3.58

屏幕快照 2018-02-26 上午9.43.34.png
/*
* x in %rdi, y in %rsi, z in %rdx
* subq %rdx, %rsi // y - z ==> y
* imulq %rsi, %rdi // x * y ==> x
* movq %rsi, %rax // y ==> %rax
* salq $63, %rax // << 63
* sarq $63, %rax // >> 63
* xorq %rdi, %rax // 这个时候的%rdi已经是x*y ^ %rax
* 因此可以得出结论 (x*y) ^ ((y-z) << 63 >> 63)
*/
long decode2(long x, long y, long z) {
return (x * y) ^ ((y - z) << 63 >> 63);
}
3.59

屏幕快照 2018-02-26 上午9.45.28.png
/*
根据提示:
x = 2^64 * x_h + x_l (x_h表示x的高64位,x_l表示x的低64位)
y = 2^64 * y_h + y_l (y_h表示y的高64位,y_l表示x的低64位)
x * y = (2^64 * x_h + x_l) * (2^64 * y_h + y_l)
= 2^64 * x_h * 2^64 * y_h + 2^64 * x_h * y_l + x_l * 2^64 * y_h + x_l * y_l
在上边这个表达式中2^64 * x_h * 2^64 * y_h明显已经越界,因此舍去,
x * y = 2^64(x_h * y_l + x_l * y_h) + (x_l * y_l)
上边的公式很重要,它表达的就是x*y的乘积的样式,根据p = 2^64 *p_h + p_l 再结合上边的公式
我们得出的结论是:
2^64(x_h * y_l + x_l * y_h) + (x_l * y_l) = 2^64 *p_h + p_l
那么2^64 *p_h = 2^64(x_h * y_l + x_l * y_h) + (x_l * y_l) - p_l
p_h = (x_h * y_l + x_l * y_h) + (x_l * y_l)/2^64 - p_l/2^64
(x_l * y_l)/2^64 表示相乘后右移64位正好是他们相乘后的高64位的值
p_l/2^64 则为0
因此我们就把任务简化了,我们接下来看汇编
dest in %rdi, x in %rsi, y in %rdx
stroe_prod:
movq %rdx, %rax // %rax = y, 此时y_l = %rax
cqto // 该命令的作用是把%rax中的符号位扩展到%rdx中,此时y_h = %rdx
movq %rsi, %rcx // 这行命令的作用是配合下一行获取x高64位的值
sarq $63, %rcx // 获取x的高64的值x_h = %rcx
imulq %rax, %rcx // 计算y_l * x_h = %rax * %rcx
imulq %rsi, %rdx // 计算y_h * x_l = %rdx * %rsi
addq %rdx, %rcx // 计算x_h * y_l + x_l * y_h的值
mulq %rsi // 该命令是计算%rax * %rsi的值,也就是x_l * y_l的值
addq %rcx, %rdx // 根据上边我们得出的结论,进行相加处理
*/
3.60

屏幕快照 2018-02-26 上午9.47.09.png
/*
我们先写出汇编的注释:
x in %rdi, n in %esi
loop:
movl %esi, %ecx // %ecx = n
movl $1, %edx // %edx = 1
movl $0, %eax // %eax = 0
jmp .L2 // 跳转到L2
.L3:
movq %rdi, %r8 // %r8 = x
andq %rdx, %r8 // %r8 &= %rdx
orq %r8, %rax // %rax |= %r8
salq %c1, %rdx // %rdx <<= %cl
.L2:
testq %rdx, %rdx // %rdx & %rdx
jne .L3 // if != jump to .L3
根据.L2我们可以得出的结论是如果%rdx的值为0 就继续循环
.L3中做了什么事呢?
我们知道%rdx的初始值为1,返回值%rax的值为0,那么.L3中的解释为:
1. x &= %rdx
2. %rax |= x
3. %rdx << n的低8位的值,也是为了保护位移
通过分析,我们就可以得出结论,该函数的目的是得出x中n的倍数的位掩码
答案:
A:
x --> %rdi
n --> %esi
result --> %rax
mask --> %rdx
B:
result = 0
mask = 1
C:
mask != 0
D:
mask <<= n
E:
result |= (x & mask)
F:
如下函数
*/
long loop(long x, int n) {
long result = 0;
long mask;
for (mask = 1; mask != 0; mask = mask << n) {
result |= (x & mask);
}
return result;
}
3.61

