【NLP篇】word2vec原理到应用(附Glove)
备:之前的文章中提到的word2vec,很多只是片面的提及而未做详细的总结。这篇对w2v的数学角度的原理及其应用做简要总结,以抛砖引玉。
1.word2vec是什么?
word2vec是google在2013年推出的一款获取word vector的工具包,简单、高效。其严格来说不输入深度学习范畴,只是浅层结构。
附:2篇原paper地址:
《Efficient Estimation of Word Representations in Vector Space》
《Distributed Representations of Words and Phrases and their Compositionality》
2.word2vec的原理
首先推荐个资料:《word2vec中的数学原理》
word2vec得到的结果是词向量,而词向量和语言模型又是密不可分的。至于语言模型参见《语言模型》篇的总结。
w2v的模型的原理主要有2种结构,CBOW(continue bag of words)和skip-gram。作者对两种模型给出的框架均基于HierHierical softmax 和 Negative sampling高效的训练方法。
- 1.skip-gram模型
在给定当前中心词的情况下,最大化上下文词的概率。
基本公式定义:
目标函数定义为所有位置的预测结果的乘积:

要最大化目标函数。对其取个负对数,得到损失函数——对数似然的相反数:
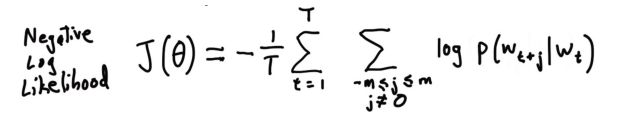
预测到的某个上下文条件概率p(wt+j|wt)可由softmax得到:
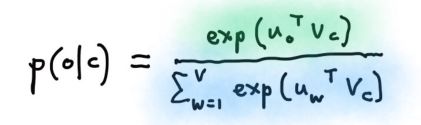
o是输出的上下文词语中的确切某一个,c是中间的词语。u是对应的上下文词向量,v是词向量。
下面的图的含义为,由中心词去预测周边词(上下文)
下图形象化展示由中心词预测上下文词的情况。窗口长度为2。

有了大致的概念后,疑问是,文字是如何变成向量的呢?
由stanford cs224n的课程讲解:
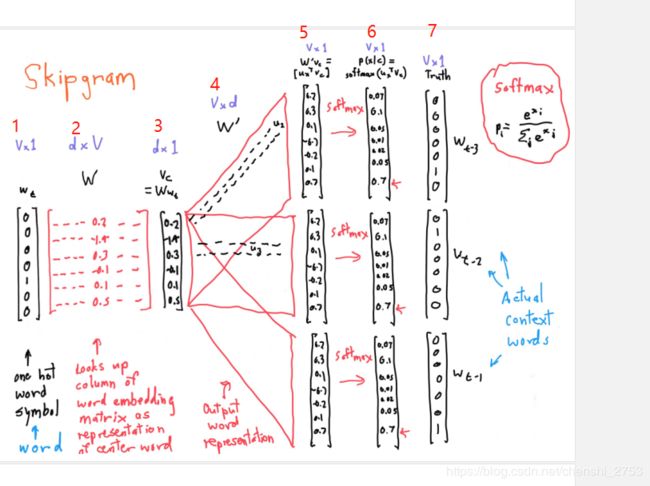
这幅图是对skip-gram讲解比较详细的。首先看下每个部分的含义,
1:词做one-hot编码。(这里注意,这只是作者操作时候的做法,在实际的工业街使用的时候还需要对one-hot做hashFeature作为w2v的输入)
2:中心词vector(这是随机初始化的,后面通过BP来学习不断更新)
3:得到的词向量。这是1和2做点积的结果,严格来说2和1做的点积结果。d*v . v * 1 = d * v(这里的d的设定可以理解成超参数,最开始训练需要设定,作者给定300时效果较好)相当于2中挑出来一列向量。
4:上下文vector(通过后面BP反向求参数)
5:为3和4做点积的结果作为词语的“相似度”,既中心词向量和上下文向量的结合。注意这里的向量都是一样的,一样的可能会引起疑问,有啥意义吗?其实作用是和7做对比,7是真实的值(省略了5经过softmax到6的过程)。看7中向量中1的位置和6中最大的0.7的位置差距就可以知道。目的是做反向修改2和4。以使得最后的6和7一样。就是反推的过程。
