OpenCL浅析(2)- 对象与API
OpenCL规范
OpenCL规范由四个模型组成,分别是平台模型、执行模型、存储模型和编程模型。
平台模型
OpenCL平台框架由两个部分组成:主机和从设备。主机在异构计算中扮演者管理者和命令传达者的角色,从设备扮演计算具体任务的角色。
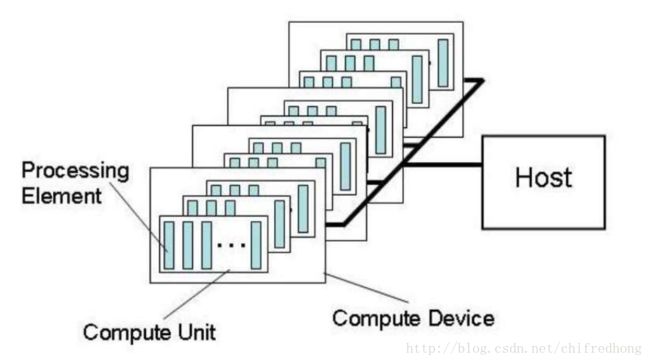
每个设备由一个或多个CU(计算单元)组成
每个计CU被进一步划分为一个或多个PE(处理元素),PE是OpenCL设备进行计算的最小单元
OpenCL应用是通过主机代码和设备执行代码实现的,主机选择特定的从设备,并建立相应的执行环境,然后将从设备执行的代码和数据通过PCIe接口发送给设备,设备同时调用内部多个计算单元进行数据计算,等待计算完成后,主机读取结果,结束任务,释放对象。
GPU和FPGA设备对应的逻辑单元到物理单元的映射
| GPU | FPGA | |
|---|---|---|
| PE | core或者SP(流处理单元) | 单条流水线电路的某次迭代 |
| CU | SM(流处理器簇) | 单条流水线电路的整个NDRange的范围的迭代 |
执行模型
由于平台模型是主从架构,因此,执行模型中的真正执行代码的过程也分为主机程序和设备内核程序,设备内核程序也被称为kernel。
主机程序负责定义平台对象、设备对象、命令队列对象、程序对象、缓存对象等数据结构,这些对象构成了OpenCL环境,通常作为API调用指针传递的参数。
kernel是OpenCL的核心概念,它是一个用OpenCL C语言编写的函数。用__kernel限定符修饰,通常没有返回值,即__kernel void MyKernel()形式,它是并发执行的最小单元。而执行一个kernel的逻辑节点称为work item,运行时,这些work item映射到底层的硬件结构上,比如一个CPU core或一个GPU core。
为了有效区分和管理work item,OpenCL将这些work item与一个带有索引号的工作空间映射起来,这个工作空间称为NDRange。NDRange的最大维度为3,通常,work-item每个维度的索引号都是从0开始。为了提高灵活性,OpenCL规范允许开发者对NDRange提供不同粒度的划分,它允许将几个work-item集合成一个工作小组,称为work-group,每个工作组有自己的索引号,称为work group ID。这样,每个work-item有了两个索引号,一个是global ID,另一个是work group ID,这两个索引号有着严格的数学关系。从一个ID可以推出另一个ID。一个work group可并发运行在一个CU上 。
cuda中的名词与OpenCL对应关系:
Block: 相当于opencl 中的work-group
Thread:相当于opencl 中的work-item
存储模型
OpenCL将设备中的存储分为四级,分别是全局内存、常量内存、局部内存、私有内存四层存储模型,对FPGA来说,全局内存放DRAM中,常量内存如果在kernel函数中定义,则存放在ROM中,如果是主机中定义的内存常量并传输到设备中,FPGA会在DRAM中开辟一块内存专门存放这些变量,局部内存和私有内存放在BRAM块和寄存器中。
1、全局内存:
一旦将数据从主机传输到设备,就会将其存储于全局设备内存中。如果是从设备传输到主机中,就会存储在主机内存中。它能被NDRange中所有的work-item读写,在四层存储模型中容量最大,但是读写速度最慢。
全局内存用 __global限定符修饰,通常OpenCL编译器建议全局变量使用restrict关键字修饰,该关键字用于告知编译器,所有修改该指针所指向内容的操作全部都是基于该指针的,即不存在其它进行修改操作的途径。
2、常量内存
常量内存是用__const限定符修饰的变量存储的位置,这类变量在定义时就初始化。他能被NDRange中所有work-item读,不能进行写操作。可以在主机代码中定义传输,也可以在kernel中定义,在整个kernel执行过程中保持不变。
3、局部内存
局部内存用__local限定符修饰的变量存储的位置。同一个work group中的所有work item都可以进行读写操作。但是对其他work group中的work item是不可见的,既可以在kernel内部定义也可以作为参数传输给kernel。
4、私有内存
kernel中默认的变量都是存储在私有内存中。它是单个work item的专属内存,其他的work item(不论是否在同一个work group中),不可以在主机中初始化或作为参数传输给kernel。

主机与OpenCL设备之间进行数据传输的方式有两种:拷贝和内存映射。
OpenCL规范规定了一个宽松的内存一致性,换句话说,就是它不保证所有work item访问的内存状态是一致的。
