【笔记3-7】CS224N课程笔记 - 神经网络机器翻译seq2seq注意力机制
CS224N(七)Neural Machine Translation, Seq2seq and Attention
- seq2seq神经网络机器翻译
- 历史方法
- seq2seq基础
- seq2seq - 编码部分
- seq2seq - 解码部分
- NMT示例
- 双向RNN
- 注意力机制
- 提出的动机
- Bahdanau et al. NMT
- 翻译对齐
- 模型在长句上的表现
- 其他模型
- Huong et al. NMT
- Google’s new NMT
- 更多使用注意力机制的文章
- 序列模型解码器
- 机器翻译系统评估
- 人工评估
- 与其他任务的对比评估
- BLEU(Bilingual Evaluation Understudy)
- 大规模输出词汇处理
- scaling softmax
- 减少词汇
- 处理未知词汇
- 基于单词和字符的模型
- 词汇分割
- 基于字符的模型
- 混合NMT
【笔记3-1】CS224N课程笔记 - 深度自然语言处理
【笔记3-2】CS224N课程笔记 - 词向量表示 word2vec
【笔记3-3】CS224N课程笔记 - 高级词向量表示
【笔记3-4】CS224N课程笔记 - 分类与神经网络
【笔记3-5】CS224N课程笔记 - 依存分析
【笔记3-6】CS224N课程笔记 - RNN和语言模型
【笔记3-8】CS224N课程笔记 - 卷积神经网络
CS224n:深度学习的自然语言处理(2017年冬季)1080p https://www.bilibili.com/video/av28030942/
关键词:seq2seq,注意力机制,神经网络机器翻译,语音处理
seq2seq神经网络机器翻译
前面已经讲解过预测单个输出的问题,比如一个单词的NER标签,给定过去几个单词预测最有可能出现的下一个单词。还有一些NLP任务依赖于顺序输出,或者是长度可变的序列。比如
- 翻译:用一种语言输入一个句子,然后用另一种语言输出相同的句子。
- 对话:把一个陈述或问题作为输入并做出回应。
- 摘要:将大量文本作为输入并输出摘要。
本章将关注seq2seq模型,一个用于处理上述问题的基于深度学习的框架。
历史方法
在过去,翻译系统是基于以下概率模型构建的:
- 翻译模型,源语言中的句子/短语最可能翻译成什么
- 语言模型,一个给定的句子/短语整体的可能性。
这些组件用于构建基于单词或短语的翻译系统。但一个简单的基于单词的系统不能捕捉语言之间排序的差异(例如否定词的位置、句子中主语和动词的位置,等等)。在Seq2Seq之前,基于短语的翻译系统可以根据短语序列考虑输入和输出,并且可以处理比基于单词的系统更复杂的语法。然而,长期依赖关系仍然很难在基于短语的系统中捕获。
Seq2Seq的优势,尤其是使用LSTM,是现代翻译系统能够生成的看到整个输入后的任意输出序列。甚至可以自动关注输入的特定部分来提供帮助生成有用的翻译。
seq2seq基础
seq2seq模型是由两个递归神经网络组成的端到端模型:
- 编码器,将模型的输入序列作为输入,并将其编码为固定大小的“上下文向量”
- 解码器,它使用上面的上下文向量作为“种子”,从中生成输出序列。
因此,Seq2Seq模型通常被称为“编解码器模型”。
seq2seq - 编码部分
编码器将输入序列读入Seq2Seq模型,并为序列生成一个固定维上下文向量C。

为此,编码器使用一个RNN单元(通常是LSTM)一次读取一个输入标记。最后隐藏状态的细胞将成为C。由于压缩一个任意长度的向量序列成固定大小较为困难(尤其是翻译等困难的任务),编码器通常由堆叠LSTM组成,即一系列LSTM层,每一层的输出是下一层的输入。最后一层的LSTM隐藏状态将作为C使用。
