "GET"; //请求方法
request.ProtocolVersion = new Version(1, 1); //Http/1.1版本
//Add Other ...
接收响应,输出响应头部信息以及主体信息
HttpWebResponse response=
request.GetResponse() as HttpWebResponse;
//Header
foreach (var item in response.Headers)
{
this.txt_Header.Text += item.ToString()+": " +
response.GetResponseHeader (item.ToString())
+ System.Environment.NewLine;
}
//如果主体信息不为空,则接收主体信息内容
if (response.ContentLength <= 0)
return;
//接收响应主体信息
using(Stream stream =response.GetResponseStream())
{
int totalLength=(int)response.ContentLength;
int numBytesRead=0;
byte[] bytes=new byte[totalLength+1024];
//通过一个循环读取流中的数据,读取完毕,跳出循环
while( numBytesRead < totalLength )
{
int num=stream.Read(bytes,numBytesRead,1024); //每次希望读取1024字节
if( num==0 ) //说明流中数据读取完毕
break;
numBytesRead+=num;
}
}
//将接收到的主体数据显示到界面
string content=Encoding.UTF8.GetString(bytes);
this.txt_Content.Text=content;
第二个小测试是请求网上的一张图片,并将图片保存到本地。
实现步骤与第一个小测试的非常类似,通过图片的url向服务器进行请求,然后接收响应,响应的主体信息内容保存为本地图片文件。一小点不同之处就在于需要将主体内容保存为文件形式,不是显示到界面上。
关键代码如下:
//...
string url="http://xx.xxx/xx.jpg"; //图片资源的url
//...
using (Stream stream = response.GetResponseStream())
{
//当前时间作为文件名
string fileName = DateTime.Now.ToString("yyyyMMddhhmmss")+".jpg";
using (Stream fsStream = new FileStream(fileName, FileMode.Create))
{
stream.CopyTo(fsStream);
}
}
附:运行结果如下图:
希望本文所述对大家的C#程序设计有所帮助。