屏幕快照 2018-02-26 上午9.48.01.png
long cread(long *xp) {
return (xp ? *xp : 0);
}
long cread_alt(long *xp) {
return (!xp ? 0 : *xp);
}
3.62

屏幕快照 2018-02-26 上午9.48.53.png

屏幕快照 2018-02-26 上午9.49.05.png
typedef enum {MODE_A, MODE_B, MODE_C, MODE_D, MODE_E} mode_t;
long switch3(long *p1, long *p2, mode_t action) {
long result = 0;
switch(action) {
case MODE_A:
result = *p2;
*p2 = *p1;
break;
case MODE_B:
result = *p1 + *p2;
*p1 = result;
break;
case MODE_C:
*p1 = 59;
result = *p2;
break;
case MODE_D:
result = *p2;
*p1 = result;
result = 27;
break;
case MODE_E:
result = 27;
break;
default:
result = 12;
}
return result;
}
3.63

屏幕快照 2018-02-26 上午9.50.09.png
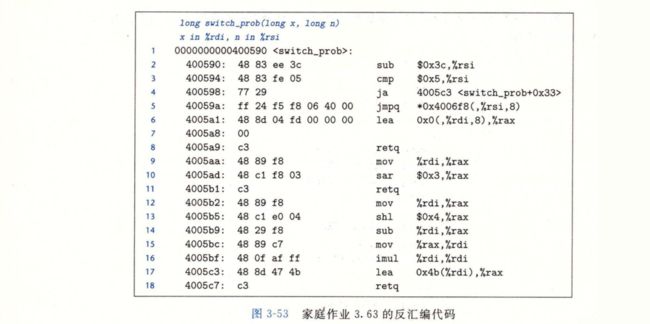
屏幕快照 2018-02-26 上午9.50.17.png
/*
sub $0x3c, %rsi // %rsi = n - 60
cmp $0x5, %rsi // 比较%rsi : 5
ja 4005c3 // 大于就跳转
jmpq *0x4006f8(,%rsi,8) // 这一行的目的是直接在跳转表中获取地址然后跳转
// 因此下边这些汇编代码就是对应跳转表中的地址
4005a1对应的index为0和2:
lea 0x0(,%rdi,8), %rax // result = 8x
4005c3对应的index为1,也就是case 1,通过观察,它用的就是default的指令
所以case 1 在switch中是缺失的
4005aa对应的index为3:
mov %rdi,%rax // result = x
sar $0x3,%rax // result >>= 3
也就是result = x / 8
4005b2对应的index为4:
mov %rdi,%rax // result = x
shl $0x4,%rax // result <<= 4
sub %rdi,%rax // result -= x
mov %rax,%rdi // x = result
也就是result = x * 15; x = result
4005bf对应的index为5:
imul %rdi,%rdi // x *= x
lea 0x4b(%rdi), %rax // result = 75 + x
经过上边的分析,就很容易得出结论了,但是别忘了要把index加上60
*/
long switch_prob(long x, long n) {
long result = x;
switch(n) {
case 60:
case 62:
result = 8 * x;
break;
case 63:
result = x / 8;
break;
case 64:
result = 15 * x;
x = result;
case 65:
x *= x;
default:
result = 75 + x;
}
return result;
}
3.64