Seq2Seq编码器经常反向处理输入序列,这样编码器看到的最后一件事大致对应于模型输出的第一个东西;这使解码器更容易“开始”输出,更容易生成正确的输出语句。在翻译中,要让网络尽快翻译输入的头几个单词,一旦头几个单词翻译正确,继续构造一个正确的句子要容易得多。
seq2seq - 解码部分
解码器也是LSTM网络,但比编码器稍复杂一些。本质上,希望将其用作一种语言模型,能够利用到目前为止生成的单词和输入。保留编码器的堆叠LSTM结构,使用上下文向量初始化第一层的隐藏状态;使用输入的上下文来生成输出。

解码器与上下文设置好后,传递一个特殊的标志来表示输出生成的开始,通常是一个附加到输入末尾的 < E O S > <EOS> <EOS>(在输出末尾也有一个)。然后运行所有LSTM层,一个接着一个,在最后一层的输出上使用softmax生成第一个输出单词。然后将该单词传递到第一层,并重复生成。这就是LSTM充当语言模型的方法。
有了输出序列就使用相同的学习策略,定义损失为预测序列上的交叉熵,并用梯度下降和反向传播将其最小化。编码解码器同时训练,因此都学习相同的上下文向量表示。
NMT示例
注意输入和输出的长度之间没有联系,任何长度的输入都可以传入,任何长度的输出都可以生成。由于LSTM的实际限制,Seq2Seq模型在很长的输入时间内会失效。
考虑Seq2Seq模型如何将“what is your name”翻译成“comment t 'appelles tu”。
首先,从输入四个独热向量开始(这些输入可能嵌入到密集的向量表示中,也可能不嵌入)然后一个堆叠的LSTM网络反向读取序列并将其编码到一个上下文向量中(这个上下文向量是一个向量空间,表示询问某人姓名的概念)用于初始化另一个堆叠LSTM的第一层。对网络的每一层运行一个步骤,对最后一层的输出执行softmax,选择第一个输出单词,这个单词被反馈回网络作为输入。
在反向传播过程中,编码器的LSTM权值被更新,以便更好地学习句子的向量空间表示,解码器的LSTM权值被训练,使其生成与上下文向量相关的语法正确的句子。
双向RNN
句子中的依赖关系并不只在一个方向上起作用,一个单词可以依赖于之前或之后的另一个单词。到目前为止的Seq2Seq并不能解释这一点。在任何时候,我们只考虑当前单词之前单词的信息(通过LSTM隐藏状态)。对于NMT,我们需要能够有效地编码任何输入,而不管输入中的依赖关系方向如何。
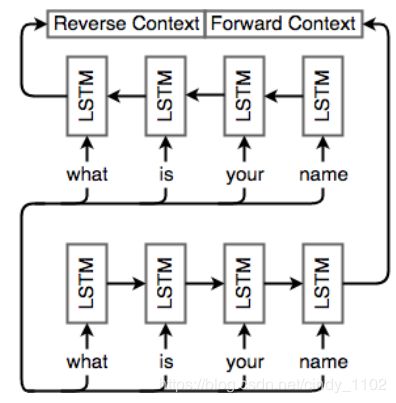
双向RNNs通过在两个方向遍历一个序列并连接结果输出(cell输出和最终隐藏状态)来解决这个问题。对于每个RNN单元,只是简单地添加另一个单元,但以相反的方向提供输入。与第t个单词对应的输出 o t o_t ot 是连接的向量 [ o t ( f ) o t ( b ) ] [o_t^{(f)} o_t^{(b)}] [ot(f)ot(b)],其中 o t ( f ) o_t^{(f)} ot(f) 为正向RNN对单词t的输出, o t ( b ) o ^{(b)} _t ot(b)为反向RNN的相应输出。同理,最终隐藏状态 h = [ h ( f ) h ( b ) ] h=[h^{(f)} h^{(b)}] h=[h(f)h(b)],其中 h ( f ) h^{(f)} h(f)为正向RNN的最终隐藏状态, h ( b ) h^{(b)} h(b)为反向RNN的最终隐藏状态。
注意力机制
提出的动机
人们在听到一句话时,会重点关注被认为重要的某些单词。类似地,Bahdanau等人注意到使用最终的RNN隐藏状态作为seq2seq模型的上下文向量的缺陷:通常,输入的不同部分具有不同的重要性级别。此外,输出的不同部分甚至可能认为输入的不同部分“重要”。例如在翻译中,输出的第一个单词通常基于输入的前几个单词,最后一个单词很可能基于输入的最后几个单词。
注意力机制利用这一观察结果,为解码器网络提供了在每个解码步骤查看整个输入序列的功能,然后解码器可以在任何时间点决定哪些输入单词是重要的。
