pytorch学习笔记6--过拟合,交叉验证,正则化
文章目录
- 过拟合
- 过拟合、欠拟合
- 交叉验证
- regularization
- 动量与学习率衰减
- dropout ,early stop
- 卷积神经网络
- resnet densenet
- nn.Module
- 数据增强
- 实战
- lenet5
- resnet
过拟合
过拟合、欠拟合
交叉验证
regularization
- occam’s razor
- more things should not be used than are necessary
- reduce overfitting
- more data
- constraint model complexity
- shallow
- regularization
- J ( θ ) = − 1 m ∑ i = 1 m [ y i l n y 1 + ( 1 − y i ) l n ( 1 − y i ) ] + λ ∑ i = 1 n ∣ θ i ∣ J(\theta) = - \frac{1}{m} \sum^m_{i=1} [y_iln y_1 +(1-y_i)ln(1-y_i)]+\lambda \sum^n_{i=1} |\theta_i| J(θ)=−m1i=1∑m[yilny1+(1−yi)ln(1−yi)]+λi=1∑n∣θi∣
- J ( W ; X , y ) + 1 / 2 λ ∗ ∣ ∣ W ∣ ∣ 2 J(W;X,y) + 1/2 \lambda * ||W||^2 J(W;X,y)+1/2λ∗∣∣W∣∣2
- enforce weights close to 0
- dropout
- data argumentation
- early stopping
L2-regularization
device = torch.device('cuda:0,1')
net = MLP().to(device)
# weight_decay=0.01 即 lambda=0.01
optimizer = optim.SGD(net.parameters(), lr= learning_rate, weight_decay=0.01)
L1-regularization
regularization_loss = 0
for param in model.parameters():
regularization_loss += torch.sum(torch.abs(param))
classify_loss = criteon(logits,target)
loss = classify_loss + 0.01 * regularization_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
动量与学习率衰减
dropout ,early stop
- early stop
- validation set to select parameters
- monitor validation performance
- stop at the highest val perf
- dorpout
- learning less to learn better
- each connection has p=[0,1] to lose
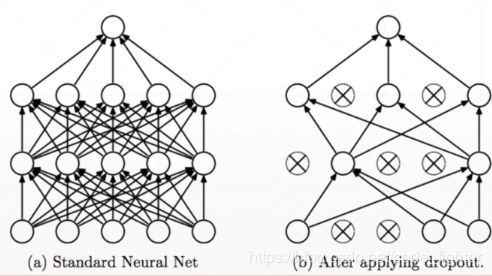
dorpout
net_dropped = torch.nn.Sequential(
torch.nn.Linear(784,200)
torch.nn.Dropout(0.5)
torch.nn.ReLU()
torch.nn.Linear(200,200)
torch.nn.Dropout(0.5)
torch.nn.ReLU()
torch.nn.Linear(200,10)
)
卷积神经网络
resnet densenet
- filter = kernel = weight
resnet
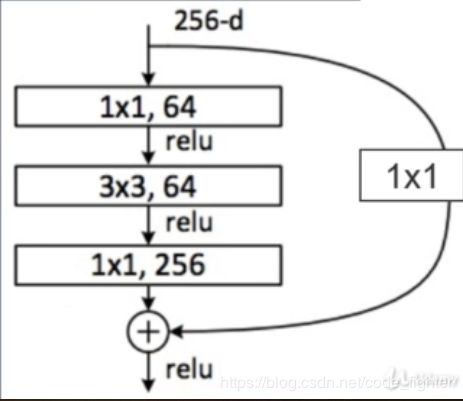
class ResBlk(nn.Module):
def __init__(self,ch_in,ch_out):
self.conv1 = nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=1,padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out,ch_out,kernel_size=3,stride=1,padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
self.extra = nn.Sequential(
nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=1),
nn.BatchNorm2d(ch_out)
)
def forward(self,x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out = self.extra(x) + out
return out
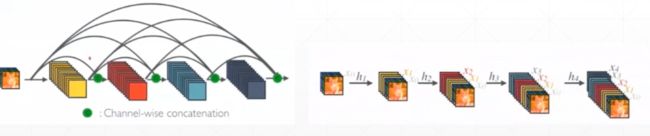
DenseNet
nn.Module
使用nn.Module的好处
- 提供了大量的模块
- Linear
- ReLU
- Sigmoid
- Conv2d
- ConvTransposed2d
- Dropout
- etc.
- 容器(Container):nn.Sequential()
- parameters ,易于管理参数
- eg: optimizer = optim.SGD(net.parameters(),lr=le-3)
- modules:对类内部module也进行了管理
- modules:all nodes
- children(直接结点):direct children
- to(device)
- 对于一个tensor a, 需要写成 a = a.to(device)
- 对于一个网络net, 可以直接写成 net.to(device)
- save and load
device = torch.device('cuda')
net = Net()
net.to(device)
net.load_state_dict(torch.load('ckpt.mdl'))
# train ...
torch.save(net.state_dict(),'ckpt.mdl')
-
train/test
- net.train()
- net.eval()
-
implement own layer (只有class才能写到Sequential里面去)
class Flatten(nn.Module):
def __init__(self):
super(Flatten,self).__init__()
def forward(self,input):
return input.view(input.size(0),-1)
class TestNet(nn.Module):
def __init__(self):
super(TestNet,self).__init__()
self.net = nn.Sequential(
nn.Conv2d(1,16,stride=1,padding=1,)
nn.MaxPool2d(2,2),
Flatten(),
nn.Linear(1*14*14,10)
)
def forward(self,x):
return self.net(x)
class MyLinear(nn.Module):
def __init__(self,inp,outp):
super(MyLinear,self).__init__()
# nn.Parameter 会把tensor加入到网络的parameter中取管理,并且在优化器中进行优化
self.w = nn.Parameter(torch.randn(outp,inp))
self.b = nn.Parameter(torch.randn(outp))
def forward(self,x):
x = x@self.w.t() + self.b
return x
数据增强
- data argumentation
-
flip

