django学习告一段落,又迎来一大难点---大数据!
学习大数据,我们需要安装好所需的一切软件与压缩包,安装教程度娘都有,伙伴们自个儿搜哦:
A.VM虚拟机、Centos镜像
B.Xshell
c.Xftp
d.jdk
f.hadoop
e.spark
1.简单了解一下xshell和xftp
Xshell是一款功能强大且安全的终端模拟器,支持SSH、SFTP、TELNET、RLOGIN和SERIAL ;Shell呢就是一个命令解释器,它把用户输入的命令解释一下并把它们送到内核去执行
Xftp是一个
可以
通过网络
,
实现本机与虚拟机互相
传输文件
的应用程序
2. 安装完成之后,进入虚拟机,编辑一下虚拟机设置
接下来:
(1)登录系统管理员,输入密码时是不会显示的,直接输完成按回车就进入了
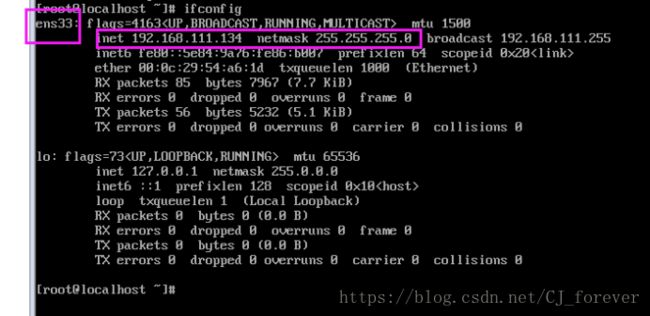
(2)获取虚拟机的ip [centos7版本下可以使用ip a ; 低版本须用ifconfig]
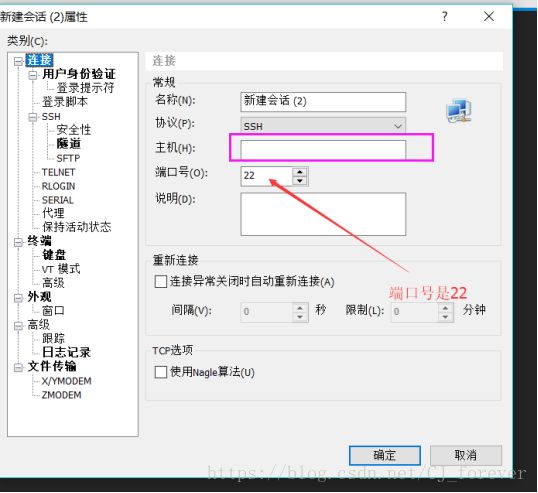
(3)打开xshell
1) 可以选择新建会话,就像这样,但需要写入刚才获取的虚拟机IP
2)直接使用ssh 加上虚拟机IP,去连接
输入之前你设置的用户名root 以及密码 root ,就OK
(4)下面就是linux的一系列操作指令:
cd / 根目录
cd.