Bahdanau et al. NMT
前面说过,seq2seq模型由两个部分组成,一个是编码输入语句的编码器,另一个是利用解码器提取的信息生成翻译后的句子的解码器。
基本上,输入是一个要翻译的单词序列 x 1 , . . . , x n x_1,...,x_n x1,...,xn,目标句子是一系列单词 y 1 , . . . . , y m y_1,....,y_m y1,....,ym
- encoder:
设 ( h 1 , … , h n ) (h_1,…, h_n) (h1,…,hn)为表示输入语句的隐藏向量。例如,这些向量是bi-LSTM的输出,包含有句子中每个单词的上下文表示。 - decoder:
解码器的隐藏状态 s i s_i si使用递归公式 s i = f ( s i − 1 , y i − 1 , c i ) s_i=f(s_{i-1},y_{i-1},c_i) si=f(si−1,yi−1,ci) 进行计算。其中 s i − 1 s_{i-1} si−1为之前的隐藏向量, y i − 1 y_{i-1} yi−1是上一步生成的词, c i c_i ci是上下文向量,包含有解码器时间步i中来自原句子的上下文相关信息。
上下文向量 c i c_i ci捕获第i个解码时间步的相关信息(不像标准的Seq2Seq只有一个上下文向量)。对于原始语句中的每个隐藏向量 h j h_j hj,计算一个分数 e i , j = a ( s i − 1 , h j ) e_{i,j}=a(s_{i-1},h_j) ei,j=a(si−1,hj) 其中a是实数域上的函数,例如单层全连接神经网络。然后得到一个标量值序列 e i , 1 , … , e i , n e_{i,1},… ,e_{i, n} ei,1,…,ei,n 使用softmax层 α i , j = e x p ( e i , j ) ∑ k = 1 n e x p ( e i , k ) \alpha_{i,j}=\frac{exp(e_{i,j})}{\sum_{k=1}^{n}exp(e_{i,k})} αi,j=∑k=1nexp(ei,k)exp(ei,j) 将这些分数标准化为向量 α i = ( α i , 1 , … , a i , n ) \alpha_i = (\alpha_{i,1},…, a_{i,n}) αi=(αi,1,…,ai,n)
然后,用原句中隐藏向量的加权平均值 c i = ∑ j = 1 n α i , j h j c_i=\sum_{j=1}^{n}\alpha_{i,j}h_{j} ci=∑j=1nαi,jhj 计算上下文向量 c i c_i ci,直观地说,这个向量为解码器第i步从原始语句中捕获的上下文信息。
翻译对齐
基于注意力的模型为输出的每个步骤分配输入的不同部分的重要性。在翻译中可以被理解为“对齐”。 α i j \alpha_{ij} αij在解码第i步时的注意力得分表示源句中的单词与目标句中的单词i对齐。可以使用注意力评分来构建一个对齐表——基于Seq2Seq NMT系统中的编码器和解码器,将源句中的单词映射到目标语句中的对应单词。
模型在长句上的表现
基于注意力的模型的主要优势是它们能够有效地翻译长句。随着输入的大小增加,如果只使用最终表示,不使用注意力的模型将会失去信息和精度。

其他模型
Huong et al. NMT
