【十八掌●内功篇】第六掌:YARN之ResourceManager
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:![]() 大数据技术●降龙十八掌
大数据技术●降龙十八掌
- 系列文章:
-
【十八掌●内功篇】第六掌:YARN之架构和原理
【十八掌●内功篇】第六掌:YARN之ResourceManager
【十八掌●内功篇】第六掌:YARN之NodeManager
【十八掌●内功篇】第六掌:YARN之ApplicationMaster
【十八掌●内功篇】第六掌:YARN之YARN资源调度器
ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个NodeManager的资源汇报信息,并把这些信息按照一定的策略分配给各个ApplicationMaster。
1、 RM的职能
(1)与客户端交互,处理客户端的请求。
(2)启动和管理AM,并在它运行失败时候重新启动它。
(3)管理NM,接收来自于NM的资源汇报信息,并向NM下达管理指令。
(4)资源管理和调度,接收来自于AM的资源请求,并为它分配资源。
2、 RM的内部结构
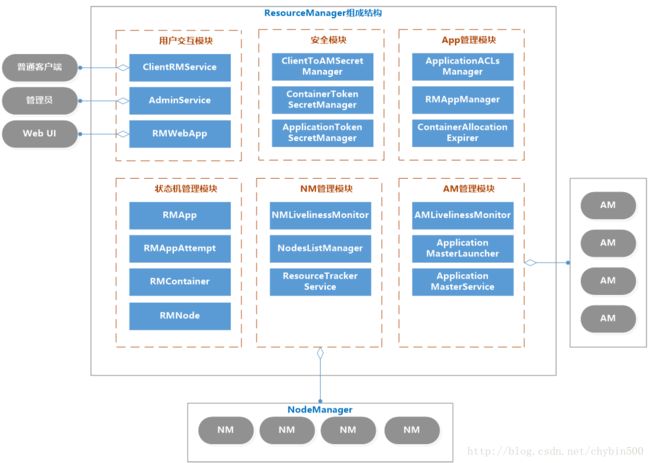
| 模块 | 服务 | 描述 |
|---|---|---|
| 用户交互模块 | ClientRMService | 为普通用户服务,处理请求,如:提交应用程序、终止程序、获取程序状态 |
| AdminService | 给管理员提供的服务。普通用户交互模块是ClientRMService,管理员交互模块是AdminService,之所以要将两个模块分开,用不同的通信通道发送给ResourceManager,是因为要避免普通用户的请求过多导致管理员请求被阻塞 | |
| WebApp | 更友好的展示集群资源和程序运行状态 | |
| NM管理模块 | NMLivelinessMonitor | 监控NM是否活着,如果指定时间内未收到心跳,就从集群中移除。RM会通过心跳告诉AM某个NM上的Container失效,如果Am判断需要重新执行,则AM重新向RM申请资源。 |
| NodesListManager | 维护inlude(正常)和exlude(异常)的NM节点列表。默认情况下,两个列表都为空,可以由管理员添加节点。exlude列表里的NM不允许与RM进行通信。 | |
| ResourceTrackerService | 处理来自NM的请求,包括注册和心跳。注册是NM启动时的操作,包括节点ID和可用资源上线等。心跳包括各个Container运行状态,运行Application列表、节点健康状态 | |
| AM管理模块 | AMLivelinessMonitor | 监控AM是否还活着,如果指定时间内没有接受到心跳,则将正在运行的Container置为失败状态,而AM会被重新分配到另一个节点上 |
| ApplicationMasterLauncher | 要求某一个NM启动ApplicationMaster,它处理创建AM的请求和kill AM的请求 | |
| ApplicationMasterService | 处理来自AM的请求,包括注册、心跳、清理。注册是在AM启动时发送给ApplicationMasterService的;心跳是周期性的,包括请求资源的类型、待释放的Container列表;清理是程序结束后发送给RM,以回收资源清理内存空间; | |
| Application管理模块 | ApplicationACLLsManager | 管理应用程序的访问权限,分为查看权限和修改权限。 |
| RMAppManager | 管理应用程序的启动和关闭 | |
| ContainerAllocationExpirer | RM分配Container给AM后,不允许AM长时间不对Container使用,因为会降低集群的利用率,如果超时(时间可以设置)还没有在NM上启动Container,RM就强制回收Container。 | |
| 状态机管理模块 | RMApp | RMApp维护一个应用程序的的整个运行周期,一个应用程序可能有多个实例,RMApp维护的是所有实例的 |
| RMAppAttempt | RMAppAttempt维护一个应用程序实例的一次尝试的整个生命周期 | |
| RMContainer | RMContainer维护一个Container的整个运行周期(可能和任务的周期不一致) | |
| RMNode | RMNode维护一个NodeManager的生命周期,包括启动到运行结束的整个过程。 | |