cd .. 可进入上一层目录
cd - 进入上一个进入的目录
cd ~ 可进入用户的home目录
pwd 显示当前在哪个路径
ls 列出文件和目录
ls -a 显示隐藏文件
ls -l 显示常列表格式
mkdir 建立目录
rmdir 删除空目录
touch 建立新文件
rm 删除目录 (加上-r 是删除目录及其下面的所有文件)
mv 移动文件
rmdir 单纯地删目录,不删文件
cp 复制(cp data.txt data1.txt)
echo 输出内容
cat 查看纯文本文件(more查看更多)
head 查看前几行(head -n 2 )
> 重定向覆盖
>> 重定向 追加
(二)
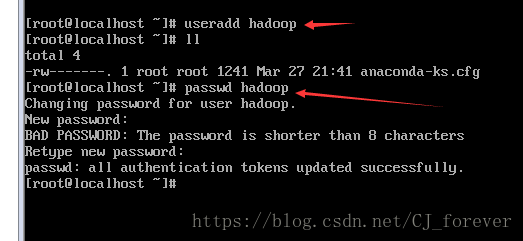
(1)创建一个新用户 useradd 或adduser +用户名,再设置一下密码
方便以后的登录,用户名跟密码保持一致(至于它提示密码短无效神马的,就不用去理会)
(2)对下面圈起来的地方,做一个解释:
root 登录系统的用户名
@表示在
localhost主机名
~表是目录
(3)了解一下linux里的目录结构
我们可以知道 root目录是系统管理员,权限是最大的,也被称为超级管理员 可以在这里更改一切权限
/home 这是用户的主目录;并且linux中 每一个用户都有自己的目录,目录名也就是账号的名字,如hadoop zhangsan
(4) 显示目录 pwd
这个在后面的环境变量配置的时候,会用的着
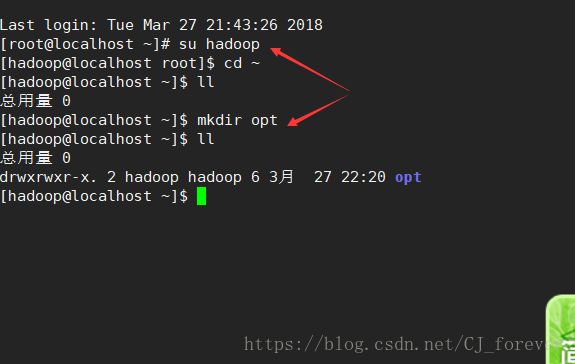
(5)切换用户,以及创建目录 都是一些指令操作,就不去细说了
(6) 这里是一个需要注意的地方-----
文件的权限
理解drwxrwxr-x:
文件权限属性
第一个字符表示文件类型(有d的是为目录)
目录
文件
链接
...
之后的每三个字符一组 表示读写执行权限(读就是查看,写就是修改,执行就是打开)
