上次老师跟大家分享了 cookie、session和token,今天给大家分享一下Java 8中的Stream API。
Stream简介
1、Java 8引入了全新的Stream API。这里的Stream和I/O流不同,它更像具有Iterable的集合类,但行为和集合类又有所不同。
2、stream是对集合对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作,或者大批量数据操作。
3、只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
为什么要使用Stream
1、函数式编程带来的好处尤为明显。这种代码更多地表达了业务逻辑的意图,而不是它的实现机制。易读的代码也易于维护、更可靠、更不容易出错。
2、高端
实例数据源
public class Data {
private static List list = null;
static {
PersonModel wu = new PersonModel("wu qi", 18, "男");
PersonModel zhang = new PersonModel("zhang san", 19, "男");
PersonModel wang = new PersonModel("wang si", 20, "女");
PersonModel zhao = new PersonModel("zhao wu", 20, "男");
PersonModel chen = new PersonModel("chen liu", 21, "男");
list = Arrays.asList(wu, zhang, wang, zhao, chen);
}
public static List getData() {
return list;
}
}
Filter
- 遍历数据并检查其中的元素时使用。
- filter接受一个函数作为参数,该函数用Lambda表达式表示。

/**
* 过滤所有的男性
*/
public static void fiterSex(){
List data = Data.getData();
//old
List temp=new ArrayList<>();
for (PersonModel person:data) {
if ("男".equals(person.getSex())){
temp.add(person);
}
}
System.out.println(temp);
//new
List collect = data
.stream()
.filter(person -> "男".equals(person.getSex()))
.collect(toList());
System.out.println(collect);
}
/**
* 过滤所有的男性 并且小于20岁
*/
public static void fiterSexAndAge(){
List data = Data.getData();
//old
List temp=new ArrayList<>();
for (PersonModel person:data) {
if ("男".equals(person.getSex())&&person.getAge()<20){
temp.add(person);
}
}
//new 1
List collect = data
.stream()
.filter(person -> {
if ("男".equals(person.getSex())&&person.getAge()<20){
return true;
}
return false;
})
.collect(toList());
//new 2
List collect1 = data
.stream()
.filter(person -> ("男".equals(person.getSex())&&person.getAge()<20))
.collect(toList());
}
Map
- map生成的是个一对一映射,for的作用
- 比较常用
- 而且很简单

/**
* 取出所有的用户名字
*/
public static void getUserNameList(){
List data = Data.getData();
//old
List list=new ArrayList<>();
for (PersonModel persion:data) {
list.add(persion.getName());
}
System.out.println(list);
//new 1
List collect = data.stream().map(person -> person.getName()).collect(toList());
System.out.println(collect);
//new 2
List collect1 = data.stream().map(PersonModel::getName).collect(toList());
System.out.println(collect1);
//new 3
List collect2 = data.stream().map(person -> {
System.out.println(person.getName());
return person.getName();
}).collect(toList());
}
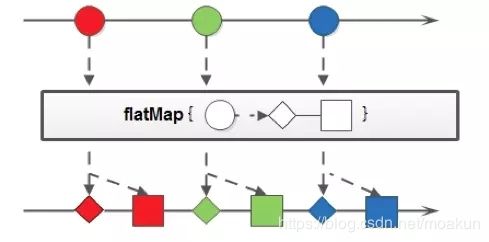
FlatMap
- 顾名思义,跟map差不多,更深层次的操作
- 但还是有区别的
- map和flat返回值不同
- Map 每个输入元素,都按照规则转换成为另外一个元素。
- 还有一些场景,是一对多映射关系的,这时需要 flatMap。
- Map一对一
- Flatmap一对多
- map和flatMap的方法声明是不一样的
Stream map(Function mapper); Stream flatMap(Function> mapper);
- map和flatMap的区别:我个人认为,flatMap的可以处理更深层次的数据,入参为多个list,结果可以返回为一个list,而map是一对一的,入参是多个list,结果返回必须是多个list。通俗的说,如果入参都是对象,那么flatMap可以操作对象里面的对象,而map只能操作第一层。
public static void flatMapString() {
List data = Data.getData();
//返回类型不一样
List collect = data.stream()
.flatMap(person -> Arrays.stream(person.getName().split(" "))).collect(toList());
List> collect1 = data.stream()
.map(person -> Arrays.stream(person.getName().split(" "))).collect(toList());
//用map实现
List collect2 = data.stream()
.map(person -> person.getName().split(" "))
.flatMap(Arrays::stream).collect(toList());
//另一种方式
List collect3 = data.stream()
.map(person -> person.getName().split(" "))
.flatMap(str -> Arrays.asList(str).stream()).collect(toList());
}
Reduce
- 感觉类似递归
- 数字(字符串)累加
- 个人没咋用过
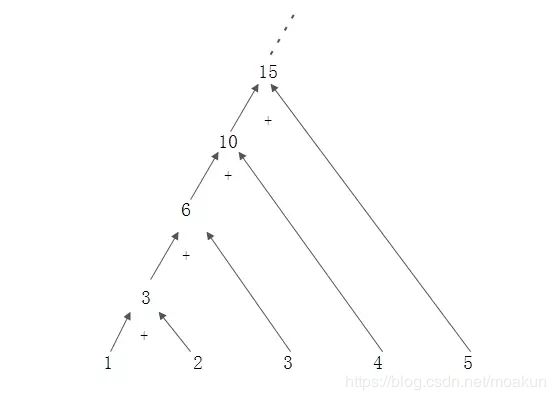
public static void reduceTest(){
//累加,初始化值是 10
Integer reduce = Stream.of(1, 2, 3, 4)
.reduce(10, (count, item) ->{
System.out.println("count:"+count);
System.out.println("item:"+item);
return count + item;
} );
System.out.println(reduce);
Integer reduce1 = Stream.of(1, 2, 3, 4)
.reduce(0, (x, y) -> x + y);
System.out.println(reduce1);
String reduce2 = Stream.of("1", "2", "3")
.reduce("0", (x, y) -> (x + "," + y));
System.out.println(reduce2);
}
Collect
