回归预测及R语言实现 Part2 回归R语言实现
下面是回归分析的各种变体的简单介绍,解释变量和相应变量就是指自变量和因变量。

常用普通最小二乘(OLS)回归法来拟合实现简单线性、多项式和多元线性等回归模型。最小二乘法的基本原理前面已经说明了,使得预测值和观察值之差最小。
R中实现拟合线性模型最基本的函数是lm(),应用格式为:
myfit <- lm(Y~X1+X2+…+Xk,data)
data为观测数据,应该为一个data.frame,前面是拟合表达式,Y是因变量,X1-Xk是自变量,+用来分隔不同的自变量的,还有可能用到的其他符号的说明如下:

另外,对lm()方法的返回结果,还有一系列的分析方法,如下:

简单线性回归
基础安装数据women中提供了15个年龄在30-39岁之前的女性的身高和体重信息,这里用身高来预测体重,来尝试lm()方法
par(ask = TRUE)
opar <- par(no.readonly = TRUE)
fit <- lm(weight ~ height, data = women)
summary(fit)
women$weight
fitted(fit)
residuals(fit)
plot(women$height, women$weight, main = "30-39的女性",xlab = "身高(英尺)", ylab = "体重(镑)")#观测数据散点图
abline(fit)#拟合线

由summary(fit)的结果coefficients可看出,预测模型为:weight=-81.52+3.45*height。
因为身高不可能为0,你没必要给截距项一个物理解释,它仅仅是一个常量调整项。在Pr(>|t|)栏,可以看到回归系数(3.45)显著(p<0.001),表明身高每增高1英寸,体重将预期增加3.45磅。可决系数-R平方项(0.991)表明模型可以解释体重99.1%的方差,它也是实际和预测值之间的相关系数的平方值。残差标准误差(1.53 lbs)则可认为是模型用身高预测体重的平均误差。F统计量检验所有的预测变量预测响应变量是否都在某个几率水平之上。由于简单回归只有一个预测变量,此处F检验等同于身高回归系数的t检验。
多项式回归
从上面例子最后的图可以看出,我们可以为回归模型增加一个X平方项来增加预测精确度。
fit2 <- lm(weight ~ height + I(height^2), data = women)
summary(fit2)
plot(women$height, women$weight, main = "30-39的女性",xlab = "身高(英尺)", ylab = "体重(镑)")#观测数据散点图
lines(women$height, fitted(fit2))