- work-item内部内存操作是必须是有序的:即按照代码顺序进行,硬件和编译器不会对同一个地址的读写操作重新排序。
- 同一个work group内的work item,只有在barrier操作(OpenCL的数据同步命令)处保证内存一致性。
- 在work group之间的work item,在kernel执行完成之前,不保证内存一致性。
编程模型
OpenCL编程模型是指对一个具体的任务,为了最大化并行执行效率而提出的实现模型。编程模型分为数据并行和任务并行两种,数据并行是指当大量的数据执行相同的操作,并且这些数据关联度很低,可以通过取不同的数据,在多个work item上执行相同的指令,完成指定的计算。任务并行是指NDRange内的每个work item执行kernel程序时,与其他的节点是相互独立的,可以执行不同的指令。因此,可以定义多个kernel程序来实现任务并行。
单个work group内的数据同步是通过local fence来实现的,工作组之间的数据是无法动态同步的。
在同一个上下文中的不同命令队列之间,OpenCL提供了事件对象进行同步。
不同上下文或者说不同设备之间的命令队列,则不能使用事件同步,OpenCL提供了clFlush和clFinish函数来保证之前的命令执行完毕。
由于不同work item的执行顺序不确定时,客户为不同的work item定义同步点,主要用于保证数据的一致性。同步问题分为设备端同步和主机端同步。
设备端同步
设备端同步又分为组内同步和全局同步。
1、组内同步
OpenCL的执行模型规定,每个work-item的执行是相互独立的。因此不同work-item对局部内存和全局内存的读写操作的顺序没有保证。组内同步的方法是调用barrier函数,保证所有的work-item都到达barrier后才继续执行。
2、全局同步
全局同步只定义在kernel执行的边界。也就意味着,所有work-group在kernel函数的右括号处不再继续执行,而不同work-group内的两个work-item的执行顺序无法保证。但OpenCL通过global fence保证对全局内存的访问控制。
主机端同步
- 调用clFinish函数,clFinish函数将阻塞程序的执行直到命令队列中的所有命令都执行完成。
- 等待一个特定的事件完成,函数原型clWaitForEvents(cl_uint num_events_in_wait_list , cl_event* event_wait_list)
- 执行阻塞访存工作,clEnqueueReadBuffer()函数中的CL_TRUE参数。在数据拷贝完成之前,该函数将一直阻塞。
1、初始化OpenCL环境相关的对象
1、平台对象和设备
OpenCL平台对象的类型是cl_platform_id,使用clGetPlatformIDs函数获取。设备对象的类型是cl_device_id,使用clGetDeviceIDs函数获取。设备对象依赖于平台对象,而后续的上下文对象又依赖于设备对象。
2、上下文
上下文是OpenCL的一个数据对象,OpenCL数据类型是cl_context。它是一个设备和命令队列的容器,初始化OpenCL的执行环境就是通过API调用将设备对象、程序对象、内核对象和命令队列对象都关联到这个上下文对象中。新建上下文对象的API函数是clCreateContext。
3、命令队列
命令队列为主机向从设备消息发送请求的一个行为机制。命令队列的类型是cl_command_queue,使用clCreateCommandQueue函数创建。一旦主机搜索到并定义设备对象,就可以将设备对象作为这个函数参数,建立了上下文对象。命令队列对象分为几个类型,分别是内存读写命令、内核执行命令、同步命令等三个类型。
- 内存读写命令:主机和OpenCL设备之间传输数据,在主机地址空间和OpenCL内存对象之间进行映射与解映射。
- 内核执行命令:在OpenCL设备上开始执行内核。
- 同步命令:控制命令执行的顺序。
注意,每个命令队列只关联一个设备。
4、程序对象
程序对象实际上是设备执行代码文件编译后的二进制文件,它是kernel函数的集合,程序对象的类型是cl_program,使用clCreateProgramWithSource 或clCreateProgramWithBinary创建,并且使用clBuildProgram在线编译。
5、内核对象
内核对象是kernel函数体抽象出来的类型,类型标识符是cl_kernel。使用clCreateKernel函数创建
6、buffer对象
从传统CPU的意义上看,buffer对象很像使用malloc函数或者new函数创建的一维数组,它在内存中是连续存储的。buffer对象的类型是cl_mem,使用clCreateBuffer函数创建,可以使用sizeof操作符获取buffer的大小。任何时候,只要是新建的buffer对象,它都只在一个上下文中有效。