| 安全模块 | RM自带了全面的权限管理机制。主要由ClientToAMSecretManager、ContainerTokenSecretManager、ApplicationTokenSecretManager等模块组成。 | |
| 资源分配模块 | ResourceScheduler | ResourceScheduler是资源调度器,他按照一定的约束条件将资源分配给各个应用程序。RM自带了一个批处理资源调度器(FIFO)和两个多用户调度器Fair Scheduler 和Capacity Scheduler |
3、 启动AM流程
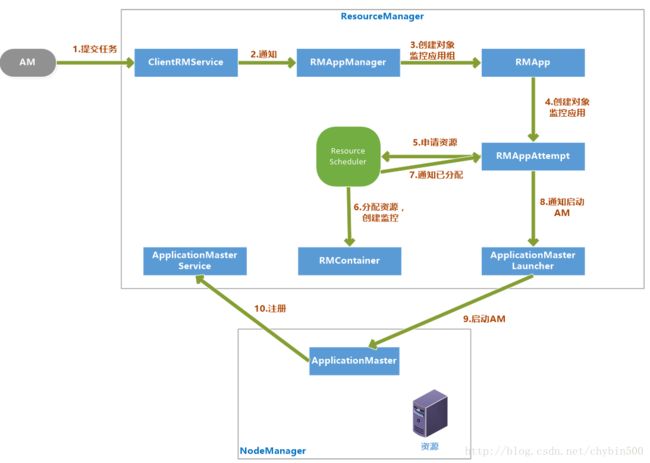
(1) 客户端提交一个任务给RM,ClientRMService负责处理客户端请求
(2) ClentRMService通知RMAppManager。
(3) RMAppManager为应用程序创建一个RMApp对象来维护任务的状态。
(4) RMApp启动任务,创建RMAppAttempt对象。
(5) RMAppAttempt进行一些初始化工作,然后通知ResourceScheduler申请资源。
(6) ResourceScheduler为任务分配资源后,创建一个RMContainer维护Container状态
(7) 并通知RMAppAttempt,已经分配资源。
(8) RMAppAttempt通知ApplicationMasterLauncher在资源上启动AM。
(9) 在NodeManager的已分配资源上启动AM
(10) AM启动后向ApplicationMasterService注册。
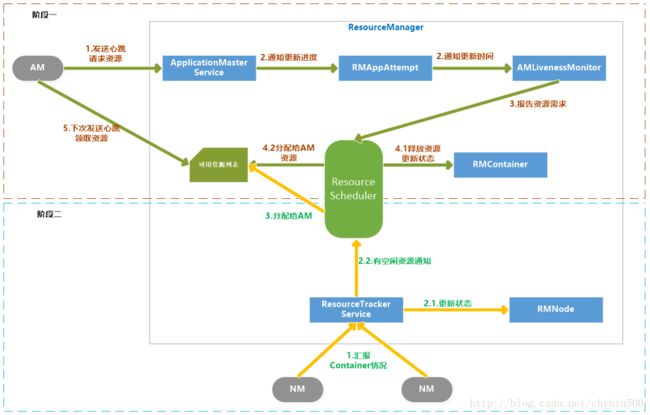
4、 申请和分配Container流程
AM向RM请求资源和RM为AM分配资源是两个阶段的循环过程:
阶段一:AM请求资源请求并领取资源的过程,这个过程是AM发送请求、RM记录请求。
阶段二:NM向RM汇报各个Container运行状态,如果RM发现它上面有空闲的资源就分配给等待的AM。
具体过程如下:
阶段一:
(1) AM通过RPC函数向RM发送资源需求信息,包括新的资源需求描述、待释放的Container列表、请求加入黑名单的节点列表、请求移除黑名单的节点列表等
(2) RM的ApplicationMasterService负责处理AM的请求。一旦收到请求,就通知RMAppAttempt,更新应用程序执行进度,在AMLivenessMonitor中记录更新时间。
(3) ApplicationMasterService调用ResourceScheduler,将AM的资源需求汇报给ResourceScheduler。
(4) ResouceScheduler首先读取待释放的Container列表,通知RMContainer更改状态,杀死要释放的Container,然后将新的资源需求记录,如果资源足够就记录已经分配好资源。
阶段二:
(1) NM通过RPC向RM汇报各自的各个Container的运行情况
(2) RM的ResourceTrackerService负责处理来自NM的汇报,收到汇报后,就通知RMNode更改Container状态,并通知ResourceScheduler。
(3) ResourceScheduler收到通知后,如果有可分配的空闲资源,就将资源分配给等待资源的AM,等待AM下次心跳将资源领取走。
5、 杀死Application流程
Kill Job通常是客户端发起的,RM的ClientRMService负责处理请求,接收到请求后,先检查权限,确保用户有权限Kill Job,然后通知维护这个Application的RMApp对象,根据Application当前状态调用相应的函数来处理。
这个时候分为两种情况:Application没有在运行、Application正在运行。
- (1) Application没有在运行
- 向已经运行过的NodeManger节点对应的状态维护对象RMNode发送通知,进行清理;向RMAppManager发送通知,将Application设置为已完成状态。
- (2) Application正在运行
-
如果正在运行,也首先像情况一处理一遍,回收运行过的NodeManager资源,将Application设置为已完成。另外RMApp还要通知维护任务状态的RMAppAttempt对象,将已经申请和占用的资源回收,但是真正的回收是由资源调度器ResourceScheduler异步完成的。