第一组 所有者(当前用户)
第二组 组(用户组)
第三组 其他(其他用户)
就像这个,所有者hadoop 对它有读、改写的权利 hadoop组也有,但其它用户只能读(readonly)
权限也可以用二进制、八进制表示:
r-- 100 4
r-x 101 5
rw- 110 6
rwx 111 7
如果需要修改权限,就要用到 chmod ; 对应的需要改变拥有者,使用 chown
(7)
讲一讲如何编辑文件:
vi +文件名 ----- 输入 i 进入编写模式,改完之后 按esc +shift +z[需要按两次] ;或者esc+ : wq
:wq 表示保存当前修改内容并退出
:q 不保存直接退出
:q! 强制性退出
编辑完成之后,我们使用su 切换到其它用户,来查看当前的文件
cat+文件名
发现可以查看,说明有读的权限;接着尝试去更改 vi一下,发现动不了,还会给出警告:
这里涉及的又是上一步的权限问题,伙伴们自己尝试着去改改吧
(三)
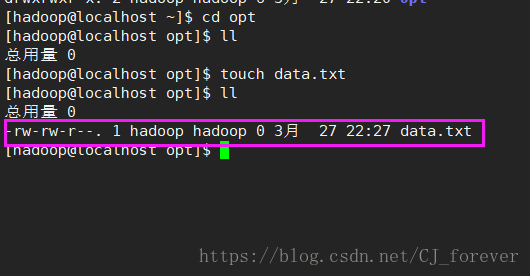
(1)在hadoop用户下,mkdir创建一个opt目录,用来解压压缩包
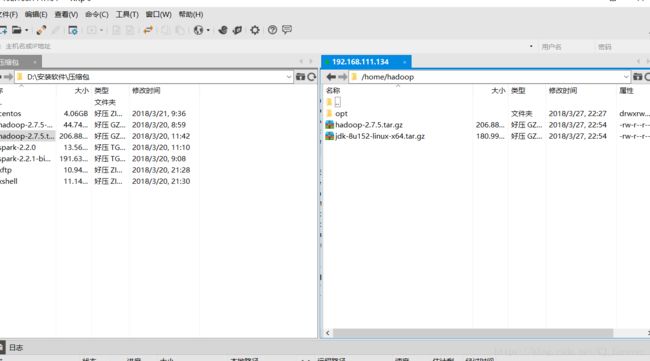
这个地方,就能看出来xftp的作用了,传输文件
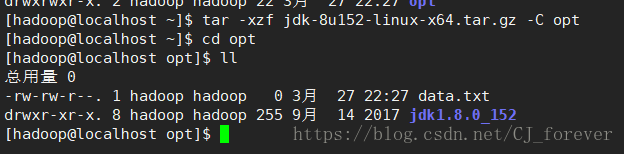
我们把后期需要的 jdk 和hadoop压缩包,上传至/home/hadoop ,再解压至opt目录下
这样的状态,表示成功!同样的hadoop也是这样操作
(2
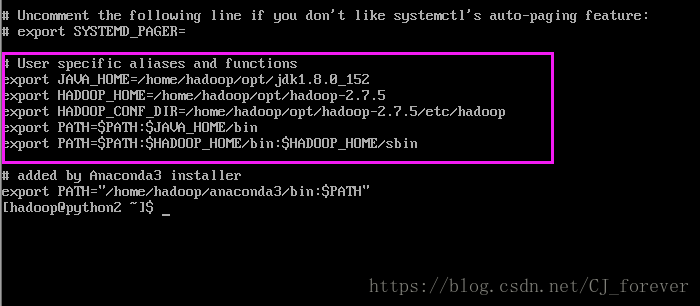
)解压完成之后,就开始配置环境变量:
两种方法:我习惯使用 vi
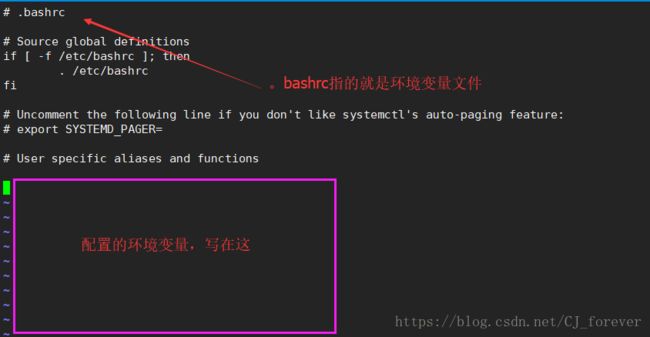
配置好之后应该是这样的:
为什么这样去配置呢?