7、事件对象
任何被作为一个命令入队到一个命令队列中的操作——即任何以clEnqueue字符开头的API函数,都会产生一个事件,事件类型标识符是cl_event。事件对象通常作为参数传递给clEnqueue字符开头的API函数,表明事件对象与clEnqueue类型的函数关联,如果函数同时将事件等待列表作为参数,那么等待事件列表里的关联的所有事件关联的函数执行完毕后,当前函数才执行。
OpenCL API函数
可以分为三种类型的API,分别是初始化OpenCL环境相关的API,执行内核代码相关的API以及释放OpenCL对象相关的API。
一、初始化OpenCL环境
1、获得可用平台列表的API函数。返回值是一个cl_int类型
cl_int clGetPlatformIDs( cl_uint num_entries,
cl_platform_id *platforms,
cl_uint *num_platforms)- num_entries :可以添加到平台的cl_platform_id条目的数量。如果平台不为空,则num_entries必须大于零。
- platforms 返回一个找到的opencl平台列表。平台中返回的cl_platform_id值可用于标识特定的opencl平台。如果platforms参数为NULL,则此参数将被忽略。返回的opencl平台的数量是由num_entries指定的值或可用的opencl平台数量的最小值。
- num_platforms 返回可用的opencl平台数。如果num_platforms为null,则此参数将被忽略。
2、获取平台上可用的设备列表。返回值是一个cl_int类型
cl_int clGetDeviceIDs( cl_platform_id platform,
cl_device_type device_type,
cl_uint num_entries,
cl_device_id *devices,
cl_uint *num_devices)- platform: 指的是由clGetPlatformIDs返回的cl_plaform_id类型的变量,或者可以为null。如果platform为null,那么行为是实现定义的。
- device_type: 一个标识opencl设备类型的字段。 device_type可用于查询特定的opencl设备或所有可用的opencl设备。可以是CL_DEVICE_TYPE_CPU、CL_DEVICE_TYPE_CPU或CL_DEVICE_TYPE_ACCELERATOR等等。
-devices : 一个opencl设备列表。设备中返回的cl_device_id值可用于标识特定的opencl设备。如果devices参数为空,则忽略此参数。返回的opencl设备的数量是由num_entries指定的值的最小值或类型与device_type匹配的opencl设备的数量。 - num_devices 与device_type匹配的可用的opencl设备的数量。如果num_devices为空,则忽略此参数。
3、创建一个上下文,返回值是上下文类型。典型的调用是指定num_devices和devices指针,其他值可以设置为NULL。
cl_context clCreateContext( cl_context_properties *properties,
cl_uint num_devices,
const cl_device_id *devices,
void *pfn_notify (
const char *errinfo,
const void *private_info,
size_t cb,
void *user_data
),
void *user_data,
cl_int *errcode_ret)- pfn_notify :可以由应用程序注册的回调函数。这个回调函数将被opencl实现用于报告在这个上下文中发生的错误的信息。这个回调函数可能被opencl实现异步调用。应用程序的责任是确保回调函数是线程安全的。如果pfn_notify为空,则不会注册回调函数。
这个回调函数的参数是: errinfo是一个指向错误字符串的指针。 private_info和cb表示由opencl实现返回的二进制数据的指针,可用于记录有助于调试错误的其他信息。 - user_data:是指向用户提供的数据的指针。 用户数据 pfn_notify被调用时作为user_data参数传递。 user_data可以为null。
- errcode_ret :返回相应的错误代码。如果errcode_ret为null,则不会返回错误代码。
4、创建一个命令队列,返回值是cl_command_queue。典型调用是传递一个上下文参数和设备。