- 全局注意力:运行Seq2Seq NMT,编码器给出的隐藏状态为 h 1 , … , h n h_1,…, h_n h1,…,hn,解码器的隐藏状态为 h 1 ˉ , … , h n ˉ \bar{h_1},…,\bar{h_n} h1ˉ,…,hnˉ 对于每个 h i ˉ \bar{h_i} hiˉ,使用以下评分方式当中的一种计算编码器隐藏层上的注意力向量: s c o r e ( h i , h j ˉ ) = { h i T h j ˉ h i T W h j ˉ W [ h i , h j ˉ ] ∈ R score(h_i,\bar{h_j})=\left\{\begin{matrix}h_i^T\bar{h_j}\\ h_i^TW\bar{h_j}\\ W[h_i,\bar{h_j}]\end{matrix}\right.\in \mathbb{R} score(hi,hjˉ)=⎩⎨⎧hiThjˉhiTWhjˉW[hi,hjˉ]∈R
得到分值之后,可以用上述类似的方法,利用分值进行softmax求出权重 α i , j = e x p ( s c o r e ( h i , h j ˉ ) ) ∑ k = 1 n e x p ( s c o r e ( h k , h j ˉ ) ) \alpha_{i,j}=\frac{exp(score(h_i,\bar{h_j}))}{\sum_{k=1}^{n}exp(score(h_k,\bar{h_j}))} αi,j=∑k=1nexp(score(hk,hjˉ))exp(score(hi,hjˉ)),然后用权重加权得到上下文向量 c i = ∑ j = 1 n α i , j h j c_i=\sum_{j=1}^{n}\alpha_{i,j}h_{j} ci=∑j=1nαi,jhj。结合上下文向量以及隐藏状态可以计算一个新的向量 h i ~ = f ( [ h i ˉ , c i ] ) \tilde{h_i}=f([\bar{h_i},c_i]) hi~=f([hiˉ,ci])并利用该新向量进行最终的预测。 - 局部注意力:该模型预测输入序列中的对齐位置。然后使用以该位置为中心的窗口计算上下文向量。此注意步骤的计算成本是恒定的,且不随句子长度而改变。
由此可见,注意力的计算方法有很多种。
Google’s new NMT
谷歌通过自己的翻译系统为NMT做出了重大突破。一般而言,对每对语言建立完整的Seq2Seq模型,要求对每一种语言进行单独训练,对数据和计算时间的要求很高,但是谷歌建立了一个可以在任何两种语言之间进行翻译的单一系统。这是一个Seq2Seq模型,以单词序列和指定要翻译成何种语言的标志作为输入,可以使用共享参数转换成任何目标语言。
新的多语言模型不仅提高了翻译性能,还实现了“zero-shot翻译”,即可以在没有训练数据的两种语言之间进行翻译。例如,只有日语-英语翻译和韩语-英语翻译的例子,基于这些数据的多语言NMT系统可以生成合理的日语-韩语翻译。也就是说解码过程不特定于语言,且模型实际上保持了输入/输出句子的内部表示,独立于所涉及的实际语言。
更多使用注意力机制的文章
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
https://arxiv.org/pdf/1502.03044v1.pdf
(Kelvin Xu, Jimmy Lei Ba,Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard S. Zemel and Yoshua Bengio)
Modeling Coverage for Neural Machine Translation
https://arxiv.org/pdf/1601.04811.pdf
(Zhaopeng Tu, Zhengdong Lu, Yang Liu, Xiaohua Liu and Hang Li)
Incorporating Structural Alignment Biases into an Attentional Neural Translation Model
https://arxiv.org/pdf/1601.01085.pdf
Cohn, Hoang, Vymolova, Yao, Dyer, Haffari.