伙伴们可以自己去想一下 ,尤其是最后两行,
为什么配置PATH的时候,等于号后面加上$PATH
?
还有 加上 /bin /sbin ,有啥用呢??
注意:每一次配置完环境变量,都需要去刷新一遍 source .bashrc
再输入 java hadoop ,查看一下生效了没
这样就表示环境变量,配置的没毛病!
另一种编辑 echo ,伙伴们自己去尝试吧,这里就不写了
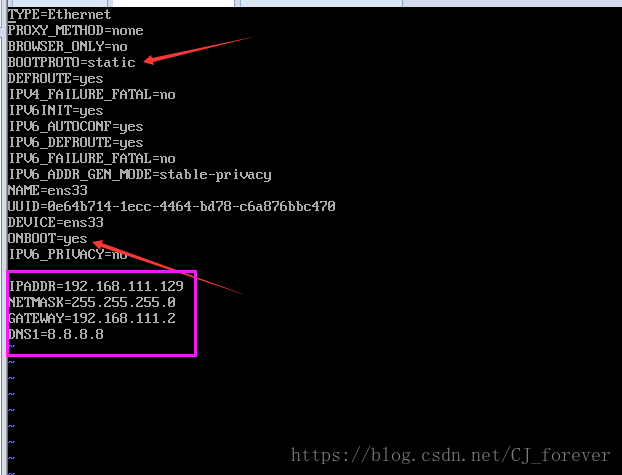
(四)环境变量没毛病了,下面对IP进行修改,将动态改成静态
1.这些操作需要切换到root下,否则没有权限,无法进行修改
忘记网段了,可以再去查看一遍,输入
ifconfig
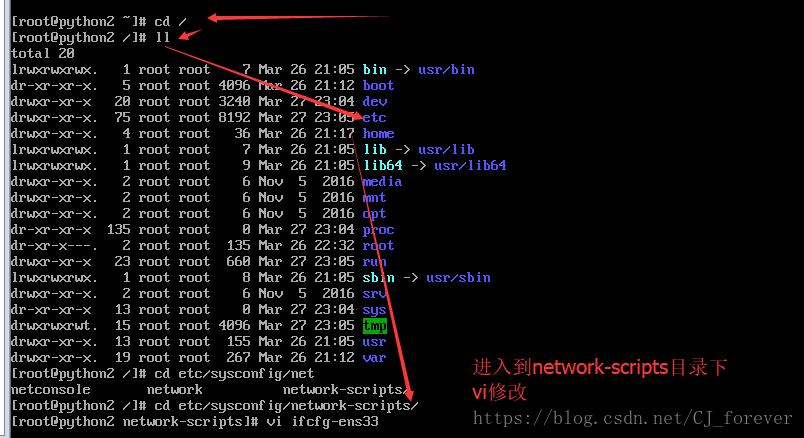
进入到 root 的 /目录下执行这步操作
不知道哪个目录下,有哪些文件,就要习惯性地去使用指令 ll 查看(这个是L的小写)
改成这样,就OK了!
(2)配置完静态IP,需要重启网络 systemctl restart network
(3) 输入 ssh 192.168.111.129 查看一下刚才的配置是否生效了 ,能连上 这一块也没毛病了!
2.修改主机名跟映射
(1)还是要进入root 超级用户管理员下
更改两处地方hosts hostname , 分别 vi 进入
vi /etc/hostname vi /etc/hosts
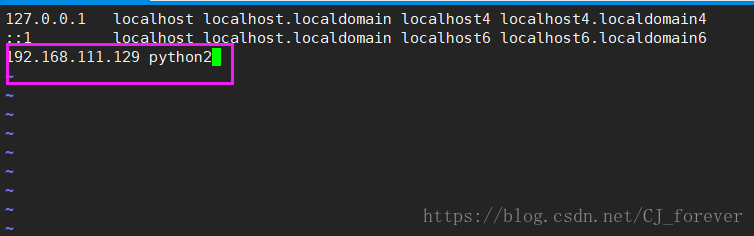
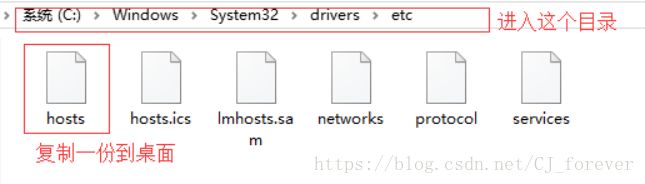
修改完成之后,千万别忘了去咱本机 C:/Windows/system32/drivers/etc/hosts 里面,把刚才在hosts里写的东西添加进去
这步操作,注意是不能直接修改的,需要复制一份到桌面,改完再拉进去替换掉
执行reboot去重启一下!
