darknet源码解读-yolov2损失计算
参考文章:
https://blog.csdn.net/xiaohu2022/article/details/80666655
https://github.com/pjreddie/darknet/blob/master/src/region_layer.c //darknet源代码
yolov2损失计算的源代码集中在region_layer.c文件forward_region_layer函数中,为了兼顾坐标、分类、目标置信度以及训练效率,损失函数由多个部分组成,且不同部分都被赋予了各自的损失权重,整体计算公式如下。

图:yolov2损失函数计算公式
W,H指的是特征图(13x13)的宽和高,A指每个网格单元(cell)对应的anchor box的数目(5),各种![]() 表示各类损失的权重。我们先看第1部分损失:
表示各类损失的权重。我们先看第1部分损失:
![]()
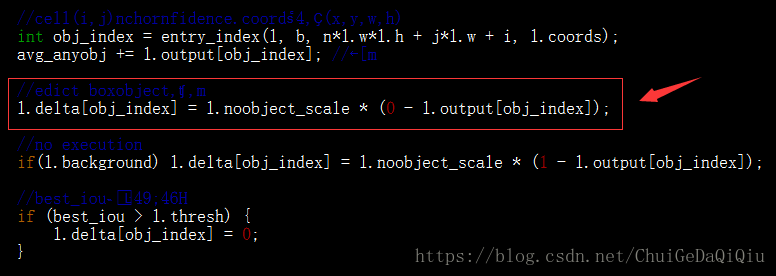
当Max IoU小于阈值thresh时,预测box为没有目标,由以上公式计算没有目标时的损失。观察代码的话可以看到,首先默认将所有预测box都当做没有目标进行了计算,后面当某个预测box的best_iou大于阈值时再将该预测box的目标置信度损失置为0。再来看下第2部分,坐标回归损失:
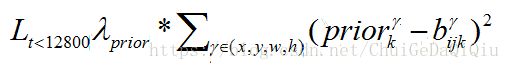

当训练的图片数量小于12800张的时候计算这些图片的坐标(x,y,h,w)损失。
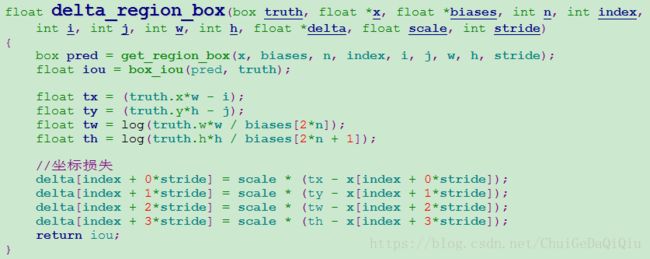
再看第3大项:
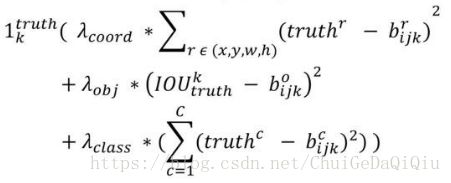
for(t = 0; t < 30; ++t){
box truth = float_to_box(net.truth + t*(l.coords + 1) + b*l.truths, 1);
if(!truth.x) break;
float best_iou = 0;
int best_n = 0;
i = (truth.x * l.w); //cell(j,i)
j = (truth.y * l.h);
box truth_shift = truth;
truth_shift.x = 0;
truth_shift.y = 0;
for(n = 0; n < l.n; ++n){
int box_index = entry_index(l, b, n*l.w*l.h + j*l.w + i, 0);
box pred = get_region_box(l.output, l.biases, n, box_index, i, j, l.w, l.h, l.w*l.h);
if(l.bias_match){
pred.w = l.biases[2*n]/l.w;
pred.h = l.biases[2*n+1]/l.h;
}
pred.x = pred.y = 0;
float iou = box_iou(pred, truth_shift);
if (iou > best_iou){
best_iou = iou;
best_n = n;
}
}
int box_index = entry_index(l, b, best_n*l.w*l.h + j*l.w + i, 0);
float iou = delta_region_box(truth, l.output, l.biases, best_n, box_index,
i, j, l.w, l.h, l.delta, l.coord_scale * (2 - truth.w*truth.h), l.w*l.h);
if(l.coords > 4){ //no exec
int mask_index = entry_index(l, b, best_n*l.w*l.h + j*l.w + i, 4);
delta_region_mask(net.truth + t*(l.coords + 1) + b*l.truths + 5,
l.output, l.coords - 4, mask_index, l.delta, l.w*l.h, l.mask_scale);
}
if(iou > .5) recall += 1;
avg_iou += iou;
//best predict box confidence
int obj_index = entry_index(l, b, best_n*l.w*l.h + j*l.w + i, l.coords);
avg_obj += l.output[obj_index];
l.delta[obj_index] = l.object_scale * (1 - l.output[obj_index]);
if (l.rescore) {
l.delta[obj_index] = l.object_scale * (iou - l.output[obj_index]);
}
if(l.background){ //no exec
l.delta[obj_index] = l.object_scale * (0 - l.output[obj_index]);
}
int class = net.truth[t*(l.coords + 1) + b*l.truths + l.coords];
if (l.map) class = l.map[class];
int class_index = entry_index(l, b, best_n*l.w*l.h + j*l.w + i, l.coords + 1);
delta_region_class(l.output, l.delta, class_index, class, l.classes,
l.softmax_tree, l.class_scale, l.w*l.h, &avg_cat, !l.softmax); //class loss
++count;
++class_count;
}第3部分的损失计算与某个ground truth box匹配的预测框各部分的损失,包括坐标误差、置信度误差和分类误差。对于某个ground truth(外层for循环),首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IoU值(YOLOv2中bias_match=1),计算IoU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到原点,然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。在计算obj置信度时,在YOLOv1中target=1,而YOLOv2增加了一个控制参数rescore,当其为1时,target取预测框与ground truth的真实IOU值。对于那些没有与ground truth匹配的先验框(与预测框对应),除去那些Max_IOU低于阈值的,其它的就全部忽略,不计算任何误差(l.deltas在分配空间时默认已置0)。这点在YOLOv3论文中也有相关说明:YOLO中一个ground truth只会与一个先验框匹配(IOU值最好的),对于那些IOU值超过一定阈值的先验框,其预测结果就忽略了。