序列模型解码器
机器翻译的另一种方法来自统计机器翻译。考虑一个计算概率的模型 P ( s ˉ ∣ s ) P(\bar{s}|s) P(sˉ∣s)用于将句子 s s s 翻译成 s ˉ \bar{s} sˉ,目的是选择最佳的 s ˉ ∗ \bar{s}^* sˉ∗ 使得这一概率最大,即 s ˉ ∗ = a r g m a x s ˉ P ( s ˉ ∣ s ) \bar{s}^*=argmax_{\bar{s}}P(\bar{s}|s) sˉ∗=argmaxsˉP(sˉ∣s)
由于搜索空间可能很大,需要缩小它的大小。现列举一系列序列模型解码器(包括好解码器和坏解码器)。
- 穷举搜索:计算每个可能序列的概率,选择概率最高的序列。但由于搜索空间输入大小是指数级的,不能扩展到大的输出。此时解码是NP完全问题。
- 原始采样:在时间步t,根据过去的单词计算 x t x_t xt的条件概率 x t ∼ P ( x t ∣ x 1 , . . . , x n ) x_t\sim P(x_t|x_1,...,x_n) xt∼P(xt∣x1,...,xn) 从理论上讲,这种方法有效且渐近精确,而实践中,可能性能较差且方差高。
- 贪婪搜索:在每一步选择最可能的token,即 x t = a r g m a x x t ~ P ( x t ~ ∣ x 1 , . . . , x n ) x_t = argmax_{\tilde{x_t} }P (\tilde{x_t}|x_1,...,x_n) xt=argmaxxt~P(xt~∣x1,...,xn) 这是一种高效自然的方法,但只探索了搜索空间的一小部分,如果在某一步犯了错误,句子的其余部分可能会受到严重影响。
- 集束搜索:每次保留K个候选答案 H t = { ( x 1 1 , … , x t 1 ) , … , ( x 1 K , . . . , x t K ) } H_t = \{(x_1^1,…,x^1_t),…,(x_1^K,...,x_t^K)\} Ht={(x11,…,xt1),…,(x1K,...,xtK)}通过展开 H t H_t Ht并保留最佳的K个候选值来计算 H t + 1 H_{t+1} Ht+1。即在选择最好的K个序列 H ~ t + 1 = ⋃ k = 1 K H t + 1 k ~ H t + 1 k ~ = { ( x 1 k , … , x t k , v 1 ) , … , ( x 1 k , . . . , x t k , v ∣ V ∣ ) } \tilde{H}_{t+1}=\bigcup_{k=1}^{K}H_{t+1}^{\tilde{k}}\\H_{t+1}^{\tilde{k}}=\{(x_1^k,…,x^k_t,v_1),…,(x_1^k,...,x_t^k,v_{|V|})\} H~t+1=k=1⋃KHt+1k~Ht+1k~={(x1k,…,xtk,v1),…,(x1k,...,xtk,v∣V∣)}随着K的增加,得到更高的精度且渐近精确。然而进步不是单调的,可以设置一个综合合理性能和计算效率的K。集束搜索是NMT中最常用的方法。
机器翻译系统评估
前面已经了解了机器翻译的基本知识,现在讨论这些模型的评估方法。评价翻译的质量是一项棘手和带有主观意识的任务。给10个不同的译者一段文字会得到10个不同的翻译。他们关注不同的信息,强调不同的含义。一种翻译可以保留隐喻和长期思想的完整性,而另一种翻译可以更忠实地重构句法和风格,尝试逐字翻译。这种灵活性证明了语言的复杂性和我们解码和解释意思的能力。
这里需要区分模型的目标损失函数和评价方法。损失函数本质上是一个模型预测结果的求值函数,而评估指标提供了一个最终的、总结性的模型评估。没有哪种度量方式是优于其他所有度量方式的,尽管有些度量具有明显的优势以及为多数人所偏好。
评价机器学习翻译的质量已经成为了一个独立的研究领域,如TER, METEOR, MaxSim, SEPIA, RTE-MT。这里将重点介绍两种基线评估方法和BLEU。
人工评估
第一种方法是让人们手工评估系统的正确性、充分性和流畅性。但这种方法的一个明显问题是成本高且效率低,尽管它仍然是机器翻译的黄金标准。
与其他任务的对比评估
评估输出数据的有用表示(表示为翻译或摘要)的机器学习模型的一种常见方法是,如果预测对解决一些具有挑战性的任务有用,那么该模型必须在预测中编码相关信息。如,考虑把翻译预测(A翻译成B)训练成一个B语言的问答任务,即用系统的输出作为其他任务(问答)的输入。如果第二个任务在任务一得到的B语言以及格式良好的B语言数据上一样出色,这意味着输入具有满足任务需求的相关信息或模式。
这种方法的问题在于,第二个任务可能不受翻译细节的影响。 例如,在检索任务上度量翻译质量(比如为搜索查询打开正确的页面),会发现保留文档主题词但忽略语法的翻译仍然适合该任务,但这并不意味着翻译质量是准确的。因此,确定翻译模型的质量只是转换为确定任务本身的质量,这可能是一个好标准也可能不是。
BLEU(Bilingual Evaluation Understudy)
2002年,IBM研究人员开发了BLEU,是最受尊重和可靠的机器翻译方法之一。
BLEU算法对候选机器翻译与参考人工翻译的精度评分进行评估。参考人工翻译被假定为一个翻译的模型示例,使用n-gram matches作为衡量候选翻译与翻译相似程度的指标。考虑一个参考句a和候选译文B:
- A:there are many ways to evaluate the quality of a translation, like comparing the number of n-grams between a candidate translation and reference.
