贝叶斯⑥——银行借贷模型(贝叶斯与决策树对比)
贝叶斯机器学习系列:
贝叶斯①——贝叶斯原理篇(联合概率&条件概率&贝叶斯定理&拉普拉斯平滑)
贝叶斯②——贝叶斯3种分类模型及Sklearn使用(高斯&多项式&伯努利)
贝叶斯③——Python实现贝叶斯文本分类(伯努利&多项式模型对比)
贝叶斯④——Sklean新闻分类(TF-IDF)
贝叶斯⑤——搜狗新闻分类实战(jieba + TF-IDF + 贝叶斯)
之前在决策树系列中写了一篇博客,是利用决策树建立了一个银行借贷模型,鉴于都是分类,今天就来对比下贝叶斯和决策树的分类效果。
一、数据集
下载:https://pan.baidu.com/s/1AtFKXSMYdD_G3M5UhTC1-w 提取码: oygj
二、字段介绍
① name_id: 姓名
② profession: 职业,1-企业工作者,2-个体经营户,3-自由工作者,4-事业单位,5-体力劳动者
③ education: 教育程度,1-博士及以上,2-硕士,3-本科,4-专科,5-高中及以下
④ house_loan: 是否有房贷,1-有,0-没有
⑤ car_loan:是否有车贷,1-有,0-没有
⑥ married: 是否结婚,1-是,0-否
⑦ child:是否有小孩,1-有,0-没有
⑧ revenue:月收入
⑨ approve:是否予以贷款,1-贷款,2-不贷款
三、代码部分
①导入数据并处理得到训练集,测试集和验证集
# 导入库
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn import tree
from sklearn.metrics import confusion_matrix
# 导入数据
data = pd.read_csv('loan_data.txt',sep='\s+',encoding='utf-8',index_col='nameid')
print(data)
x = data.drop(['approve'],axis=1).values
print(x)
y = data['approve'].values
print(x.shape,y.shape)
# 划分训练集和测试集
x1 = x[:700]
y1 = y[:700]
x2 = x[700:]
y2 = y[700:]
# 在训练集中再划分出训练集和验证集
x_train,x_test,y_train,y_test = train_test_split(x1,y1,test_size=0.2)
② 使用决策树模型
# 决策树分类模型(判别型)
clf = DecisionTreeClassifier(max_depth=5,min_samples_split=5,min_impurity_split=0.37)
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
print('决策树分类结果如下:')
print('训练集评分:', clf.score(x_train,y_train))
print('验证集评分:', clf.score(x_test,y_test))
print('测试集评分', clf.score(x2,y2))
print("查准率:", metrics.precision_score(y_test,y_pred))
print('召回率:',metrics.recall_score(y_test,y_pred))
print('f1分数:', metrics.f1_score(y_test,y_pred))
print('混淆矩阵:')
print(confusion_matrix(y_true=y_test,y_pred=y_pred,labels=list(set(y))))

③ 使用贝叶斯高斯模型
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
print('贝叶斯分类结果如下:')
print('训练集评分:', clf.score(x_train,y_train))
print('验证集评分:', clf.score(x_test,y_test))
print('测试集评分', clf.score(x2,y2))
print("查准率:", metrics.precision_score(y_test,y_pred))
print('召回率:',metrics.recall_score(y_test,y_pred))
print('f1分数:', metrics.f1_score(y_test,y_pred))
print('混淆矩阵:')
print(confusion_matrix(y_true=y_test,y_pred=y_pred,labels=list(set(y))))
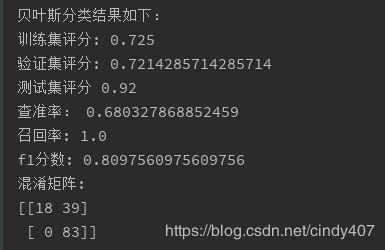
④使用贝叶斯多项式模型
# 贝叶斯多项式模型(生成型)
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB(fit_prior=True)
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
print('贝叶斯分类结果如下:')
print('训练集评分:', clf.score(x_train,y_train))
print('验证集评分:', clf.score(x_test,y_test))
print('测试集评分', clf.score(x2,y2))
print("查准率:", metrics.precision_score(y_test,y_pred))
print('召回率:',metrics.recall_score(y_test,y_pred))
print('f1分数:', metrics.f1_score(y_test,y_pred))
print('混淆矩阵:')
print(confusion_matrix(y_true=y_test,y_pred=y_pred,labels=list(set(y))))

四、总结
① 在此样本分类中,决策树的分类准确率>贝叶斯高斯模型>贝叶斯多项式模型,在实际应用中,也应该多尝试使用不同的模型,找到与业务需求匹配最佳的模型
② 从召回率和查准率看,决策树和高斯都能达到1的召回率,但查准率就比较低,说明所有给予贷款的用户都能分类正确,但同时也把一些不给予贷款的也给予贷款了,条件过于宽松,导致准确率偏低,用在实际业务中,会给银行带来一定的风险。
③ 如果银行此时处于蓬勃发展,资金雄厚的阶段,这个模型是可以的,但是如果处于平缓扩张,以稳为主的阶段,那就得牺牲一定的召回率,提升查准率,宁可少贷给几个能还款的人,也不能贷给一个不还款的人
本人从事数据分析师的工作,除了目前已出的Excel,SQL,Pandas,Matplotlib,Seaborn,机器学习系列以外,后续还会出数据挖掘,统计学以及工作经验系列,感兴趣的小伙伴可关注下我喔