6:为5经过softmax的结果。
7:真实的上下文向量。
总结: 整体看就是一个词先做one-hot,然后输入到一个中心词的大矩阵中,得到的一个向量表示此词的中心词向量,然后让其和上下文向量点积得到的结果作为预选结果,然后经过softmax归一化后再与真实的上下文词做比较,对误差反向传播去更新预先随机初始化的中心词和上下文词向量。最后的让预测出来的上下文和真实的上下文尽可能接近。
备: 一个词由2组词向量构成,一个是其中心词向量一个是其上下文向量。
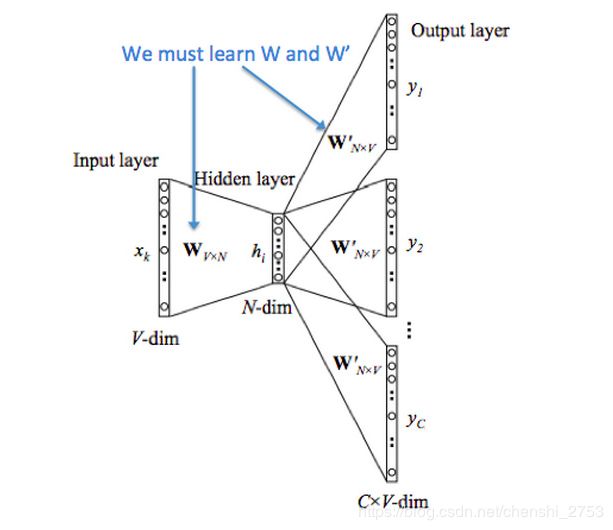
看完手写板,官方给的非手写板的如下;意思是一样的。
有关softmax的说明:
这里只是简单说softmax,但是在实际的使用中,softmax的计算量太大,而是采样基于Huffman编码的HierHierical softmax ,至于Huffman编码的内容,大学学过的信息论中有详细的说明,后面如果必要再单独详细写一篇文章总结。
还有一种方式是negative sampling,负例采样。
skip-gram mode:
![]()
negative sampling:
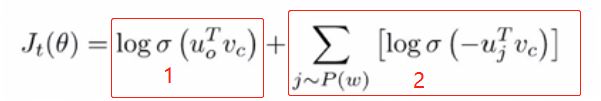
负例采样的形式,首先1是基本的形式。U可理解成上下文向量,v为中心词向量,两者做点积的目的是使得两者尽可能接近。点积就是衡量相近度的一种标准。2是带负例的形式,是对未采样到的以一定概率的采几个,然后让2最小,加上符号变成最大,以使得整体最大。
训练模型:计算参数向量的梯度
- 2.CBOW模型
CBOW和skip-gram是相反的过程,其由上下文预测中心词。
两种模型的对比:
由于skip-gram是一个个训练的,相当于多个老师对教一个学生,所以更能显示生僻词的差异。而cbow则相当于一个老师教多个学生,对生僻词的训练效果就没那么好。最后就是基于skip-gram的训练速度要比cbow慢许多。
Glove的原理
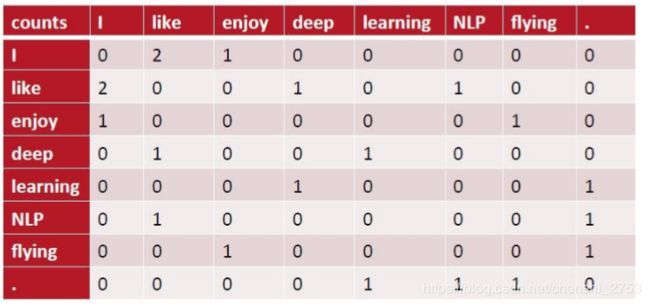
首先glove是基于统计共现矩阵的方式,
形式化如下图所示:
目标函数:
J ( θ ) = 1 2 ∑ i , j = 1 W f ( P i j ) ( u i T v j − l o g P i j ) 2 J(\theta ) = \frac{1}{2}\sum_{i,j=1}^{W}f(_{P_{ij}})({u_{i}}^{T}v_{j}-logP_{ij})^2 J(θ)=21i,j=1∑Wf(Pij)(uiTvj−logPij)2
解释:
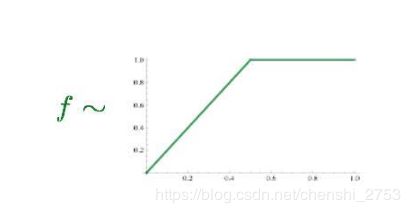
f函数是权重函数,作者给出的权重函数图像走势为先递增,然后平缓。如下图所示:
公式推导:
矩阵单词i的的那行: x i = ∑ j = 1 N x i j x_{i}=\sum_{j=1}^{N}x_{ij} xi=j=1∑Nxij
单词k出现在单词i语境中的概率:
p i , k = x i , k x i p_{i,k}=\frac{x_{i,k}}{x_{i}} pi,k=xixi,k
同样单词k出现在单词j语境中的概率:
p i , k = x j , k x j p_{i,k}=\frac{x_{j,k}}{x_{j}} pi,k=xjxj,k
那么定义条件概率:
r a d i o i , j , k = p i , k p j , k radio_{i,j,k}=\frac{p_{i,k}}{p_{j,k}} radioi,j,k=pj,kpi,k
通过实验发现规律:
| radioi,j,k的值 | j,k相关 | j,k不相关 |
|---|---|---|
| i,k相关 | 趋近1 | 很大 |
| j,k不相关 | 很小 | 趋近1 |
设计算 r a d i o i , j , k 的 函 数 为 g ( v i , v j , v k ) 则 p i , k p j , k = r a d i o i , j , k = g ( v i , v j , v k ) radio_{i,j,k}的函数为g(v_{i},v_{j},v_{k}) 则 \frac{p_{i,k}}{p_{j,k}}=radio_{i,j,k}=g(v_{i},v_{j},v_{k}) radioi,j,k的函数为g(vi,vj,vk)则pj,kpi,k=radioi,j,k=g(vi,vj,vk)
现在要使得两者尽可能接近:
J = ∑ i , j , k N ( p i , k p j , k − g ( v i , v j , v k ) ) 2 J=\sum_{i,j,k}^{N}(\frac{p_{i,k}}{p_{j,k}}-g(v_{i},v_{j},v_{k}))^2 J=i,j,k∑N(pj,kpi,k−g(vi,vj,vk))2
计算推导:
考虑单词i和单词j之间的关系:
假设: p i , k p j , k = e x p ( ( v i − v j ) T v k ) e x p ( v i T v k − v j T v k ) \frac{p_{i,k}}{p_{j,k}}=\frac{exp((v_{i}-v{j})^{T}v_{k})}{exp(v_{i}^Tv_{k}-v_{j}^Tv_{k})} pj,kpi,k=exp(viTvk−vjTvk)exp((vi−vj)Tvk)
= v i T v k v j T v k =\frac{v_{i}^Tv_{k}}{v_{j}^Tv_{k}} =vjTvkviTvk
= > p i , j = e x p ( v j , v j ) = > l o g p i , j = v i T v j =>p_{i,j}=exp(v_{j},v_{j})=>logp_{i,j}=v_{i}^Tv_{j} =>pi,j=exp(vj,vj)=>logpi,j=viTvj
= > J = ∑ i , j N ( l o g ( p i , j ) − v i v j ) 2 =>J=\sum_{i,j}^{N}(log(p_{i,j}) - v_{i}v_{j})^2 =>J=i,j∑N(log(pi,j)−vivj)2
证毕。