- collect在流中生成列表,map,等常用的数据结构
- toList()
- toSet()
- toMap()
- 自定义
/**
* toList
*/
public static void toListTest(){
List data = Data.getData();
List collect = data.stream()
.map(PersonModel::getName)
.collect(Collectors.toList());
}
/**
* toSet
*/
public static void toSetTest(){
List data = Data.getData();
Set collect = data.stream()
.map(PersonModel::getName)
.collect(Collectors.toSet());
}
/**
* toMap
*/
public static void toMapTest(){
List data = Data.getData();
Map collect = data.stream()
.collect(
Collectors.toMap(PersonModel::getName, PersonModel::getAge)
);
data.stream()
.collect(Collectors.toMap(per->per.getName(), value->{
return value+"1";
}));
}
/**
* 指定类型
*/
public static void toTreeSetTest(){
List data = Data.getData();
TreeSet collect = data.stream()
.collect(Collectors.toCollection(TreeSet::new));
System.out.println(collect);
}
/**
* 分组
*/
public static void toGroupTest(){
List data = Data.getData();
Map> collect = data.stream()
.collect(Collectors.groupingBy(per -> "男".equals(per.getSex())));
System.out.println(collect);
}
/**
* 分隔
*/
public static void toJoiningTest(){
List data = Data.getData();
String collect = data.stream()
.map(personModel -> personModel.getName())
.collect(Collectors.joining(",", "{", "}"));
System.out.println(collect);
}
/**
* 自定义
*/
public static void reduce(){
List collect = Stream.of("1", "2", "3").collect(
Collectors.reducing(new ArrayList(), x -> Arrays.asList(x), (y, z) -> {
y.addAll(z);
return y;
}));
System.out.println(collect);
}
Optional
- Optional 是为核心类库新设计的一个数据类型,用来替换 null 值。
- 人们对原有的 null 值有很多抱怨,甚至连发明这一概念的Tony Hoare也是如此,他曾说这是自己的一个“价值连城的错误”
- 用处很广,不光在lambda中,哪都能用
- Optional.of(T),T为非空,否则初始化报错
- Optional.ofNullable(T),T为任意,可以为空
- isPresent(),相当于 !=null
- ifPresent(T), T可以是一段lambda表达式 ,或者其他代码,非空则执行
public static void main(String[] args) {
PersonModel personModel=new PersonModel();
//对象为空则打出 -
Optional
并发
- stream替换成parallelStream或 parallel
- 输入流的大小并不是决定并行化是否会带来速度提升的唯一因素,性能还会受到编写代码的方式和核的数量的影响
- 影响性能的五要素是:数据大小、源数据结构、值是否装箱、可用的CPU核数量,以及处理每个元素所花的时间
//根据数字的大小,有不同的结果
private static int size=10000000;
public static void main(String[] args) {
System.out.println("-----------List-----------");
testList();
System.out.println("-----------Set-----------");
testSet();
}
/**
* 测试list
*/
public static void testList(){
List list = new ArrayList<>(size);
for (Integer i = 0; i < size; i++) {
list.add(new Integer(i));
}
List temp1 = new ArrayList<>(size);
//老的
long start=System.currentTimeMillis();
for (Integer i: list) {
temp1.add(i);
}
System.out.println(+System.currentTimeMillis()-start);
//同步
long start1=System.currentTimeMillis();
list.stream().collect(Collectors.toList());
System.out.println(System.currentTimeMillis()-start1);
//并发
long start2=System.currentTimeMillis();
list.parallelStream().collect(Collectors.toList());
System.out.println(System.currentTimeMillis()-start2);
}
/**
* 测试set
*/
public static void testSet(){
List list = new ArrayList<>(size);
for (Integer i = 0; i < size; i++) {
list.add(new Integer(i));
}
Set temp1 = new HashSet<>(size);
//老的
long start=System.currentTimeMillis();
for (Integer i: list) {
temp1.add(i);
}
System.out.println(+System.currentTimeMillis()-start);
//同步
long start1=System.currentTimeMillis();
list.stream().collect(Collectors.toSet());
System.out.println(System.currentTimeMillis()-start1);
//并发
long start2=System.currentTimeMillis();
list.parallelStream().collect(Collectors.toSet());
System.out.println(System.currentTimeMillis()-start2);
}
调试
- list.map.fiter.map.xx 为链式调用,最终调用collect(xx)返回结果
- 分惰性求值和及早求值
- 判断一个操作是惰性求值还是及早求值很简单:只需看它的返回值。如果返回值是 Stream,那么是惰性求值;如果返回值是另一个值或为空,那么就是及早求值。使用这些操作的理想方式就是形成一个惰性求值的链,最后用一个及早求值的操作返回想要的结果。
- 通过peek可以查看每个值,同时能继续操作流
private static void peekTest() {
List data = Data.getData();
//peek打印出遍历的每个per
data.stream().map(per->per.getName()).peek(p->{
System.out.println(p);
}).collect(toList());
}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。