x86汇编程序基础(AT&T语法)
转自:
http://www.cnblogs.com/orlion/p/5765339.html
一、简单的汇编程序
以下面这段简单的汇编代码为例
![]()
.section .data .section .text .globl _start _start: movl $1, %eax movl $4, %ebx int $0x80
![]()
(注意是globl不是global;movl(MOVL)不是mov1(MOV一))
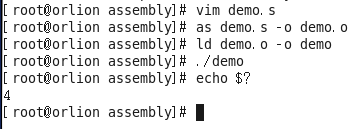
将这段程序保存为demo.s,然后用汇编器as把汇编程序中的助记符翻译成机器指令(汇编指令与机器指令是对应的)生成目标文件demo.o。然后用链接器ld把目标文件demo.o链接成可执行文件demo(虽然只有一个目标文件但是也需要经过链接才能成为可执行文件因为链接器要修改目标文件中的一些信息)。这个程序只做了一件事就是退出,退出状态为4。shell中可以echo $?得到上一条命令的退出状态。
【解释】:汇编程序中以"."开头的名称不是指令的助记符,不会被翻译成机器指令,而是给汇编器一些特殊的指示,称为汇编指示或伪操作。
.section .data .section .text
.section指示把代码划分成若干个段(section),程序被操作系统加载时,每个段被加载到不同的地址,具有不同的读写执行权限。
.data段保存程序的数据是可读写的,C程序的全局变量也属于.data段。上边的程序没定义数据所以.data是空的。
.text段保存代码,是只读和可执行的,后面那些指令都属于这个.text段。
.globl _start
_start是一个符号(Symbol),符号在汇编程序中代表一个地址,可以用在指令中,汇编程序经过汇编器的处理后所有的符号都被替换成它所代表的地址值。在C中我们可以通过变量名访问一个变量,其实就是读写某个地址的内存单元,我们通过函数名调用一个函数其实就是调转到该函数的第一条指令所在的地址,所以变量名和函数名都是符号,本质上是代表内存地址的。
.globl指示告诉汇编器_start这个符号要被链接器用到,所以要在目标文件的符号表中给它特殊标记。_start就像C程序的main函数一样特殊是整个程序的入口,链接器在链接时会查找目标文件中的_start符号代表的地址,把它设置为整个程序的入口地址,所以每个汇编程序都要提供一个_start符号并且用.globl声明。如果一个符号没有用.globl指示声明这个符号就不会被链接器用到。
_start:
_start在这里就像C语言的语句标号一样。汇编器在处理汇编程序时会计算每个数据对象和每条指令的地址,当汇编器看到这样一个标号时,就把它下面一条指令的地址作为_start这个符号所代表的地址。而_start这个符号又比较特殊事整个程序的入口地址,所以下一条指令movl $1, %eax就成了程序中第一条被执行的指令。
movl $1, %eax
这是一条数据传送指令,CPU内部产生一个数字1, 然后传送到eax寄存器中。mov后边的l表示long,说明是32位的传送指令。CPU内部产生的数称为立即数,在汇编程序中立即数前面加"$",寄存器前面加"%",以便跟符号名区分开。
movl $4, %ebx
与上条指令类似,生成一个立即数4,传送到ebx寄存器中。
int $0x80
前两条指令都是为这条指令做准备的,执行这条指令时:
1. int指令称为软中断指令,可以用这条指令故意产生一个异常。异常的处理与中断类似,CPU从用户模式切换到特权模式,然后跳转到内核代码中执行异常处理程序。
2. int指令中的立即数0x80是一个参数,在异常处理程序中根据这个参数决定如何处理,在linux内核中,int $0x80这种异常称系统调用(System Call)。内核提供了许多系统服务供用户程序使用,但这些系统服务不能像库函数(比如printf)那样调用,因为在执行用户程序时CPU处于用户模式不能直接调用内核函数,所以需要通过系统调用切换CPU模式,通过异常处理程序进入内核,用户程序只能通过寄存器传几个参数,之后就要按内核设计好的代码路线走,而不能由用户程序随心所欲想调那个内核函数,这样保证了系统服务被安全的调用,在调用结束后CPU再切换回用户模式,继续执行int指令后面的指令,在用户程序看来就像函数的调用和返回一样。