(2)重新去连接一下linux
3.进入配置目录 cd $HADOOP_CONF_DIR
(1) 看到圈起来的5个文件了吧,接下来做的就是对其进行配置,可以根据hadoop官网进行
给个示范吧,配置第一个文件 core-site.xml
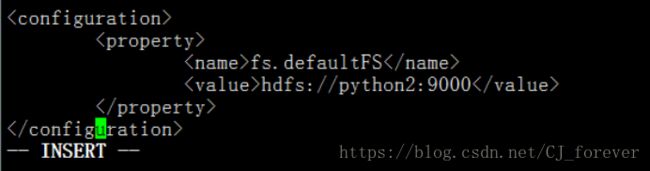
最后一个文件 yarn-site.sh 配置的时候,需要注意的是:第二个里写的是mapreduce_shuffle
(2)接下来修改slaves,将里面的localhost 改成 python2
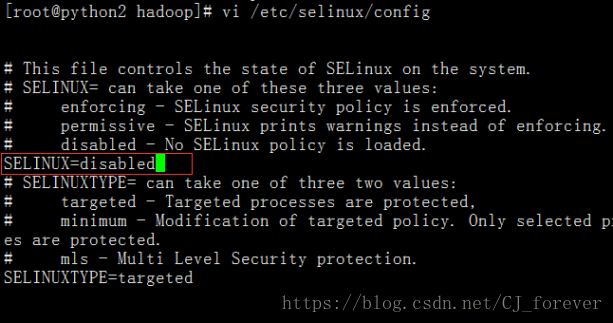
4.关闭防火墙以及selinux
(1)再次切换到root
注意seliux里面,修改的是圈起来的地方,而不是最后一行! 不要改错给自己找麻烦
重启一下机器!!! reboot
(2)重新连接,登录hadoop
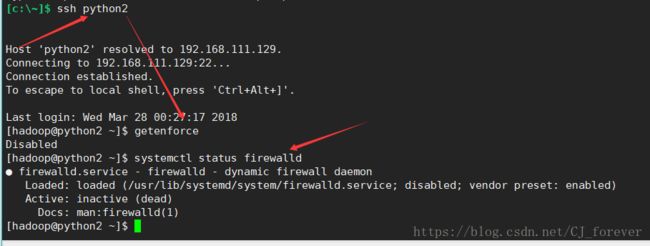
状态显示,都是关闭的
(3)执行hdfs 文件系统格式化 hdfs namenode -format
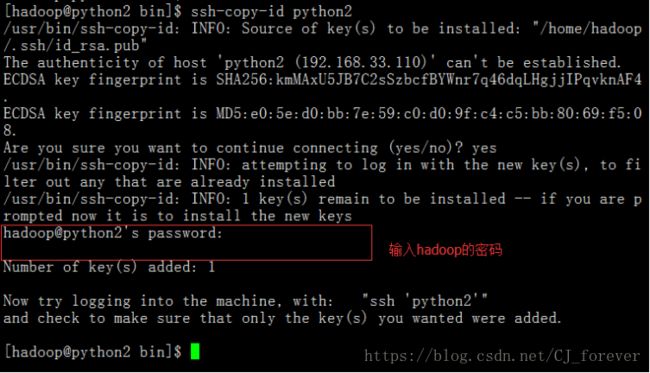
5.配置ssh无密码登录
(1)输入 ssh-keygen -t rsa
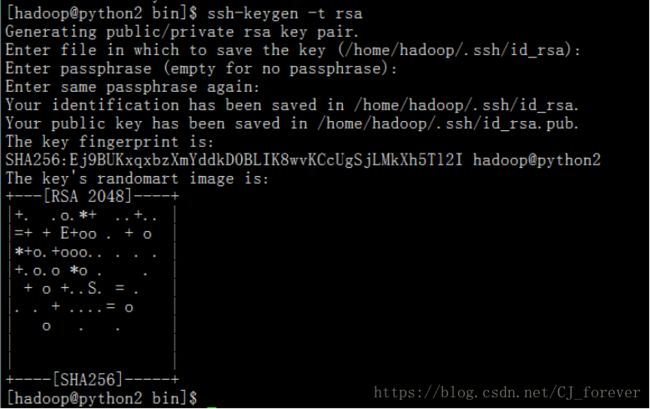
这样的状态说明是对的,接着下一步:ssh-copy-id + 想要登录到的主机名 输入hadoop密码
6.
