利用pydub和baidu语音api实现自动添加字幕
利用pydub和baidu语音api实现自动添加字幕
- 前言
- 程序介绍
- 基本工具
- 提取音频
- 修改pydub的silence.py
- 读取音频和预处理
- 切割音频转换成所需的WAV
- 字幕转换部分
- 百度API部分
- 注册和创建应用
- 认证
- 转换
- 完整程序
- 输出结果
前言
原来想翻译一段视频,下了某字幕工具,发现有ai听译的功能,但是未认证用户只能体验1分钟(申请了认证却不通过),想想原理也挺简单,就自己写了。
另外字幕精准程度根据视频源音频清晰以及口音问题有所增减,个人认为这个工具的主要功能是方便打时间轴,听译还是自己上吧。
github地址: audio2srt
程序介绍
基本工具
- 语言:python3.6
- 需要模块:pydub api
- 其他工具:狸窝或视频转音频工具,Adobe Audition或其他音频处理工具
提取音频
根据音频转换器的可输出格式,这里直接提取了wav格式的音频。百度语音识别API可以接受
pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式)
但是pydub自带的AudioSegment可以直接输出wav而不需要调用到ffmpeg,故wav在此处比较合适。
(可选)可以根据需要用Adobe Audition去噪,并且观察下大概底噪的的范围,后面用作silence_thresh的变量值。
修改pydub的silence.py
主要是把截取视频的时间戳返回来,以便字幕定位,这一步可以直接改或者另存为。
另:若是用pip安装模块,寻找silence.py可以通过pip show来实现。
def split_on_silence(audio_segment, min_silence_len=1000, silence_thresh=-16, keep_silence=100,
seek_step=1):
not_silence_ranges = detect_nonsilent(audio_segment, min_silence_len, silence_thresh, seek_step)
chunks = []
starttime=[]
endtime=[]
for start_i, end_i in not_silence_ranges:
start_i = max(0, start_i - keep_silence)
end_i += keep_silence
chunks.append(audio_segment[start_i:end_i])
starttime.append(start_i)
endtime.append(end_i)
return chunks,starttime,endtime
读取音频和预处理
预处理的目的是直接改成百度要求的:
录音参数必须符合 8k/16k 采样率、16bit 位深、单声道
且这样的音频体积较小后面处理起来比较快。
#读取音频 预处理
sound=AudioSegment.from_wav('.yinping/origin.wav')
sound=sound.set_frame_rate(16000)
sound=sound.set_channels(1)
切割音频转换成所需的WAV
split_on_silence的几个参数,大家按需改就好。注意silence_thresh变量可以用音频软件观察。
audio_segment :原始pydub.AudioSegment()对象
min_silence_len : (ms)用于切割一个沉默片段的最小长度 。默认值:1000毫秒
silence_thresh : (dBFS) 任何比这安静的值将被视为沉默。默认值:-16 dbfs
keep_silence :(ms) 在开始一端的块加入沉默值。使声音听起来不会像是突然切断。(默认值:100毫秒)
注意:
运行后会在指定文件夹生成切割后的片段,命名以0~N.wav,注意原始文件或其他重要音频不要被覆盖了。
#切割音频
min_silence_len=700
silence_thresh=-32
pieces,start_t,end_t=split_on_silence(sound,min_silence_len,silence_thresh)
silent = AudioSegment.silent(duration=1000)
#将音频转换为wav
def gotwave(audio):
new = AudioSegment.empty()
for inx,val in enumerate(audio):
new=val+silent
new.export('./yinping/%d.wav' % inx,format='wav')
字幕转换部分
一些格式的东西
- 时间换算只到分钟位,超过60分钟的音频不适用。(可以自己增加)
- 输出文件的为了方便查看这里用了txt格式,之后改文件名就行了。
- 一直把
srt写成str,有洁癖的朋友也可以自由改一下。
#毫秒换算 根据需要只到分
def ms2s(ms):
mspart=ms%1000
mspart=str(mspart).zfill(3)
spart=(ms//1000)%60
spart=str(spart).zfill(2)
mpart=(ms//1000)//60
mpart=str(mpart).zfill(2)
#srt的时间格式
stype="00:"+mpart+":"+spart+","+mspart
return stype
#输出字幕格式
def text2str(inx,text,starttime,endtime):
strtext=str(inx)+'\n'+ms2s(starttime)+' --> '+ms2s(endtime)+'\n'+text+'\n'+'\n'
return strtext
#读写文件
def strtxt(text):