- B:the quality of a translation is evaluate of n-grams in a reference and with translation.
BLEU评分查找机器翻译中的n-gram是否也出现在参考翻译中。下面是一些不同大小的n-gram示例,它们在引用和候选翻译之间共享。
- A:there are many ways to evaluate the quality of a translation, like comparing the number of n-grams between a candidate translation and reference.
- B:the quality of a translation is evaluate of n-grams in a reference and with translation.
BLEU算法识别上述所有n-gram匹配,包括unigram匹配,并使用精度评分评估匹配的强度。精度分数是翻译中出现在参考文献中的n-gram的分数。
该算法还满足两个约束条件。
- 对于每个不同尺寸的n-gram,参考翻译中的一个gram不能在翻译结果中匹配超过一次。例如,unigram“a”在B中出现两次,但在a中只出现一次,就只能计数一次。
- 对句子的简洁性进行了限制,精度达到1.0(“完美”匹配)的非常小的句子并不被认为是好的翻译。例如,单个单词“there”可以达到1.0的精度匹配,但显然不是很好匹配。
下面讨论BLEU score的具体计算:
首先,k是我们要计算分数的最大n-gram。也就是说,如果k = 4,BLEU score只计算长度小于或等于4的n-gram。设尺寸为n的gram的精度得分 p n = # m a t c h e d n − g r a m s / # n − g r a m s i n c a n d i d a t e t r a n s l a t i o n p_n= \# matched \ n-grams / \# n-grams \ in \ candidate \ translation pn=#matched n−grams/#n−grams in candidate translation设 w n = 1 / 2 n w_n = 1/2^n wn=1/2n为n-gram精度的几何权重。惩罚系数为 β = e m i n ( 0 , 1 − l e n r e f l e n M T ) \beta=e^{min(0,1-\frac{len_{ref}}{len_{MT}})} β=emin(0,1−lenMTlenref)则最终的BLEU score为 B L E U = β ∏ i = 1 k p n w n BLEU=\beta\prod_{i=1}^{k}p_{n}^{w_n} BLEU=βi=1∏kpnwn据称BLEU score与人类对优秀翻译的判断密切相关,是所有评估指标的基准。然而它存在很多限制,第一,它只在语料库级别上工作得很好,因为精度得分中的任何零都将使整个BLEU得分为零。第二,所给出的BLEU评分只将候选翻译与单个参考翻译进行比较,存在相关n-gram的噪声表示问题。
BLEU的变体修改了算法,将候选对象与多个参考示例进行比较。此外,BLEU score可能只是一个必要的,但并不足以通过一个良好的机器翻译系统的基准。许多研究人员优化了BLEU score,直到他们开始接近参考译文之间相同的BLEU score,但质量仍然远远低于人类译文。
大规模输出词汇处理
尽管现代的NMT取得了成功,但在处理大词汇量时却遇到了困难。具体来说,Seq2Seq模型使用softmax计算整个词汇表上的目标概率分布来预测下一个单词。事实证明,大型词汇表的softmax计算量巨大,且复杂性与词汇表大小成正比。下面讨论解决这个问题的一些方法。