cl_command_queue clCreateCommandQueue( cl_context context,
cl_device_id device,
cl_command_queue_properties properties,
cl_int *errcode_ret)- properties: 指定命令队列的属性列表。这是一个字段。常用的字段是CL_QUEUE_PROFILING_ENABLE,它表示启用或禁用命令队列中的命令概要分析。如果设置,则启用命令概要分析。否则禁用命令的分析。
创建一个程序对象,返回值是cl_program。
5、为上下文创建程序对象,返回值是cl_program。OpenCL的可移植性就体现在它在移植到不同的平台上时,所有的API调用都连接到ICD这个中间层,然后ICD层将具体的实现转发给特定的厂商运行时。OpenCL源代码以字符串文本的形式存储,后缀为.cl,并读到内存的字符串数组中。主机通过调用clCreateProgramWithSource()函数将字符串数组中的文本字符串指定的源代码加载到程序对象中,最后,使用clBuildProgram()函数编译程序对象,如果有语法错误,则会报错。
cl_program clCreateProgramWithSource ( cl_context context,
cl_uint count,
const char **strings,
const size_t *lengths,
cl_int *errcode_ret)- strings: 一个数组指针,用于构成源代码的可选的以null结尾的字符串。
- lengths: 一个数组,内容是每个字符串中的字符数(字符串长度)。如果长度为零的元素,则其伴随的字符串为null终止。如果length为null,则字符串参数中的所有字符串都将被认为是null终止的。其中传递的任何长度值大于零,排除其计数中的null终止符。
cl_int clBuildProgram ( cl_program program,
cl_uint num_devices,
const cl_device_id *device_list,
const char *options,
void (*pfn_notify)(cl_program, void *user_data),
void *user_data)- options: 一个指向用于构建程序可执行文件的构建选项的字符串的指针。
6、创建一个内核对象,返回值是cl_kernel。
cl_kernel clCreateKernel ( cl_program program,
const char *kernel_name,
cl_int *errcode_ret)7、创建一个新buffer时,需要提供主机指针以及buffer的大小以及与它关联的上下文,同时需要指定一个标志,表明数据是只读、只写还是可读写的。返回值是cl_mem。
cl_mem clCreateBuffer ( cl_context context,
cl_mem_flags flags,
size_t size,
void *host_ptr,
cl_int *errcode_ret)- flags:分配的内存状态标志
| cl_mem_flags | Description |
|---|---|
| CL_MEM_READ_WRITE | 对kernel来说,内存对象既可读又可写,默认方式 |
| CL_MEM_WRITE_ONLY | 对kernel来说,内存对象只可写,通常用来保存内核的输出数据 |
| CL_MEM_READ_ONLY | 对kernel来说,内存对象只可读,通常用于保存内核的输入数据,修改该对象会造成未定义结果 |
| CL_MEM_USE_HOST_PTR | 在设备上分配内存,并且绑定(pin)到一个host_ptr(不为NULL) |
| CL_MEM_ALLOC_HOST_PTR | 在设备上分配内存,分配的内存空间主机可访问。通常用在设备的固定内存(pinned memory)上, |
| CL_MEM_COPY_HOST_PTR | 在设备上分配内存,用host_ptr(不为NULL)指向的内存空间初始化缓存对象(分配空间和复制数据一步完成) |
- size 要分配的buffer对象的大小(以字节为单位)。
- host_ptr 指向应用程序可能已分配内存上的指针。 host_ptr指向的缓冲区的大小必须大于或等于size字节。
2、执行内核代码相关的API
1、读写buffer
数据从主机端到设备buffer调用clEnqueueWriteBuffer,而从设备buffer到主机端调用clEnqueueReadBuffer。第二个参数blocking_write布尔量设置为CL_TRUE,表示数据传输完成后函数才返回。而设置为CL_FALSE表明,函数可以先于读写操作前返回值。