3. eax和ebx寄存器的值是传递给系统调用的两个参数,eax的值是系统调用号,1表示_exit系统调用,ebx的值则是传给_exit系统调用的参数,也就是退出状态。_exit这个系统调用会终止掉当前进程,而不会返回它继续执行。不同的系统调用需要的参数个数也不同,有的会需要ebx、ecx、edx三个寄存器的值做参数,大多数系统调用完成之后是会返回用户程序继续执行的,_exit系统调用特殊。
![]()
x86汇编的两种语法:intel语法和AT&T语法 x86汇编一直存在两种不同的语法,在intel的官方文档中使 用intel语法,Windows也使用intel语法,而UNIX平台的汇编器一 直使用AT&T语法,所以本书使用AT&T语法。 mov %edx,%eax 这条 指令如果用intel语法来写,就是 mov eax,edx ,寄存器名不加 % 号, 并且源操作数和目标操作数的位置互换。本书不详细讨论这两种 语法之间的区别,读者可以参考[AssemblyHOWTO]。 介绍x86汇编的书很多,UNIX平台的书都采用AT&T语法,例 如[GroudUp],其它书一般采用intel语法,例如[x86Assembly]。
![]()
二、x86的寄存器
x86的通用寄存器有eax、ebx、ecx、edx、edi、esi。这些寄存器在大多数指令中是可以任意使用的。但有些指令限制只能用其中某些寄存器做某种用途,例如除法指令idivl规定被除数在eax寄存器中,edx寄存器必须是0,而除数可以是任何寄存器中。计算结果的商数保存在eax寄存器中(覆盖被除数),余数保存在edx寄存器。
x86的特殊寄存器有ebp、esp、eip、eflags。eip是程序计数器。eflags保存计算过程中产生的标志位,包括进位、溢出、零、负数四个标志位,在x86的文档中这几个标志位分别称为CF、OF、ZF、SF。ebp和esp用于维护函数调用的栈帧。
esp为栈指针,用于指向栈的栈顶(下一个压入栈的活动记录的顶部),而ebp为帧指针,指向当前活动记录的底部。每个函数的每次调用,都有它自己独立的一个栈帧,这个栈帧中维持着所需要的各种信息。寄存器ebp指向当前的栈帧的底部(高地址),寄存器esp指向当前的栈帧的顶部(低地址)。
注意:ebp指向当前位于系统栈最上边一个栈帧的底部,而不是系统栈的底部。严格说来,“栈帧底部”和“栈底”是不同的概念;esp所指的栈帧顶部和系统栈的顶部是同一个位置。
三、第二个汇编程序
求一组数最大值的汇编程序:
![]()
.section .data data_items: .long 3,67,34,222,45,75,54,34,44,33,22,11,66,0 .section .text .globl _start _start: movl $0, %edi movl data_items(,%edi,4), %eax movl %eax, %ebx start_loop: cmpl $0, %eax je loop_exit incl %edi movl data_items(, %edi,4), %eax cmpl %ebx, %eax jle start_loop movl %eax, %ebx jmp start_loop loop_exit: mov $1, %eax int $0x80
![]()
汇编链接执行,然后echo $?会看到输出222。
这个程序在一组数中找到一个最大的数,并把它作为程序的退出状态。这段数在.data段给出:
data_items: .long 3,67,34,222,45,75,54,34,44,33,22,11,66,0
.long指示声明一组数,每个数32位,相当于C数组。数组开头有个标号data_items,汇编器会把数组的首地址作为data_items符号所代表的地址,data_items类似于C中的数组名。data_items这个标号没有.globl声明是因为它只在这个汇编程序内部使用,链接器不需要知道这个名字的存在。除了.long之外常用的声明:
- .byte,也是声明一组数,每个数8位
- .ascii,例: .ascii "Hello World",声明了11个数,取值为相应字符的ASCII码。和C语言不同的是这样声明的字符串末尾是没有'\0'字符的。