由summary(fit2)的结果coefficients可看出,预测模型为:weight=261.88-7.35*height+0.083* height* height。在p<0.001水平下,回归系数都非常显著。模型的方差解释率已经增加到了99.9%。二次项的显著性(t = 13.89,p<0.001)表明包含二次项提高了模型的拟合度。从图中也能看出来,预测值和观测值的拟合程度更好了。
介绍下car包中的scatterplot()函数,它可以很容易、方便地绘制二元关系图。
library(car)
scatterplot(weight ~ height, data = women,spread = FALSE, lty.smooth = 2, pch = 19, main ="30-39的女性", xlab = "身高(英尺)", ylab = "体重(镑)")
多元线性回归
这里以基础包中的state.x77数据集为例,探究一个州的犯罪率和其他因素的关系,包括人口、文盲率、平均收入和结霜天数(温度在冰点以下的平均天数)。
states <- as.data.frame(state.x77[, c("Murder","Population", "Illiteracy", "Income","Frost")])
colnames(states) <- c("谋杀率", "人口","文盲率", "收入水平", "结霜天数")
cor(states)
library(car)
scatterplotMatrix(states, spread = FALSE, main = "ScatterplotMatrix")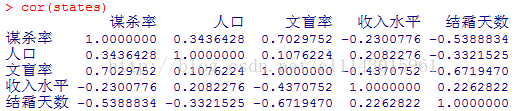
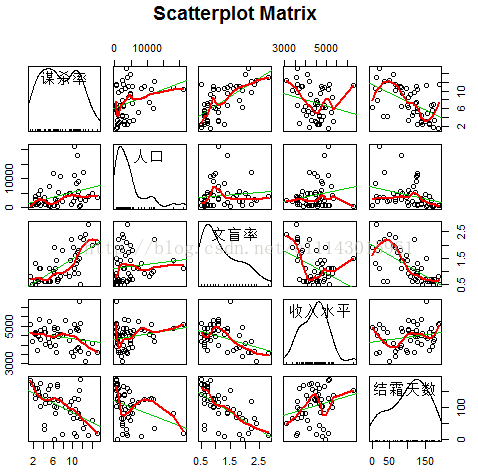
cor()函数显示两个变量之间的相关系数,从图中可以看到,谋杀率是双峰的曲线,每个预测变量都一定程度上出现了偏斜。谋杀率随着人口和文盲率的增加而增加,随着收入水平和结霜天数增加而下降。同时,越冷的州文盲率越低,收入水平越高。
下面对states数据做多项线性拟合,看人口、文盲率、收入水平、结霜天数对谋杀率的影响水平。
colnames(states) <- c("Murder", "Population","Illiteracy", "Income", "Frost")
fit <- lm(Murder ~ Population + Illiteracy + Income + Frost, data= states)
summary(fit)
从结果可以看出,文盲率和人口的系数是显著的,结霜率和收入水平系数不显著,这两者对谋杀率的影响不是线性的。
上面的例子是自变量之间相互独立的,下面看一个有交互项的多元线性回归的案例。同样是R中的基础安装数据mtcars,
fit <- lm(mpg ~ hp + wt + hp:wt, data = mtcars)
summary(fit)
从summary(fit)的Pr(>|t|)栏中能看出,hp:wt项是显著的,说明汽车的马力和车重不是相互独立的,两者对每英里的耗油量的影响也都是显著的。
汽车每英里耗油量mpg的模型为mpg =49.81 + 0.12×hp + 8.22×wt + 0.03×hp×wt。
effects包可以用来分析不同wt下,mpg与hp之间的线性关系。如下,图中能看出,当wt分别为2.2,3.2,4.2时mpg与hp之间的线性关系,差异还是很明显的。
library(effects)
plot(effect("hp:wt", fit, xlevels= list(wt = c(2.2, 3.2,4.2))), multiline = TRUE)
回归诊断
summary()方法能获取模型的参数和相关统计量,要进一步诊断模型是否合适,还需要另外的工作。
R中有许多检验回归分析中统计假设的方法。plot()方法可以生成评价模型拟合情况的四幅图形。用women数据集的回归模型为例:
fit <- lm(weight ~ height, data = women)
par(mfrow = c(2, 2))
plot(fit)
par(opar)
OLS回归的统计假设。(担心我自己的理解有偏误,所以这里的解读全部摘抄自R语言实战!)
正态性当预测变量值固定时,因变量成正态分布,则残差值也应该是一个均值为0的正态分布。正态Q-Q图(Normal Q-Q,右上)是在正态分布对应的值下,标准化残差的概率图。若满足正态假设,那么图上的点应该落在呈45度角的直线上;若不是如此,那么就违反了正态性的假设。
独立性你无法从这些图中分辨出因变量值是否相互独立,只能从收集的数据中来验证。上面的例子中,没有任何先验的理由去相信一位女性的体重会影响另外一位女性的体重。假若你发现数据是从一个家庭抽样得来的,那么可能必须要调整模型独立性的假设。
线性若因变量与自变量线性相关,那么残差值与预测(拟合)值就没有任何系统关联。换句话说,除了白噪声,模型应该包含数据中所有的系统方差。在“残差图与拟合图”(Residuals vs Fitted,左上)中可以清楚的看到一个曲线关系,这暗示着你可能需要对回归模型加上一个二次项。
同方差性若满足不变方差假设,那么在位置尺度图(Scale-Location Graph,左下)中,水平线周围的点应该随机分布。该图似乎满足此假设。
最后一幅“残差与杠杆图”(Residualsvs Leverage,右下)提供了你可能需要关注的单个观测点的信息。从图形可以鉴别出离群点、高杠杆值点和强影响点。
一个观测点是离群点,表明拟合回归模型对其预测效果不佳(产生了巨大的或正或负的残差)。
一个观测点有很高的杠杆值,表明它是一个异常的预测变量值的组合。也就是说,在预测变量空间中,它是一个离群点。因变量值不参与计算一个观测点的杠杆值。
一个观测点是强影响点(influentialobservation),表明它对模型参数的估计产生的影响过大,非常不成比例。强影响点可以通过Cook距离即Cook’s D统计量来鉴别。
再来看二次拟合的诊断图。
newfit <- lm(weight ~ height + I(height^2), data = women)
par(mfrow = c(2, 2))
plot(newfit)
par(opar)
图中有两个比较明显的离群点,12和15,可以删除这两个点后再做回归,效果会更好。
newfit <- lm(weight ~ height + I(height^2), data = women[-c(13,15),])
par(mfrow = c(2, 2))
plot(newfit)
par(opar)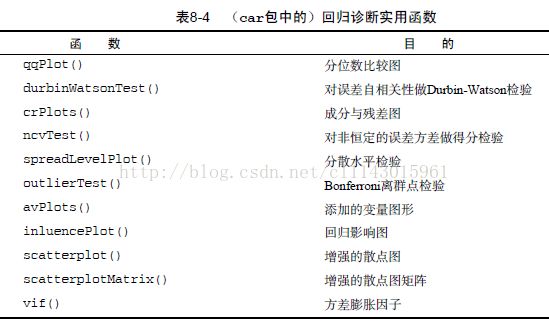
参考:R语言实战(所以例子都来自于这本书,强烈推荐这本书!)
有任何问题建议欢迎指出,转载请注明来源,谢谢!