cl_int clEnqueueWriteBuffer ( cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_write,
size_t offset,
size_t cb,
const void *ptr,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)cl_int clEnqueueReadBuffer ( cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_read,
size_t offset,
size_t cb,
void *ptr,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)2、clEnqueueNDRangeKernel 函数是异步的:当命令进入队列后立即返回,甚至可能在kernel执行之前就返回了,所以确保kernel执行的方法是:使用clWaitEvent()或clFinish()函数阻塞直到kernel执行完成。
设定内核参数,返回值是cl_int。
cl_int clSetKernelArg ( cl_kernel kernel,
cl_uint arg_index,
size_t arg_size,
const void *arg_value)- arg_index: 参数索引。内核的参数是从最左侧的参数0到n-1的索引引用的,其中n是内核声明的参数总数。
- arg_value:一个指向数据的指针,该数据应该用作由arg_index指定的参数的参数值。复制arg_value指向的参数数据,因此,在clsetkernelarg返回后,应用程序可以重用arg_value指针。指定的参数值是通过调用内核的所有api调用(如clenqueuendrangekernel和clenqueuetask)使用该值,直到再次通过调用clsetkernelarg为内核来更改参数值。
如果参数是内存对象(buffer或image),则arg_value将是指向适当buffer或image对象的指针。必须使用与内核对象关联的上下文来创建内存对象。
如果参数是buffer对象,那么也可以指定一个空值,在这种情况下,将使用空值作为声明为内核中__global或__constant内存的指针的参数的值。
如果使用__local限定词声明参数,则arg_value条目必须为null。
3、执行内核,典型的调用需要指定命令队列,内核,工作空间的维度,各个维度的大小。
cl_int clEnqueueNDRangeKernel ( cl_command_queue command_queue,
cl_kernel kernel,
cl_uint work_dim,
const size_t *global_work_offset,
const size_t *global_work_size,
const size_t *local_work_size,
cl_uint num_events_in_wait_list,
const cl_event *event_wait_list,
cl_event *event)4、clFinish和clFlush函数区别
clFinish函数将让调用者等待队列里的任务完成。它只保证程序运行到这个函数时,所有的任务完成,不知道任务开始执行的时间。函数原型是cl_int clFinish ( cl_command_queue command_queue)
clFlush函数将让调用者立刻将没有提交给设备的任务提交给设备,它将命令队列中的所有命令都移出队列。它只保证程序运行到这个函数时,任务开始执行,不知道任务结束的时间。函数原型是cl_int clFlush ( cl_command_queue command_queue)
5、clWaitForEvents函数是保证等待与事件列表中关联的函数执行完成,它是程序执行流中的一个同步点。
cl_int clWaitForEvents ( cl_uint num_events,
const cl_event *event_list)3、释放资源API
//注意以下五种对象的释放顺序
cl_int clReleaseKernel (cl_kernel kernel)
cl_int clReleaseProgram(cl_program program)
cl_int clReleaseCommandQueue(cl_command_queue command_queue)
cl_int clReleaseMemObject (cl_mem memobj)
cl_int clReleaseContext(cl_context context)