9月20日,第四范式资深算法科学家@程晓澄 进行了一次直播分享《机器学习在推荐熊中的应用》;下面,是个人的干货总结 ~
注:直播回看地址https://v.douyu.com/show/oERALvEn3Pn71Vw0
一、推荐系统的诞生土壤和早期演进
1、推荐系统的诞生土壤
1)长尾理论的兴起:较长的尾部的受众群体可能超过头部
2)线下销售的二八法则:80%的利润来自20%的商品
3)互联网发布门槛和成本降低后,网站的业务情况取决于长尾内容的分发

2、什么是好的帖子:聪明才智+经验rank
1)产品经理和运营人员提供个人经验(是否最近更新、引入区间和置信度进行评估)
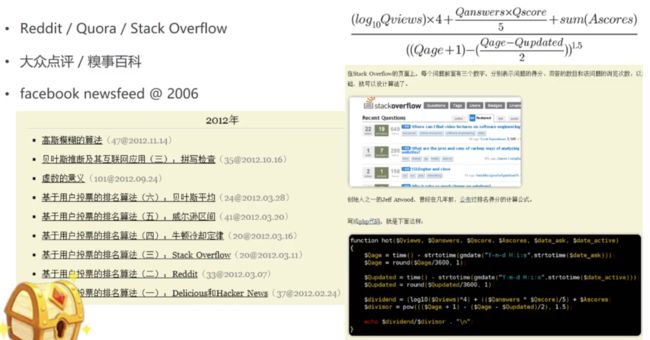
2)通过公式衡量的rank(根据网站拓扑图,和网站初始得分、收敛排名、跳出概率有关),作为当时衡量网站推广水平的重要指标。
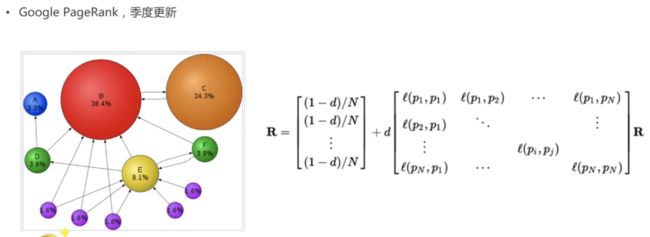
3、亚马逊的协同过滤
1)用户买过商品后,会有一定概率购买相似商品
(两个商品的相似通过评分矩阵来刻画;相似程度通过cos函数计算出来)
2)给用户推荐他朋友们喜欢的商品类别
(通过喜好相似度不同的朋友做加权平均计算;用cos函数的归一化解决打分标准不同的问题;peason系数去除打分本身的偏差)

4、经验评估和协同过滤的不足(需要有更丰富的假设并对用户的正负反馈进行自我修正、自我选择)
1)对用户喜好的假设条件不一定成立
2)不一定适用于每个用户和每一件商品item
3)每个item、category的权重和表达的信息含量可能不一样
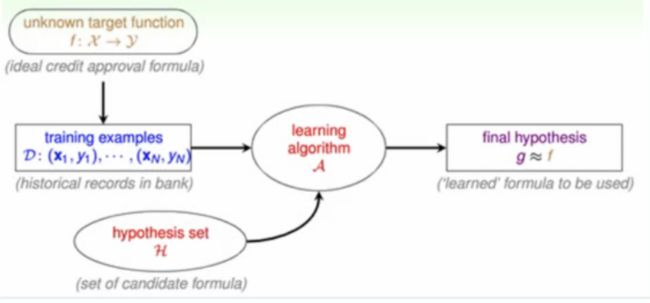
5、机器学习
1)f函数代表世界上的真理(未知的)可推断出用户的喜好
2)根据历史数据,有一个假设空间h,在算法A中搜索到最接近真理f的假设g
3)损失函数cost衡量g和f的接近程度
4)f函数可能代表点击率、观看时长、评分或其他量化体验或营收的值
6、矩阵分解的推荐方式
1)y代表用户对商品item的评分,根据u(用户id)和i(item id)
2)通过用户的喜好维度和商品自身的属性计算出用户的喜好程度
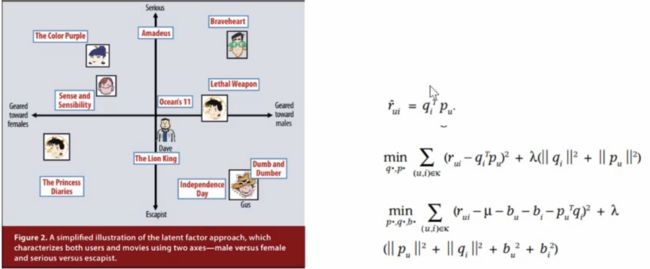
7、矩阵分解的局限
1)无法刻画新用户和新内容
2)无法利用用户的信息、内容的特征(可从线下经验中学习)
8、为机器学习模型注入更多的特征
1)猜想空间不限于公式、兴趣维度、rank方法(用户信息、商品信息、当前上下文信息,历史销售记录),每一种特征的权重由模型自己去学习
2)监督学习成为广告投放、搜索排序、电商内容推荐领域的核心引擎
二、推荐系统当下的基本架构
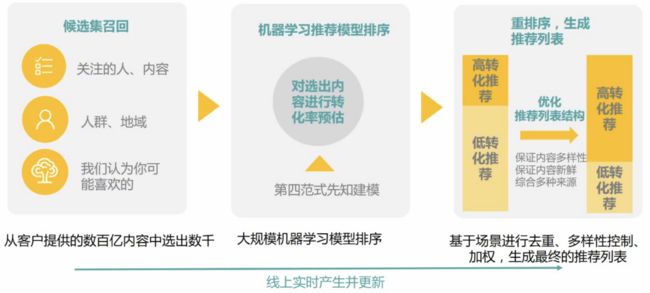
1、候选集召回
1)候选集内容达到百亿级甚至是千亿级(商品、内容、搜索结果),直接用模型计算时间成本比较高
2)初筛的方式:
-排序召回(最新、最热、最近、最新光顾、各种经验上的评分公式)