data_items数组的最后一个数是0,我们在一个循环中依次比较每个数,碰到0的时候就终止循环。在这个循环中:
- edi寄存器保存数组中的当前位置,每次比较完一个数就把edi的值加1,指向数组中的下一个数。
- ebx寄存器保存到目前为止找打的最大值,如果发现有更大的数就更新ebx的值。
- eax寄存器保存当前要比较的数,每次更新edi之后,就把下一个数读到eax中。
_start: movl $0, %edi
初始化edi,指向数组的第0个元素。
movl data_items(,%edi,4), %eax
这条指令把数组的第0个元素传送到eax寄存器中。data_items是数组的首地址,edi的值是数组的下标,4表示数组的每个元素占4字节,那么数组中第edi个元素的地址应该是data_items+edi*4。从这个地址读数据,写成指令就是上面那样。
movl %eax, %ebx
ebx的初始值也是数组的第0个元素。
下面进入一个循环,在循环的开头用标号start_loop表示,循环的末尾之后用标号loop_exit表示。
start_loop: cmpl $0, %eax je loop_exit
比较eax的值是不是0,如果是0就说明到了数组末尾了,就要跳出循环。cmpl指令将两个操作数相减,但计算结果并不保存,只是根据计算结果改变eflags寄存器中的标志位。如果两个操作数相等,则计算结果为0,eflags中的ZF位置1。je是一个条件跳转指令,它检查eflags中的ZF位,ZF位为1则发生跳转,ZF位为0则不跳转继续执行下一条指令。(条件跳转指令和比较指令是配合使用的)je的e就表示equal。
incl %edi movl data_items(,%edi,4), %eax
将edi的值加1,把数组中的下一个数组传送到eax寄存器中。
cmpl %ebx, %eax jle start_loop
把当前数组元素eax和目前为止找到的最大值ebx做比较,如果前者小于等于后者,则最大值没有变,跳转到循环开头比较下一个数,否则继续执行下一条指令。jle也是一个条件跳转指令,le表示less than or equal。
movl %eax, %ebx jmp start_loop
更新了最大值ebx然后跳转到循环开头继续比较下一个数。jmp是一个无条件跳转指令,什么条件也不判断直接跳转。loop_exit标号后面的指令用_exit系统调用来退出程序。
四、寻址方式
访问内存时在指令中可以用多种方式表示内存地址。内存寻址在指令中可以表示成如下的通用格式:
ADDRESS_OR_OFFSET(%BASE_OR_OFFSET,%INDEX,MULTIPLIER)
它所表示的地址可以这样计算出来:
FINAL ADDRESS = ADDRESS_OR_OFFSET + BASE_OR_OFFSET + MULTIPLIER * INDEX
其中ADDRESS_OR_OFFSET和MULTIPLIER必须是常数,BASE_OR_OFFSET和INDEX必须是寄存器。在有些寻址方式中会省略这4项中的某些项,相当于这些项是0。
- 直接寻址:只使用ADDRESS_OR_OFFSET寻址,例如movl ADDRESS, %eax把ADDRESS地址处的32位数传送到eax寄存器。
- 变址寻址:movl data_items(,%edi,4), %eax就属于这种方式,用于访问数组很方便
- 间接寻址:只使用BASE_OR_OFFSET寻址,例如movl (%eax), %ebx,把eax寄存器的值看作地址,把这个地址处的32位数传送到ebx寄存器。
- 基址寻址:只使用ADDRESS_OR_OFFSET和BASE_OR_OFFSET寻址,例如movl 4(%eax), %ebx,用于访问结构体成员比较方便,例如一个结构体的基地址保存在eax寄存器中,其中一个成员在结构体内偏移量是4字节,要把这个成员读上来就可以用这条指令。
- 立即数寻址:就是指令中有一个操作数是立即数,例:movl $3, %eax。
- 寄存器寻址:就是指令中有一个操作数是寄存器。在汇编程序中寄存器用助记符来表示,在机器指令中则要用几个Bit表示寄存器的编号,这几个Bit与可以看做寄存器的地址,但是和内存地址不在一个地址空间。
关于汇编程序的Hello World可以参看我的另一篇文章:http://www.cnblogs.com/orlion/p/5316519.html