with open('./yinping/yo.txt','a') as fp:
fp.write(text)
fp.close()
百度API部分
注册和创建应用
大家去看很友好的新手指南吧: 新手指南
然后得到:APP_ID API_KEYSECRET_KEY 这三个值就好。
认证
from aip import AipSpeech
#百度验证部分
APP_ID = 'your app_ID'
API_KEY = 'your API_KEY'
SECRET_KEY = 'your Secret_key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
转换
具体参数: 参数介绍
这里需要注意的是dev_pid这个参数,我这里是英语所以用了1737,普通话需要改参数。
另外返回的数据是dict型我以前用restapi做是json型,所以这里变量名很奇怪(不影响)。
#读取切割后的文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
#语音识别
def audio2text(wavsample):
rejson=client.asr(wavsample, 'wav', 16000, {'dev_pid': 1737,})
if (rejson['err_no']==0):
result=rejson['result'][0]
else:
result="erro"+str(rejson['err_no'])
return result
完整程序
# -*- coding: utf-8 -*-
"""
Created on Sun Mar 17 09:12:27 2019
@author: cindyyao
"""
from pydub import AudioSegment
import sys
import os
from pydub.silence import split_on_silence
from aip import AipSpeech
#百度验证部分
APP_ID = 'your app_ID'
API_KEY = 'your API_KEY'
SECRET_KEY = 'your Secret_key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
#读取音频 预处理
sound=AudioSegment.from_wav('.yinping/origin.wav')
sound=sound.set_frame_rate(16000)
sound=sound.set_channels(1)
#切割音频
min_silence_len=700
silence_thresh=-32
pieces,start_t,end_t=split_on_silence(sound,min_silence_len,silence_thresh)
silent = AudioSegment.silent(duration=1000)
#将音频转换为wav
def gotwave(audio):
new = AudioSegment.empty()
for inx,val in enumerate(audio):
new=val+silent
new.export('./yinping/%d.wav' % inx,format='wav')
#毫秒换算 根据需要只到分
def ms2s(ms):
mspart=ms%1000
mspart=str(mspart).zfill(3)
spart=(ms//1000)%60
spart=str(spart).zfill(2)
mpart=(ms//1000)//60
mpart=str(mpart).zfill(2)
#srt的时间格式
stype="00:"+mpart+":"+spart+","+mspart
return stype
#读取切割后的文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
#语音识别
def audio2text(wavsample):
rejson=client.asr(wavsample, 'wav', 16000, {'dev_pid': 1737,})
if (rejson['err_no']==0):
result=rejson['result'][0]
else:
result="erro"+str(rejson['err_no'])
return result
#输出字幕
def text2str(inx,text,starttime,endtime):
strtext=str(inx)+'\n'+ms2s(starttime)+' --> '+ms2s(endtime)+'\n'+text+'\n'+'\n'
return strtext
#读写文件
def strtxt(text):
with open('./yinping/yo.txt','a') as fp:
fp.write(text)
fp.close()
#main
if __name__ == '__main__':
gotwave(pieces)
for inx,val in enumerate(pieces):
wav=get_file_content('./yinping/%d.wav' % inx)
text=audio2text(wav)
text2=text2str(inx,text,start_t[inx],end_t[inx])
strtxt(text2)
print(str(round((inx/len(pieces))*100))+'%')
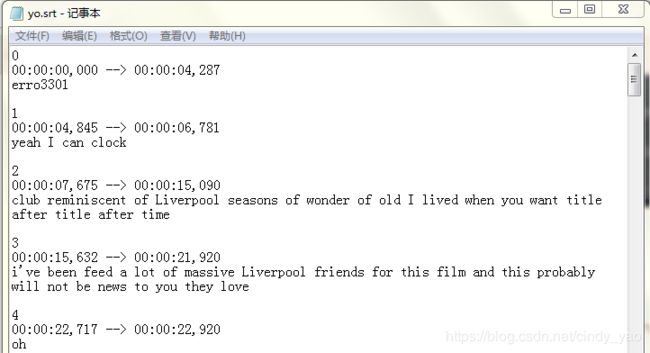
输出结果
大家可以看到如果是音乐片段被识别基本就是erro,这点是不如youtube的自动字幕的。听译部分基本过得去,但是有时间轴之后后续可以很方便的改字幕了。