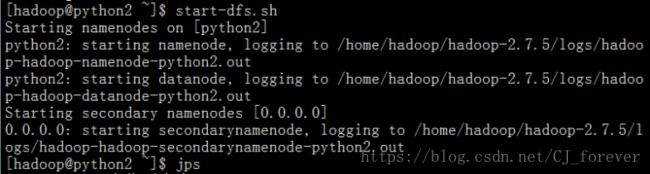
启动服务 start-dfs.sh(如果没有配置ssh 无密码登录,那么这里会一直提示输入密码)
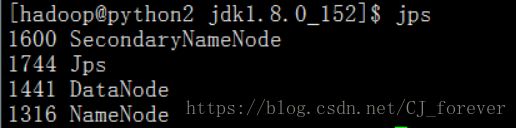
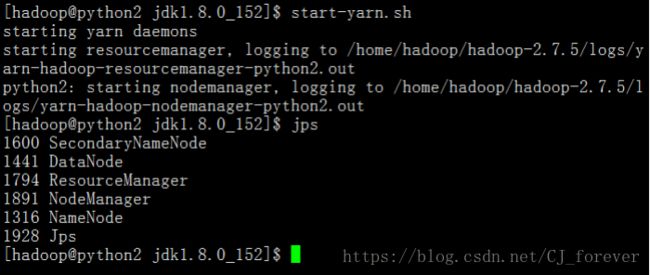
jps查看一下节点,发现起了3个
再启动 start-yarn.sh 并jps查看
7.
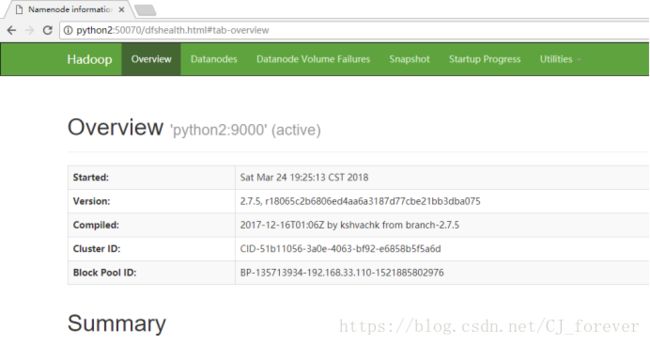
浏览器访问,输入 python2:50070
可以成功显示,一路畅通过来
文件上传:
(1)新建一个文件 touch data.txt ,往里面添加一些内容,保存并退出
(2)开始上传:
(3)查看一下,进去后可以一直找到 data.txt
(五)Anaconda安装
(1)安装的步骤都差不多,安完了就是环境变量的问题
(2) 我写一下过程中遇到的问题
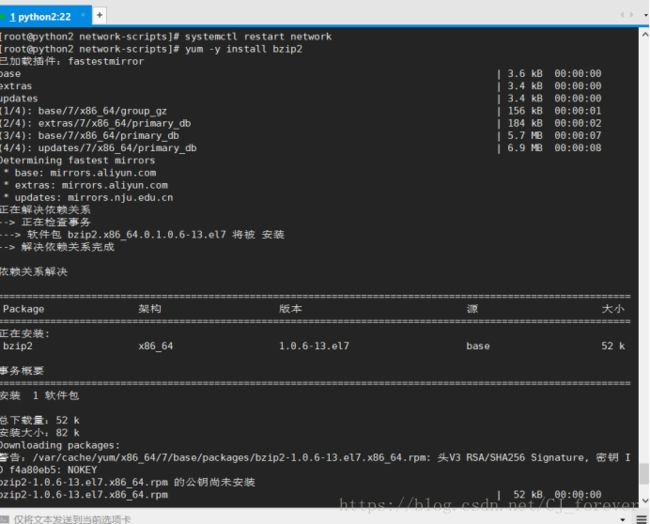