屏幕快照 2018-02-26 上午9.51.10.png
设L为数组元素的大小,X_a表示数据的起始地址
&A[i][j][k] = X_a + L(i * S * T + j * T + k)
我们再进一步分析汇编代码:
i in %rdi, j in %rsi, k in %rdx, dest in %rcx
leaq (%rsi,%rsi,2), %rax // %rax = 3j
leaq (%rsi,%rax,4), %rax // %rax = 13j
movq %rdi, %rsi // %rsi = i
salq $6, %rsi // 结合上一条指令,%rsi = i << 6
addq %rsi, %rdi // %rdi = 65i
addq %rax, %rdi // %rdi = 65i + 13j
addq %rdi, %rdx // %rdx = 65i + 13j + k
movq A(,%rdx,8), %rax // %rax = *(A + 8(65i + 13j + k))
movq %rax, (%rcx) // *dest = *(A + 8(65i + 13j + k))
movl $3640, %eax // %rax = 3640
使用A + 8(65i + 13j + k)和最上边的公式对比后发现:
L: 8
T: 13
S: 5
要求出R还必须用到3640这个值
R * T * S * L = 3640
R = 3640 / 8 / 13 / 5 = 7
R: 7
3.65

屏幕快照 2018-02-26 上午9.52.10.png
我们先假设M为4,我们假设矩阵A为:
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
那么在用函数transpose处理之后,矩阵变成了
1 5 9 13
2 6 10 14
3 7 11 15
4 8 12 16
可以看出对矩阵沿着对角线进行了转换。我们继续看汇编代码
下边的汇编代码只是函数中内循环中的代码
.L6:
movq (%rdx), %rcx // %rcx = A[i][j]
movq (%rax), %rsi // %rsi = A[j][i]
movq %rsi, (%rdx) // A[i][j] = A[j][i]
movq %rcx, (%rax) // A[j][i] = A[i][j]
addq $8, %rdx // %rdx += 8
addq $120, %rax // %rax += 120
cmpq %rdi, %rax //
jne .L6 //
我们很容易就发现,指向A[i][j]的寄存器为%rdx,指向A[j][i]的寄存器为%rax
求M最关键的是找出%rax寄存器移动的规律,因为%rdx也就是A[i][j] + 8 就表示右移一位
而%rax则要移动M * 8位
因此M = 120 / 8 = 15
上边的寄存器%rdi应该放的就是i == j时的A[i][j]的地址
3.66

屏幕快照 2018-02-26 上午9.52.53.png
首先我们写出汇编代码的注释:
n in %rdi, A in %rsi, j in %rdx
sum_col:
leaq 1(,%rdi,4), %r8 // %r8 = 1 + 4n
leaq (%rdi,%rdi,2), %rax // %rax = 3n
movq %rax, %rdi // %rdi = 3n
testq %rax, %rax // 3n & 3n
jle .L4 // if <= 0 .L4
salq $3, %r8 // %r8 = (1 + 4n) << 3
leaq (%rsi,%rdx,8), %rcx // %rcx = 8j + A
movl $0, %eax // %rax = 0
movl $0, %edx // %rdx = 0
.L3:
addq (%rcx), %rax // %rax += *%rcx
addq $1, %rdx // %rdx += 1
addq %r8, %rcx // %rcx += (1 + 4n) << 3
cmpq %rdi, %rdx // %rdx : 3n
jne .L3
rep; ret
.L4:
movl $0, %eax // %rax = 0
ret
很明显,.L3上边的代码都是为循环准备数据的
如果n = 0 那么就直接返回result = 0
然后初始化局部变量%rdx保存i的值,%rax保存result的值,%rcx保存每一行j的地址,
然后进入循环体.L3
由%rdx : 3n可以看出打破循环的条件是 i == 3n 推导出:NR(n) = 3n
由%rcx += (1 + 4n) << 3可以看出,%rcx每次都移动了一行的宽度,也就是NC(n) = (1 + 4n) << 3
答案是:
NR(n) = 3n
NC(n) = (1 + 4n) << 3
3.67

