桥
1. 割点与桥(割边)的定义
在无向图中才有割边和割点的定义
割点:无向连通图中,去掉一个顶点及和它相邻的所有边,图中的连通分量数增加,则该顶点称为割点。
桥(割边):无向联通图中,去掉一条边,图中的连通分量数增加,则这条边,称为桥或者割边。
割点与桥(割边)的关系:
1)有割点不一定有桥,有桥一定存在割点
2)桥一定是割点依附的边。
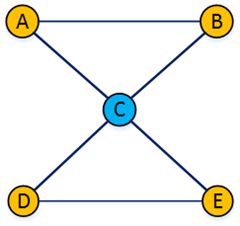
下图中顶点C为割点,但和C相连的边都不是桥。
2. 暴力解决办法解决求解割点集和割边集
暴力法的原理就是通过定义求解割点和割边。
在图中去掉某个顶点,然后进行DFS遍历,如果连通分量增加,那么该顶点就是割点。
如果在图中去掉某条边,然后进行DFS遍历,如果连通分量增加,那么该边就是割边。
对每个顶点或者每个边进行一次上述操作,就可以求出这个图的所有割点和割边,我们称之为这个图的割点集和割边集。
在具体的代码实现中,并不需要真正删除该顶点和删除依附于该顶点所有边。对于割点,我们只需要在DFS前,将该顶点对应是否已访问的标记置为ture,然后从其它顶点为根进行DFS即可。对于割边,我们只需要禁止从这条边进行DFS后,如果联通分量增加了,那么这条边就是割边。
这种方法的时间复杂度是O(N(N+M))。//执行N次DFS
3. Tarjan算法的原理
Robert Endre Tarjan是一个美国计算机学家,他传奇的一生中发明了无数算法,统称为Tarjan算法。其中最著名的有三个,分别用来求解 :
1) 无向图的双连通分量
2) 有向图的强连通分量
3) 最近公共祖先问题
判断一个顶点是不是割点除了从定义,还可以从DFS(深度优先遍历)的角度出发。
我们先通过DFS定义两个概念:
假设DFS中我们从顶点U访问到了顶点V(此时顶点V还未被访问过),那么我们称顶点U为顶点V的父顶点,V为U的孩子顶点。在顶点U之前被访问过的顶点,我们就称之为U的祖先顶点。
显然如果顶点U的所有孩子顶点可以不通过父顶点U而访问到U的祖先顶点,那么说明此时去掉顶点U不影响图的连通性,U就不是割点。相反,如果顶点U至少存在一个孩子顶点,必须通过父顶点U才能访问到U的祖先顶点,那么去掉顶点U后,顶点U的祖先顶点和孩子顶点就不连通了,说明U是一个割点。
结合代码举例
一个简单的例子
【有重边无向图求桥】
#include
using namespace std;
#define N 400001
#define M 400001
#define forw(i,x) for(int i = fir[x];i;i = ne[i])
#define PER(i,a,b) for(int i = a; i<= b; i++)
int n, m;
int ne[M], fir[M], val[M], to[M], root, fa[M], dfn[M], low[M];
int u, v;
int ans, cnt = 1;
bool vis[M];
void add(int u, int v) {
to[++cnt] = v;
ne[cnt] = fir[u];
fir[u] = cnt;
}
void dfs(int df, int no, int fae) {
dfn[no] = df;
vis[no] = 1;
low[no] = df;
forw(i, no) {
if(!vis[to[i]]) {
dfs(df+1, to[i], i);
low[no] = min(low[no], low[to[i]]);
if(low[to[i]] > dfn[no])
ans++;
}
else {
if(i != (fae^1))
low[no] = min(low[no], low[to[i]]);
}
}
}
int main() {
cout << "输入两个整数n, m,分别表示点数和边数:" << endl;
cin >> n >> m;
cout << "输入每一条边的起点和终点:" << endl;
PER(i, 1, m) {
cin >> u >> v;
add(u, v);
add(v, u);
}
root = 1;
dfs(1, root, -1);
cout << "桥的数量:" << endl;
cout << ans << endl;
} 测试样例
样例输入:
4 4
1 2
2 3
3 1
1 4
样例输出:
1 【原博客超链接】https://blog.csdn.net/Timsei/article/details/72773363
这道简单的求桥问题只使用了基准算法:
For every edge (u, v), do following
a) Remove (u, v) from graph
b) See if the graph remains connected (We can either use BFS or DFS)
c) Add (u, v) back to the graph.
接下来,题目要求使用并查集设计一个更加高效的算法。那么,现在来看看并查集。
并查集
并查集是一种树形结构,又叫“不相交集合”,保持了一组不相交的动态集合,每个集合通过一个代表来识别,代表即集合中的某个成员,通常选择根做这个代表。 也就是说,并查集是用来处理不相交集合类型问题,如问不相交集合有几个。给定节点,找到该节点所在集合元素个数。
并查集算法主要分三部分:
- 合并:给出两点关系,如果属于同一集合,进行merge
- 查:在合并时,需要先写出查,即找到该点的祖先点
- 集: merge后,将新加入的点的祖先点更新
- makeSet(s):建立一个新的并查集,其中包含 s 个单元素集合。
- unionSet(x, y):把元素 x 和元素 y 所在的集合合并,要求 x 和 y 所在的集合不相交,如果相交则不合并。
- find(x):找到元素 x 所在的集合的代表,该操作也可以用于判断两个元素是否位于同一个集合,只要将它们各自的代表比较一下就可以了。
然后,点集就因为共同的祖先点被分为不同的集合。
裸题模板:
hdu1232畅通工程
Problem Description
某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇。
省政府“畅通工程”的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道
路相连,只要互相间接通过道路可达即可)。问最少还需要建设多少条道路?