在root下执行yum -y install bzip2 ,我碰到了这个情况
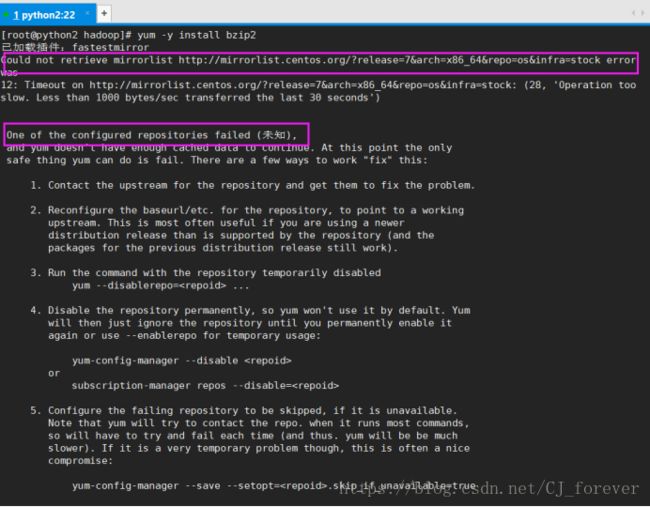
我就又执行一遍 systemctl restart network , 就可以了
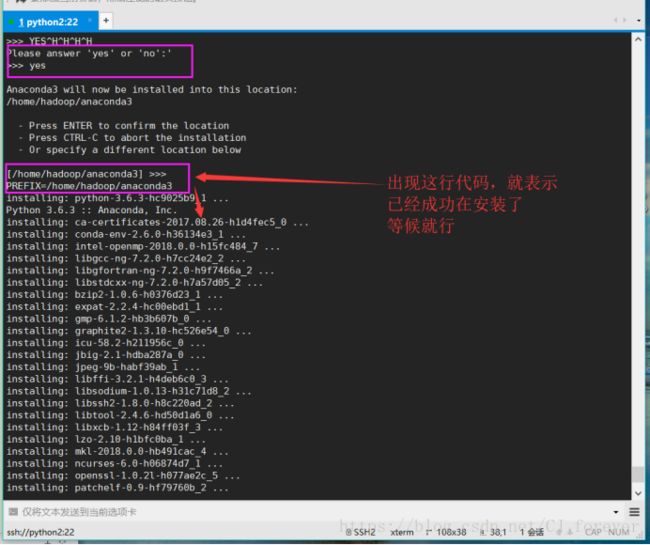
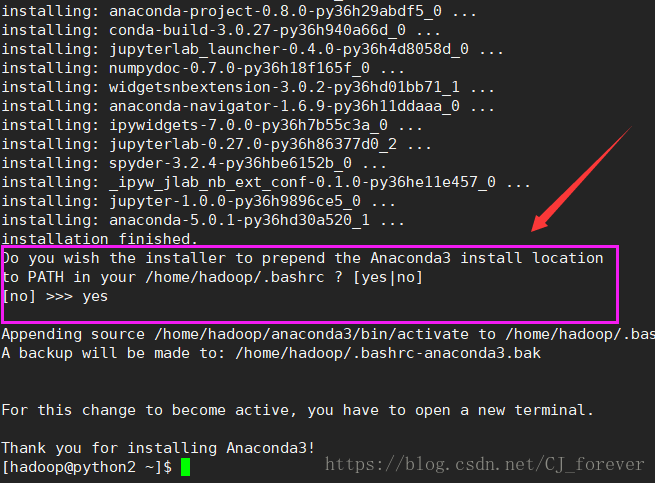
回到hadoop ,执行[hadoop@python2~]$bash Anaconda3-5.0.1-Linux-x86_64.sh
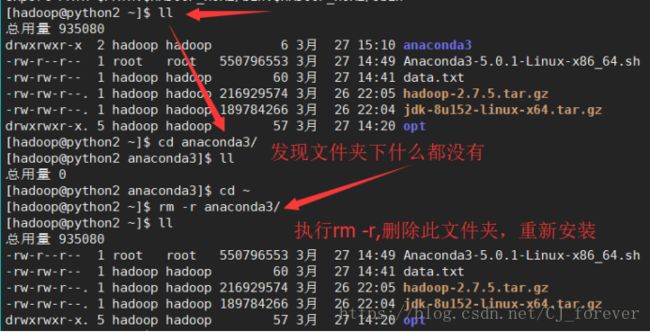
我安装失败了。。。
就执行了下面图片中的操作,因为安装失败,也会产生一个文件夹
又执行了一遍,注意我圈起来的地方
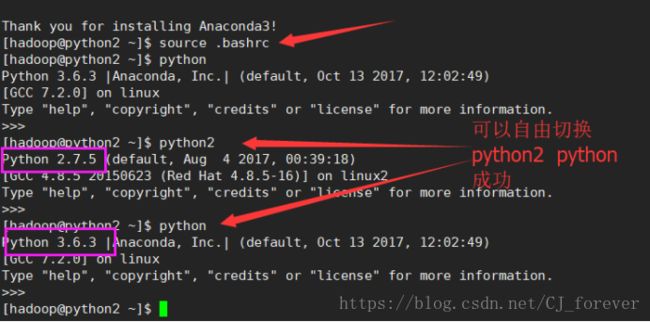
成功之后,刷新一下环境变量source .bashrc,再输入python 查看是否变成了 python3.6.3
这样就对了!!