scaling softmax
一个很自然的想法是找到更有效的方法来计算目标概率分布,在之前的笔记中提到过两种降低“softmax”复杂性的方法,即负采样(噪声对比评估)和分层softmax。详见 【笔记3-2】CS224N课程笔记 - 词向量表示 word2vec 中的”skip-gram和CBOW的改进“部分,此处不再赘述。
这两种方法的一个限制是,它们只在训练步骤(当目标单词已知时)节约计算成本。在测试时,仍然需要计算词汇表中所有单词的概率才能做出预测。
减少词汇
除了优化“softmax”,还可以尝试减少有效词汇量,加快培训和测试。一种简单的方法是将词汇表的大小限制在很小的范围内,并用标记
On Using Very Large Target Vocabulary for Neural Machine Translation
https://arxiv.org/pdf/1412.2007.pdf
Sébastien Jean, Kyunghyun Cho, Roland Memisevic, Yoshua Bengio
有一个方法(Jean et al. 2015)可以维持一个恒定的词汇量大小 ∣ V ′ ∣ |V'| ∣V′∣,通过将训练数据划分成子集对应 τ \tau τ 个独特的目标词,其中 τ = ∣ V ′ ∣ \tau = |V'| τ=∣V′∣ 一个子集可以通过顺序扫描原始数据集,直到检测到 τ \tau τ 个独特的目标词。这个过程通过迭代整个数据集生成所有mini-batch子集。在实际应用中 ∣ V ∣ = 500 K , ∣ V ′ ∣ = 30 K , 50 K |V| = 500K, |V'| = 30K, 50K ∣V∣=500K,∣V′∣=30K,50K

这个概念与NCE(噪声对比评估)非常相似,对于任何给定的单词,输出词汇表包含目标单词和 ∣ V ′ ∣ − 1 |V'|-1 ∣V′∣−1 个负(噪声)样本。主要区别是,这些负样本是从每个子集 V ′ V' V′的一个有偏分布Q中抽取的 Q ( y t ) = { 1 ∣ V ′ ∣ , i f y t ∈ ∣ V ′ ∣ 0 , o t h e r w i s e Q(y_t)=\left\{\begin{matrix}\frac{1}{|V'|},if \ y_t\in|V'|\\0, \ otherwise\end{matrix}\right. Q(yt)={∣V′∣1,if yt∈∣V′∣0, otherwise在测试时,也可以从整个词汇表中选择一个子集(称为候选列表)来预测目标单词。难点在于正确的目标词是未知的,需要“猜测”目标词是什么。在文章中,作者提出用 K K K个最常见的单词(基于单字母概率)和 K ′ K' K′个可能的目标单词为每个源句构建一个候选列表。如下图所示,其中 K ′ K' K′ = 3,候选列表由紫色框中的所有单词组成。实践中可以选择 K = 15 k , 30 k , 50 k , K ′ = 10 , 20 K=15k, 30k,50k,K' =10,20 K=15k,30k,50k,K′=10,20

处理未知词汇
当NMT系统使用上面提到的技术来减少词汇量时,某些单词可能被映射到。例如,当预测的单词(通常是罕见的单词)不在候选列表中,或者在测试时遇到未见过的单词时,就会发生这种情况。需要使用新的机制来解决罕见和未知单词的问题。