Input
测试输入包含若干测试用例。每个测试用例的第1行给出两个正整数,分别是城镇数目
N ( < 1000 )和道路数目M;随后的M行对应M条道路,每行给出一对正整数,分别是
该条道路直接连通的两个城镇的编号。为简单起见,城镇从1到N编号。
注意:两个城市之间可以有多条道路相通,也就是说
3 3
1 2
1 2
2 1
这种输入也是合法的
当N为0时,输入结束,该用例不被处理。
Output
对每个测试用例,在1行里输出最少还需要建设的道路数目。
Sample Input
4 2
1 3
4 3
3 3
1 2
1 3
2 3
5 2
1 2
3 5
999 0
0
Sample Output
1
0
2
998
##就是说将所有独立的集合连接起来还需要几条路,那只要找到独立集合个数-1就可以啦#include
#include
using namespace std;
int father[1005];
//查找x的父节点
int Find(int x) {
while(x != father[x]) {
x = father[x];
}
return x;
}
//找如果两个节点的父节点不一样,Combine起来
//一个变成另一个的父节点
void Combine(int a, int b) {
int fa = Find(a);
int fb = Find(b);
if(fa != fb) {
father[fa] = fb;
}
}
int main() {
int n, m;
int i;
int a, b;
while(~scanf("%d", &n)) {
if(n == 0)
break;
cin >> m;
int sum = 0;
for(i = 1; i <= n; i++) {
father[i] = i;
}
for(i = 0; i < m; i++) {
cin >> a >> b;
Combine(a, b);
}
for(i = 1; i <= n; i++) {
if(father[i] == i)
sum++;
}
cout << sum-1 << endl;
}
return 0;
}
并查集的伪代码:

再看一个引申题
The Suspects
Time Limit: 1000MS Memory Limit: 20000K
Total Submissions: 37109 Accepted: 17992
Description
Severe acute respiratory syndrome (SARS), an atypical pneumonia of unknown aetiology, was recognized as a global threat in mid-March 2003. To minimize transmission to others, the best strategy is to separate the suspects from others.
In the Not-Spreading-Your-Sickness University (NSYSU), there are many student groups. Students in the same group intercommunicate with each other frequently, and a student may join several groups. To prevent the possible transmissions of SARS, the NSYSU collects the member lists of all student groups, and makes the following rule in their standard operation procedure (SOP).
Once a member in a group is a suspect, all members in the group are suspects.
However, they find that it is not easy to identify all the suspects when a student is recognized as a suspect. Your job is to write a program which finds all the suspects.
Input
The input file contains several cases. Each test case begins with two integers n and m in a line, where n is the number of students, and m is the number of groups. You may assume that 0 < n <= 30000 and 0 <= m <= 500. Every student is numbered by a unique integer between 0 and n−1, and initially student 0 is recognized as a suspect in all the cases. This line is followed by m member lists of the groups, one line per group. Each line begins with an integer k by itself representing the number of members in the group. Following the number of members, there are k integers representing the students in this group. All the integers in a line are separated by at least one space.
A case with n = 0 and m = 0 indicates the end of the input, and need not be processed.
Output
For each case, output the number of suspects in one line.
Sample Input
100 4
2 1 2
5 10 13 11 12 14
2 0 1
2 99 2
200 2
1 5
5 1 2 3 4 5
1 0
0 0
Sample Output
4
1
1
题意是,一些学生被分组,0号可能感染病毒,跟他同一集合的也可能感染,
那么给出几个分组,问感染的人数。所以,0作为祖先节点,只要与0同集合
就将人数数组增加。
#include
#include
#define MAX 30005
using namespace std;
int a[MAX], pre[MAX];
int find(int x) {
if(x != pre[x])
pre[x] = find(pre[x]); //找到其祖先节点
return pre[x];
//由父节点继续向上递归查询 ,并将其父节点变成找到的
}
void Merge(int x, int y) {
//分别查询两点的祖先节点。
int prex = find(x);
int prey = find(y);
//如果二者的祖先节点不一致,
// 那么任意让二者中某一个认另一个为祖先,保证同集合。
if(prex == prey) {
return ;
}
//应该是祖先节点进行组合。而不是当前节点!
pre[prey] = prex;
a[prex] += a[prey];
}
int main() {
int n, m;
int k, x, y;
while(~scanf("%d%d",&n,&m)) {
if(n == 0 && m == 0) {
return 0;
}
for(int i = 0; i < n; i++) {
//将自身化为祖先节点
pre[i] = i;
a[i] = 1;
}
for(int i = 0; i < m; i++) {
//给出集合每个人集合人数,以及第一个人的编号
cin >> k >> x;
k--;
while(k--) {
cin >> y;
Merge(x, y);
}
}
cout << a[find(0)] << endl;
}
return 0;
}
/**
Sample Input
100 4
2 1 2
5 10 13 11 12 14
2 0 1
2 99 2
200 2
1 5
5 1 2 3 4 5
1 0
0 0
Sample Output
4
1
1
**/
未完待续。。。
参考链接
【并查集(模板&典型例题整理)】https://blog.csdn.net/oliver233/article/details/70162173
【并查集 及路径压缩】https://blog.csdn.net/u013486414/article/details/38682057
【并查集(Union-Find) 应用举例 --- 基础篇】https://blog.csdn.net/dm_vincent/article/details/7769159
【并查集(Union-Find)算法介绍】https://blog.csdn.net/dm_vincent/article/details/7655764
【Tarjan三大算法之双连通分量(割点,桥)】https://blog.csdn.net/fuyukai/article/details/51039788