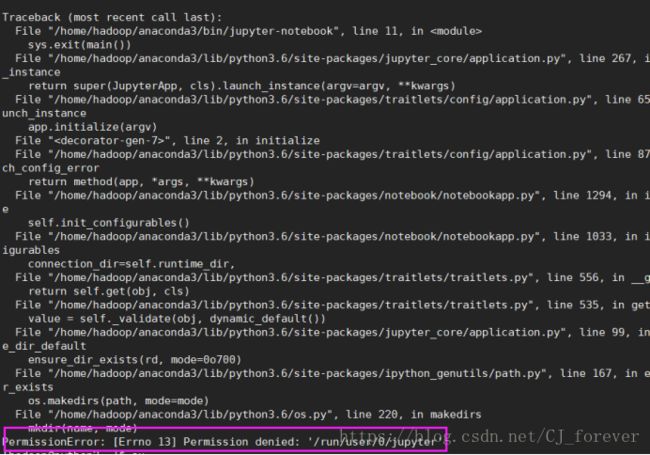
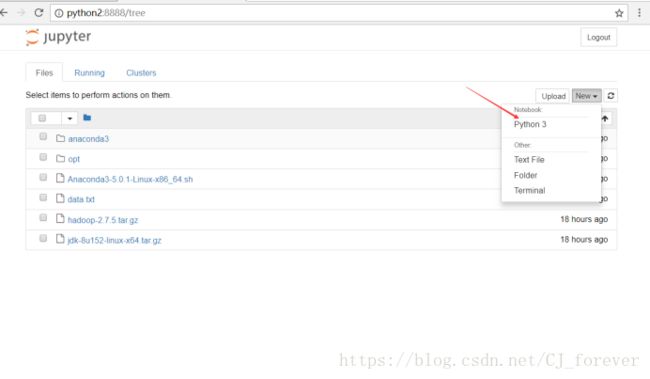
(3) 我执行 jupyter-notebook --ip python2 出现了下面的错误
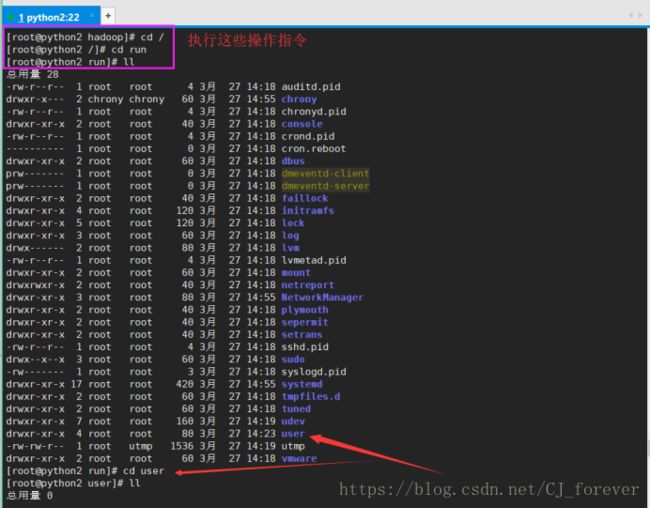
执行下面图片中的指令
发现好了,没毛病
复制此处的网址,粘贴至浏览器
终于大功告成!!