屏幕快照 2018-02-26 上午9.53.41.png

屏幕快照 2018-02-26 上午9.53.55.png

屏幕快照 2018-02-26 上午9.54.04.png

屏幕快照 2018-02-26 上午9.54.12.png
我们先给汇编代码添加注释:
x in %rdi, y in %rsi, z in %rdx
eval:
subq $104, %rsp // 给栈分配了104个字节的空间
movq %rdx, 24(%rsp) // 把z的值保存在偏移量为24的位置
leaq 24(%rsp), %rax // %rax保存了z的指针
movq %rdi, (%rsp) // 把x的值保存在偏移量为0的位置
movq %rsi, 8(%rsp) // 把y的值保存在偏移量为8的位置
movq %rax, 16(%rsp) // 把z的指针值保存在偏移量为16的位置
leaq 64(%rsp), %rdi // 把偏移量为64的指针赋值给%rdi,当做参数传递给后边的函数
call process
movq 72(%rsp), %rax // 取出偏移量为72的值赋值给%rax
addq 64(%rsp), %rax // +
addq 80(%rsp), %rax // +
addq $104, %rsp // 恢复栈顶指针
ret
process:
movq %rdi, %rax // 把参数保存到%rax
movq 24(%rsp), %rdx // %rdx = &z 这里有点意思,当调用call后会把函数下边代码的地址压入栈中
movq (%rdx), %rdx // %rdx = z
movq 16(%rsp), %rcx // %rcx = y
movq %rcx, (%rdi) // 把y保存到偏移量为64 + 8 = 72的位置
movq 8(%rsp), %rcx // %rcx = x
movq %rcx, 8(%rdi) // 把x保存到偏移量为64 + 8 + 8 = 80的位置
movq %rdx, 16(%rdi) // 把z保存到偏移量为64 + 8 + 16 = 88的位置
ret
通过上边的注释,下边的问题就很清楚了
A:
----------- <-- 108
z
----------- <-- 24
&z
----------- <-- 16
y
----------- <-- 8
x
----------- <-- %rsp
B:
传递了一个相对于%rsp偏移量为64的指针
C:
直接使用偏移量来访问的s的元素
D:
直接设置偏移量
E:
----------- <-- 108
----------- <-- 88
z
----------- <-- 80
x
----------- <-- 72
y
----------- <-- 64 --- %rax
----------- <-- 32
z
----------- <-- 24
&z
----------- <-- 16
y
----------- <-- 8
x
----------- <-- %rsp
F:
通过这个例子,我们能够发现,如果把结构作为参数,那么实际传递的会是一个空的位置指针,函数把数据
存储在这个位置上,同时返回值也是这个指针。
3.68

屏幕快照 2018-02-26 上午9.54.57.png
p in %rdi, q in %rsi
setVal:
movslq 8(%rsi), %rax // %rax = *(8 + q)
addq 32(%rsi), %rax // %rax += *(32 + q)
movq %rax, 184(%rdi) //
这个问题算是非常简单的,由最后一条代码再加上str的结构,我们可以得出这样一个等式
4 * A * B + space = 184 由于对齐原则是保证8的倍数,分别假设space为7和0
==> 44 < A * B <= 46
%rax = *(8 + q) 可以推断出char array[B] 应该总共使用8个字节
因为需要考虑对齐原则,所以先得出 B <= 8
short s[A] %rax += *(32 + q)
我们t占用4个字节 ==> 4 + A * 2 <= 32 - 8 <= 24
于是我们有三个公式来做判断:
44 < A * B <= 46
B <= 8
A <= 10
那么A * B 的值只能是45 组合就是 5 * 9
由于 B <= 8 因此 B = 5 A = 9
我们再验证一番,short s[A] 由于对齐原则 占用了20个字节,跟汇编代码一致
答案:
A = 9
B = 5
3.69