Gulcehre等人提出的一个解决方法是学习“复制”源文本。模型应用注意力分布 l t l_t lt 决定源文本中的指向位置,并使用解码器隐藏状态 S t S_t St预测二进制变量 Z t Z_t Zt, Z t Z_t Zt决定何时从源文本中复制。最终的预测要么是候选表上通过softmax选择的单词 y t w y^w_t ytw(与前面的方法一样),要么是从源文本复制的 y t l y^l_t ytl(取决于 Z t Z_t Zt的值)。这种方法可以提高机器翻译和文本摘要等任务的性能。

这种方法存在一定局限性。谷歌NMT的论文曾评价方法称,这种做法在规模方面不可靠,当网络较深时注意力机制不稳定;复制罕见字可能并不总是最好的策略,有时音译可能更合适。
基于单词和字符的模型
前面提到”复制”机制在处理罕见或未知的单词时仍然不够,解决的另一个方向是分词操作。一种趋势是使用相同的seq2seq架构,但在更小的单元上操作——基于字符的分词模型。另一个趋势是为单词和字符采用混合架构。
词汇分割
Sennrich等人提出了一种方法,通过将罕见的和未知的单词表示为一组子单词单元来实现开放词汇翻译。
这是通过采用一种称为字节对编码(Byte Pair Encoding)的压缩算法来实现的。其基本思想是从一个字符词汇表vocabulary开始,不断扩展数据集中n-gram对最频繁的词汇表。例如下图中,数据集包含4个单词,对应的频率在左边,即“low”出现5次。用(p, q, f)表示一个n-gram对p, q及其频率f。在图中,已经选择了最频繁的n-gram对(e,s,9),现在正在添加当前最频繁的n-gram对(es,t,9)。重复此过程,直到选择所有的n-gram对或词汇表大小达到某个阈值。

可以选择为训练集和测试集构建单独的词汇表,或者联合构建一个词汇表。词汇表构建后可直接在这些词段上训练具有seq2seq体系结构的NMT系统。
基于字符的模型
Ling等人提出了一种基于字符的模型来支持开放词汇表的单词表示。对于每个包含m个字符的单词w,该模型不是存储一个嵌入的单词,而是遍历所有字符 c 1 , c 2 , … , c m c_1,c_2,…,c_m c1,c2,…,cm来查找字符嵌入 e 1 , e 2 , . . . , e m e_1,e_2,...,e_m e1,e2,...,em,然后将这些字符feed到一个biLSTM中,分别得到正向和反向的最终隐藏状态 h f , h b h_f,h_b hf,hb。最终词嵌入由两种隐藏状态的仿射变换计算得到 e w = W f H f + W b H b + b e_w=W_fH_f+W_bH_b+b ew=WfHf+WbHb+b还有一系列基于CNN的字符模型将在之后的笔记中介绍。
混合NMT
Luong等人提出了一种混合词元模型来处理未知词。该系统主要在单词级进行翻译,并查询罕见单词的字符组成。在高层次上,字符级RNN计算源词表示,并在需要时恢复未知目标词。这种混合方法的双重优势是,比基于字符的方法更快、更容易训练,同时,它不像基于单词的模型那样生成未知单词。
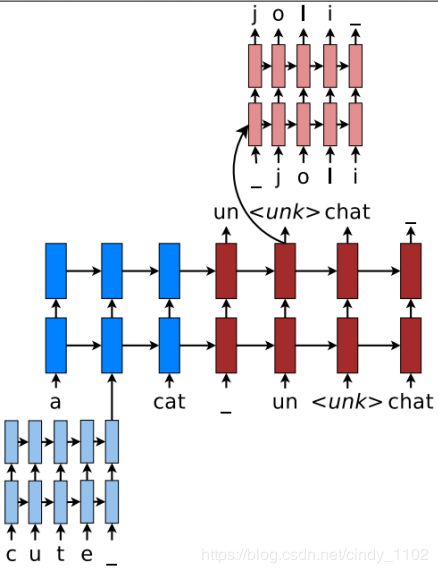
- 基于单词的翻译主干。混合NMT的核心是一个深层的LSTM编码器-解码器,可以在单词级进行翻译。为每种语言保留一个大小为 ∣ V ∣ |V| ∣V∣的词汇表,使用
表示表外词汇。 - 基于源字符的表示。在一般的基于单词的NMT中,一个通用的嵌入
用于表示所有表外单词。这种方法丢弃了关于源单词的有价值的信息。这里学习一个关于罕见字字符的深层LSTM,并使用LSTM的最终隐藏状态作为罕见字的表示。 - 目标字符级生成。一般基于单词的NMT允许在目标输出中生成
。这里的目标是创建一个能处理不限输出词汇表的框架。解决方案是使用一个单独的深层LSTM,在给定当前单词级状态下进行字符级“翻译”。注意,当前单词上下文用于初始化字符级编码器。该系统经过这样的训练,每当单词级NMT产生 时,就要求字符级解码器恢复未知目标单词的正确表面形式。