-简单模型、rank召回(item based/user based、矩阵分解)
-规则召回(天气、近期搜索浏览、朋友的购买、同期过往习惯等)
3)通过A/B test找到更好的初筛方式
2、模型排序
1)排序考虑更多的因素(时间、季节、运营者信息、连接方式、行为序列、社交关系、历史行为内容序列、GPS坐标、IP地址)
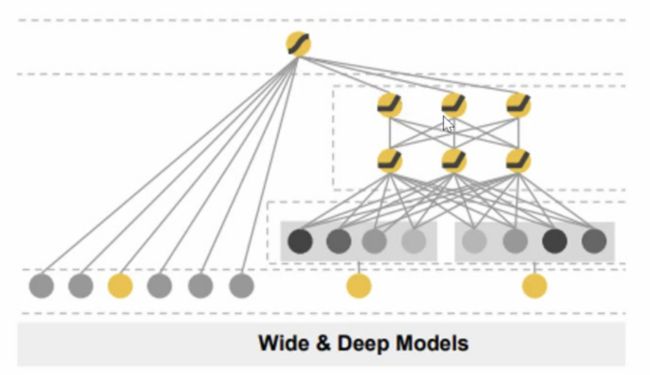
2)先进的排序模型:Wide&Deep Models
观看、收藏、购买、搜索序列(RNN)
图片信息(CNN)、文字信息(word2vec)
一般用前一层的hidden layer去做决策,为了得到更好的结果会把模型的思考结果分得更细。
3、生成推荐结果
仅对结果做排序用户无法满足,需进一步优化体验:
1)多样化
2)已知内容和用户可能不喜欢的新领域
3)准确性vs多样性vs新颖性
三、搭建一个推荐系统
1、线上请求
1)选择候选规则并过滤
2)通过模型获取参数并计算
3)根据多样化、去重规则生成推荐列表
4)内容不够展示时需要扩充召回范围填充内容
2、线下数据流闭环
1)根据全部候选集信息存储的表格做搜索并记录
2)用户特征和物品特征的拼接、行为反馈数据拼接到特征上
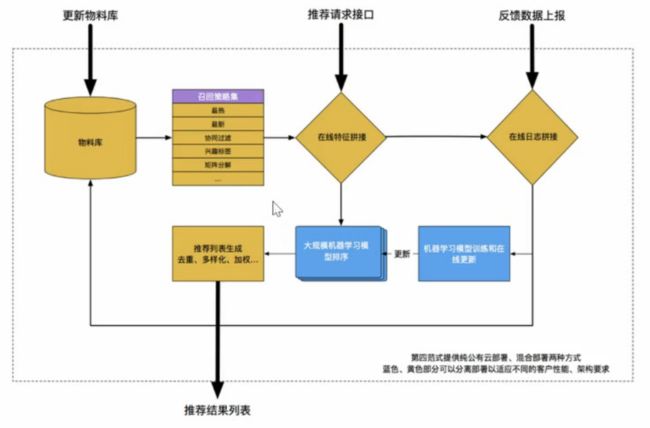
3、数据分析、算法实验
1)可响应产品、性能、算法需求的架构(不断迭代)
2)可同时进行大量实验的环境机制,用以获取丰富的数据
4、面临的挑战
1)速度方面:
-数据的增长不受技术限制,在有限时间内完成模型训练
-使用更多特征、更复杂的模型会提高效果,和成本之间如何取舍
-需要有专门为机器学习任务优化的计算框架
2)可扩展性方面:
-业务增长的速度不仅是量的增长,更是维度的增长(更多场景、更多用户和内容种类)
-快速发展的创业公司需要能匹配自己增长全周期的机器学习解决方案(做得早且效果好可以形成自己的壁垒)
5、研究方向
1)能收集到更真实无压力反馈的产品形式、交互设计
2)更多种类的特征:挖掘图像、音频、文本特征、Session类特征
特征工程:通过特征组合、特征变换,丰富假设空间
3)模型抽象与相匹配的优化算法
四、Q&A环节
1、当前最主流的推荐算法?
逻辑回归算法
前沿的应用:FTRL、LR(极其丰富的特征,简单线性模型,并发性能好以及并发训练实践上有较多积累)
2、对于一个没有什么其他用户交互信息的新用户,一般怎么做推荐?
用户访问到网站和app时有原始数据(手机类型、网络类型、GPS地理信息、社交账号信息),特征组合后识别出特定的人群,会有对应的统计特征
3、深度学习在推荐中的应用?
特定场景只能拿到很少的信息,可以通过深度学习挖掘未主动提供的信息(头像、颜值、直播的背景音乐风格、直播的内容、新闻的文本)
4、对于物料更新比较频繁的应用(比如新闻推荐),id类特征是否能提升效果?
从冷启动的角度,对信息丰富的用户做聚类,把新内容对他们随机分发,收集不同类型用户的反馈,得到新闻id更适合的人群,再用粗糙的规模做更大量的分发,过了分发初期后,模型能训练出更好的推荐结果。