屏幕快照 2018-02-26 上午9.55.52.png
i in %rdi, bp in %rsi
test:
mov 0x120(%rsi), %ecx // %rcx = *(288 + bp)
add (%rsi), %ecx // %rcx = *(288 + bp) + *bp
lea (%rdi,%rdi,4), %rax // %rax = 5 * i
lea (%rsi,%rax,8), %rax // %rax = 5 * i * 8 + bp
mov 0x8(%rax), %rdx // %rdx = *((5 * i * 8 + bp) + 8)
movslq %ecx, %rcx
mov %rcx, 0x10(%rax,%rdx,8) // &(16 + %rax + 8 * %rdx) = %rcx
retq
由 %rdx = (5 * i * 8 + bp) + 8 可以推导出 a_struct a[CNT] 每个元素占40个字节,first占8个字节
==>
CNT = (288 - 8) / 40 ==> CNT = 7
本题重点理解%rax 和 %rdx中保存的是什么的值,
%rax中保存的是ap的值,而%rdx中保存的是ap->idx的值,理解了这一层接下来就简单了
说明ap->idx保存的是8字节的值,根据 &(16 + %rax + 8 * %rdx) = %rcx 可以得出idx应该是结构体的第一个变量long idx
如果结构体占用了40个字节 , 那么数组x应该占用 40 - 8 也就是32个字节,每个元素占8个,可以容纳4个元素
typedef struct {
long idx;
long x[4];
}a_struct;
这个题目最重要的地方是理解mov 0x8(%rax), %rdx 这段代码,它是求ap->idx的值。
3.70

屏幕快照 2018-02-26 上午9.56.35.png
A:
0
8
0
8
B:
e1最多需要16个字节
e2最多需要16个字节
因此 总共需要16个字节
C:
up in %rdi
proc:
movq 8(%rdi), %rax // %rax = *(8 + up) 取出偏移量为8的地址
movq (%rax), %rdx // %rdx = *%rax 取出该地址中的值
movq (%rdx), %rdx // 取出指针指向的值
subq 8(%rax), %rdx // 用该值减去 *(%rax + 8)
movq %rdx, (%rdi) //
ret
一般来说 如果一个寄存器,比如说%rax 在下边的使用中用到了(%rax),我们就认定该寄存器保存的值为指针
movq 8(%rdi), %rax %rax保存了up偏移量为8的指针值,在该函数中偏移量为8还是指针的只能是e2的next
==> %rax = up -> e2.next
movq (%rax), %rdx %rdx 同样保存的是指针,对(%rax)取值得到的是up下一个unio的指针
==> %rdx = *(up -> e2.next)
movq (%rdx), %rdx 这行代码过后,%rdx就不再是指针了,是一个值,但运行之前,%rdx是个指针
==> %rdx = *(*(up -> e2.next) -> e2.p)
subq 8(%rax), %rdx 我们知道%rax是个指针 指向next +8后
==> 8(%rax) = *(up -> e2.next) -> e1.y
答案:
up -> e2.x = *(*(up -> e2.next) -> e2.p) - *(up -> e2.next) -> e1.y;
3.71

屏幕快照 2018-02-26 上午9.57.15.png
#include
#include
#define BUF_SIZE 12
void good_echo(void) {
char buf[BUF_SIZE];
while(1) {
/* function fgets is interesting */
char* p = fgets(buf, BUF_SIZE, stdin);
if (p == NULL) {
break;
}
printf("%s", p);
}
return;
}
int main(int argc, char* argv[]) {
good_echo();
return 0;
}
3.72