异步完成的步骤是先由ApplicationMasterLauncher杀死AM,并回收它占用的资源,再由各个已经启动的RMContainer杀死Container并回收资源。
6、 Container超时
YARN里有两种Container:运行AM的Container和运行普通任务的Container。
(1) RM为要启动的AM分配Container后,会监控Container的状态,如果指定时间内AM还没有在Container上启动的话,Container就会被回收,AM Container超时会导致Application执行失败。
(2) 普通Container超时会进行资源回收,但是YARN不会自动在其他资源上重试,而是通知AM,由AM决定是否重试。
7、 安全管理
Hadoop的安全管理是为了更好地让多用户在共享Hadoop集群环境下安全高效地使用集群资源。系统安全机制由认证和授权两大部分构成,Hadoop2.0中的认证机制采用Kerberos和Token两种方案,而授权则是通过引入访问控制表(Access Control List,ACL)实现的。
(1) 术语
Kerberos是一种基于第三方服务的认证协议,非常安全。特点是用户只需要输入一次身份验证信息就可以凭借此验证获得的票据访问多个服务。
Token是一种基于共享密钥的双方身份认证机制。
Principal是指集群中被认证或授权的主体,主要包括用户、Hadoop服务、Container、Application、Localizer、Shuffle Data等。
(2) Hadoop认证机制
Hadoop同时采用了Kerberos和Token两种技术,服务和服务之间的认证采用了Kerberos,用户和NameNode及用户和ResourceManager首次通讯也采用Kerberos认证,用户和服务之间一旦建立连接后,用户就可以从服务端获取一个Token,之后就可以使用Token认证通讯了。因为Token认证要比Kerberos要高效。
Hadoop里Kerberos认证默认是关闭的,可以通过参数hadoop.security.authentication设置为kerberos,这个配置模式是simple。
(3) Hadoop授权机制
Hadoop授权是通过访问控制列表(ACL)实现的,Hadoop的访问控制机制与UNIX的POSIX风格的访问控制机制是一致的,将权限授予对象分为:用户、同组用户、其他用户。默认情况下,Hadoop公用UNIX/Linux下的用户和用户组。
- 队列访问控制列表
- 应用程序访问控制列表
- 服务访问控制列表
8、 RM HA架构
通常来说Master/Slave架构中解决单点故障问题都采用热备份来实现HA,一个Active Master对外提供服务,若干个Standby Master实时同步Active Master,一旦Active Master故障,根据一定策略将Standby Master切换为Active Master对外提供服务。
ResourceManager负责整个集群的资源管理和调度,它的容错性直接导致YARN的可用性和可靠性。
Active Master和Standby Master之间数据同步一般采用中间共享的存储系统实现,RM HA采用Zookeeper共享存储方案。
RM HA分为手动模式和自动模式,手动模式是指由管理员通过命令进行主备切换,通常用于服务升级;自动模式可以自动切换但是存在潜在危险。
RM HA 自动模式架构图如下:
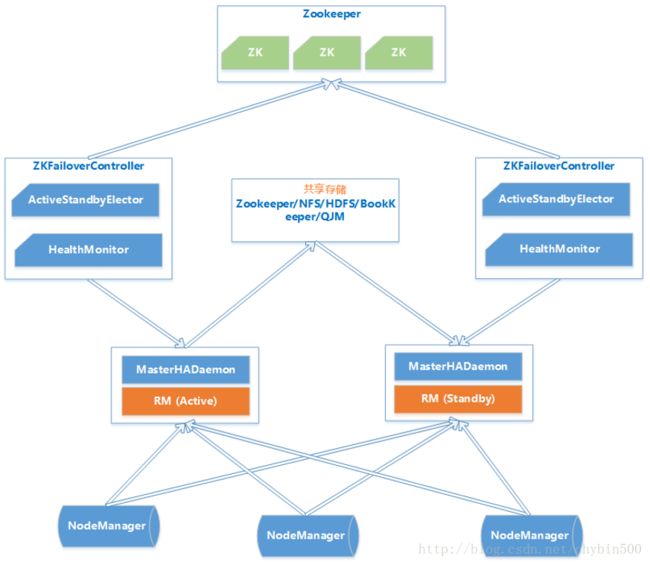
(1) MasterHADaemon:控制RM的 Master的启动和停止,和RM运行在一个进程中,可以接收外部RPC命令。
(2) 共享存储:Active Master将信息写入共享存储,Standby Master读取共享存储信息以保持和Active Master同步。
(3) ZKFailoverController:基于Zookeeper实现的切换控制器,由ActiveStandbyElector和HealthMonitor组成,ActiveStandbyElector负责与Zookeeper交互,判断所管理的Master是进入Active还是Standby;HealthMonitor负责监控Master的活动健康情况,是个监视器。
(4) Zookeeper:核心功能是维护一把全局锁控制整个集群上只有一个Active的ResourceManager。
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:![]() 大数据技术●降龙十八掌
大数据技术●降龙十八掌