1. 引言
爬取20页美眉图片
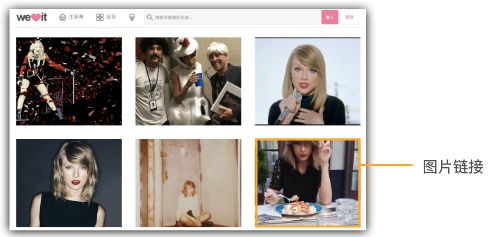
Paste_Image.png
网址: http://weheartit.com/inspirations/taylorswift
2. 分析
- 页面网址格式: http://weheartit.com/inspirations/taylorswift?page=1
页数即为最后1个数字
- 每个导航页中有24张图片的地址
- 指定系统中一个文件夹, 将图片下载保存至其中
- 每次下载前判断图片是否已经保存了
3. 实现代码
# vim spider_taylor.py //新建文件, 代码如下
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import os
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'
}
# 下载图片有点慢,用代理
proxies = {"http": "127.0.0.1:8118"}
# 定义列表用来存放图片地址
pic_lists = []
# 定义获取图片地址函数
def get_pic_from(url):
wb_data = requests.get(url, headers=headers)
if wb_data.status_code != 200:
print('%s Request Error!' % wb_data.status_code)
else:
soup = BeautifulSoup(wb_data.text, 'lxml')
links = soup.select('a.js-entry-detail-link > img')
for link in links:
pic_link = link.get('src')
# 每获取到一个地址,就放入列表pic_lists中
pic_lists.append(pic_link)
# 打印图片地址
print(pic_link)
# 定义下载图片函数
def down_pic_from(pic_url):
# 图片存放路径
file_folder = '/home/wjh/taylor/'
# 截取url中的图片名字,并将其和路径组合
file_path = file_folder + pic_url.split('/')[-2] + '.' + pic_url.split('.')[-1]
# 判断图片存在与否, 存在则输出其路径和大小
if os.path.exists(file_path):
print('"%s" File exists... : %d K' % (file_path, os.path.getsize(file_path)//1024))
else:
sub_data = requests.get(pic_url, proxies=proxies, headers=headers)
if sub_data.status_code != 200:
print('%s Request Error!' % sub_data.status_code)
# 保存图片
with open(file_path, 'wb') as fs:
fs.write(sub_data.content)
# 保存完后打印图片地址、路径、大小
print("%s => %s - %d K" % (pic_url, file_path, os.path.getsize(file_path)//1024))
# 所有要请求的页面地址存入一个列表中
urls = ['http://weheartit.com/inspirations/taylorswift?page={}'.format(i) for i in range(1, 21)]
# 获取图片地址列表
for url in urls:
get_pic_from(url)
# 从列表pic_lists中逐个取出图片地址放入下载函数中以下载图片
for url in pic_lists:
down_pic_from(url)
# python3 spider_taylor.py //运行输出如下
http://data.whicdn.com/images/247905262/superthumb.jpg
http://data.whicdn.com/images/247922201/superthumb.png
http://data.whicdn.com/images/247820953/superthumb.png
http://data.whicdn.com/images/120752508/superthumb.jpg
http://data.whicdn.com/images/127306344/superthumb.jpg
http://data.whicdn.com/images/247922493/superthumb.png
http://data.whicdn.com/images/247852730/superthumb.jpg
.
.
.
http://data.whicdn.com/images/247824232/superthumb.jpg
http://data.whicdn.com/images/246004790/superthumb.gif
http://data.whicdn.com/images/247923478/superthumb.jpg
.
.
.
"/home/wjh/taylor/189891880.gif" File exists... : 32 K
"/home/wjh/taylor/189891478.gif" File exists... : 60 K
"/home/wjh/taylor/222639313.gif" File exists... : 62 K
"/home/wjh/taylor/194658386.png" File exists... : 113 K
"/home/wjh/taylor/190061497.jpg" File exists... : 92 K
"/home/wjh/taylor/181241808.jpg" File exists... : 36 K
"/home/wjh/taylor/238329467.jpg" File exists... : 29 K
http://data.whicdn.com/images/247822005/superthumb.jpg => /home/wjh/taylor/247822005.jpg - 23 K
http://data.whicdn.com/images/247821899/superthumb.jpg => /home/wjh/taylor/247821899.jpg - 30 K
http://data.whicdn.com/images/247853275/superthumb.jpg => /home/wjh/taylor/247853275.jpg - 30 K
.
.
.
http://data.whicdn.com/images/247859540/superthumb.jpg => /home/wjh/taylor/247859540.jpg - 25 K
http://data.whicdn.com/images/247854181/superthumb.jpg => /home/wjh/taylor/247854181.jpg - 29 K
http://data.whicdn.com/images/247898534/superthumb.jpg => /home/wjh/taylor/247898534.jpg - 20 K
http://data.whicdn.com/images/247906728/superthumb.jpg => /home/wjh/taylor/247906728.jpg - 19 K
4. 总结
- with open方法有好几种:
-
r: 只读打开 -
w: 写打开 -
rb: 二进制只读打开 -
wb: 二进制写打开
-
- 用到的os.path几个方法:
- exists(): 判断文件在与否
- getsizes(): 判断文件大小, 单位是byte