屏幕快照 2018-02-26 上午9.57.58.png

屏幕快照 2018-02-26 上午9.58.06.png
我们先画一画栈图:
----------
---------- <-- %rbp 0
---------- s1 <-- -16
e1
----------
p
---------- p
e2
---------- s2
A:
s2 = %rsp - 16 - (-16 & (8n + 30)) 由于s2 = %rsp - 16 所以
s2 = s1 - (-16 & (8n + 30))
这里的-16的十六进制表示为0xfffffff0,之所以用& 就是为了求16的整数倍
B:
p = (s2 + 15) & 0xfffffff0
C:
s2 = s1 - (0xfffffff0 & (8n + 30)) 根据这个公式
当n是偶数的时候,我们可以把式子简化为 s2 = s1 - (8 * n + 16)
当n是奇数的时候,我们可以把式子简化为 s2 = s1 - (8 * n + 24)
先求e1最小的情况
e1和e2是对立的关系,要想e1最小,那么e2就要最大,e2最大也就是15,
n是偶数的时候,e1 = 16 - 15 = 1 这个时候s1 % 16 == 1
e1最大的情况:
e2 == 0 时 e1最大, 当n是奇数的时候,e1 == 24 这个时候s1 % 16 == 0(p中多处了一个8字节)
D:
s2 确保能够容纳足够的p, p能够保证自身16对齐
3.73

屏幕快照 2018-02-26 上午9.58.50.png
#include
#include
typedef enum {NEG, ZERO, POS, OTHER} range_t;
range_t find_range(float x) {
__asm__(
"vxorps %xmm1, %xmm1, %xmm1\n\t"
"vucomiss %xmm1, %xmm0\n\t"
"jp .P\n\t"
"ja .A\n\t"
"jb .B\n\t"
"je .E\n\t"
".A:\n\t"
"movl $2, %eax\n\t"
"jmp .Done\n\t"
".B:\n\t"
"movl $0, %eax\n\t"
"jmp .Done\n\t"
".E:\n\t"
"movl $1, %eax\n\t"
"jmp .Done\n\t"
".P:\n\t"
"movl $3, %eax\n\t"
".Done:\n\t"
);
}
int main(int argc, char* argv[]) {
range_t n = NEG, z = ZERO, p = POS, o = OTHER;
assert(o == find_range(0.0/0.0));
assert(n == find_range(-2.3));
assert(z == find_range(0.0));
assert(p == find_range(3.33));
return 0;
}
3.74

屏幕快照 2018-02-26 上午9.59.29.png
#include
#include
typedef enum {NEG, ZERO, POS, OTHER} range_t;
range_t find_range(float x) {
__asm__(
"vxorps %xmm1, %xmm1, %xmm1\n\t"
"movq $1, %rax\n\t"
"movq $2, %r8\n\t"
"movq $0, %r9\n\t"
"movq $3, %r10\n\t"
"vucomiss %xmm1, %xmm0\n\t"
"cmovg %r8, %rax\n\t"
"cmove %r9, %rax\n\t"
"cmovpq %r10, %rax\n\t"
);
}
int main(int argc, char* argv[]) {
range_t n = NEG, z = ZERO, p = POS, o = OTHER;
assert(o == find_range(0.0/0.0));
assert(n == find_range(-2.3));
assert(z == find_range(0.0));
assert(p == find_range(3.33));
return 0;
}
3.75

屏幕快照 2018-02-26 上午10.00.10.png

屏幕快照 2018-02-26 上午10.00.19.png
这个题考察的是复数的概念
复数 = 实数 + 虚数
传参的时候,有这样的规律
(复数1, 复数2, 复数3...) 对应的浮点寄存器就会是:
%xmm0, %xmm1, %xmm2, %x
总结
看本章的过程当中,仿佛回到了大学时光,在读的的过程中,书本上的练习题做的还可以,但是感觉很多前边讲过的东西还是不太清楚,于是在读完后又重新读了一遍,在阅读第二遍的过程中, 注意到了很多细节,比如之前push 和 pop 有点迷惑,现在就非常清晰了
要想记住书本中的内容,看来还是要多读几遍。我感觉在该章中学到最多的是理解了c语言在机器代码级别的表示,对数据在内存中的操作更加了解了,不得不感慨编译器的强大,现在还感觉不出这些东西在实际工作中的用处,但对运行时栈的理解还是很有用的。
我已经把答案上传到了我的github中深入理解计算机系统(第三版)作业题答案(第三章)
在答题的过程中,我参考了这两个网站1 2
有错误的地方可以直接指出,欢迎讨论。