- transforms.RandomHorizontalFlip()
- transforms.RandomVerticalFlip()
-
rotate

- transforms.RandomRotation(15) # -15度~15度之间的一个角度
- transforms.RandomRotation([90,180,270]) # 从90,180,270度三个中随机的挑一个进行旋转
-
scale

- transforms.Resize([32,32])
-
crop part

- transforms.RandomCrop([28,28])
-
noise
-
gan
-
- data argumentation will help,but not too much

实战
lenet5
import torchfrom torch
import nnfrom torch.nn
import functional as F
class Lenet5(nn.Module):
def __init__(self):
super(Lenet5,self).__init__()
self.conv_unit = nn.Sequential(
nn.Conv2d(3,6,kernel_size=5,stride=1,padding=0),
nn.AvgPool2d(kernel_size=2,stride=2,padding=0),
nn.Conv2d(6,16,kernel_size=5,stride=1,padding=0),
nn.AvgPool2d(kernel_size=2,stride=2,padding=0),
)
# flatten
# fc unit
self.fc_unit = nn.Sequential(
nn.Linear(16 * 5* 5,120),
nn.ReLU(),
nn.Linear(120,84),
nn.ReLU(),
nn.Linear(84,10)
)
# use Cross Entropy Loss
# Cross Entropy Loss 包含了softmax操作
self.criteon = nn.CrossEntropyLoss()
def forward(self, x):
'''
:param x: [b,3,32,32]
:return:
'''
batchse = x.size(0)
# [b,3,32,32] => [b,16,5,5]
x = self.conv_unit(x)
# [b,16,5,5] => [b,16*5*5]
x = x.view(batchse,16*5*5)
# [b, 16*5*5] => [b,10]
logits = self.fc_unit(x)
# pred = F.softmax(logits,dim=1)
# 因为Corss Entropy Loss 包含softmax操作,所以不需要softmax了
# loss = self.criteon(logits,target)
return logits
def main():
net = Lenet5()
tmp = torch.randn(2,3,32,32)
out = net(tmp)
print('conv out:',out.shape)
if __name__ == '__main__':
main()
:conv out: torch.Size([2, 10])
import torch
from torch.utils.data
import DataLoader
from torchvision import datasets
from torchvision import transforms
def main():
batchsz = 32
# 每次只加载一张图片
cifar_train = datasets.CIFAR10('cifar',True, transform=transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor()
]),download=True)
# 加载多张图片
cifar_train = DataLoader(cifar_train,batch_size=batchsz,shuffle=True)
cifar_test = datasets.CIFAR10('cifar',False,transform=transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor()
]),download=True)
cifar_test = DataLoader(cifar_test,batch_size=batchsz,shuffle=True)
x,label = iter(cifar_train).next()
print('x:',x.shape,'label:',label.shape)
device = torch.device('cuda')
model = Lenet5().to(device)
criteon = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=1e-3)
# train
model.train()
for epoch in range(1000):
for batchidx, (x,label) in enumerate(cifar_train):
x,label = x.to(device),label.to(device)
logits = model(x)
loss = criteon(logits,label)
# backward()
optimizer.zero_grad() # 每次会把梯度累加,所以需要清零
loss.backward() # 计算梯度,累加
optimizer.step() # 更新梯度到weight
print(epoch,loss.item())
# test
model.eval()
with torch.no_grad():
total_correct = 0
total_num = 0
for x, label in cifar_test:
x,label = x.to(device),label.to(device)
logits = model(x)
pred = logits.argmax(dim=1)
total_correct +=
torch.eq(pred,label).float().sum().item()
total_num += x.size(0)
acc = total_correct / total_num
print(epoch,acc)
if __name__ == '__main__':
main()
resnet
import torchfrom torch
import nnfrom torch.nn
import functional as F
class ResBlk(nn.Module):
''' resnet block '''
def __init__(self,ch_in,ch_out):
'''
:param ch_in:
:param ch_out:
'''
super(ResBlk,self).__init__()
self.conv1 = nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=3,padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out,ch_out,kernel_size=3,stride=1,padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
# [b,ch_in,h,w] => [b,ch_out,h,w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=1),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut
# extra module: [b,ch_in,h,w] => [b,ch_out,h,w]
# element-wise add
out = self.extra(x) + out
return out
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=2,stride=1,padding=1),
nn.BatchNorm2d(64)
)
# followed 4 blocks
# [b,64,h,w] => [b,128,h,w]
self.blk1 = ResNet18(64,128)
# [b,128,h,w] => [b,256,h,w]
self.blk2 = ResNet18(128,256)
# [b,256,h,w] => [b,512,h,w]
self.blk3 = ResNet18(256,512)
# [b,512,h,w] => [b,1024,h,w]
self.blk4 = ResNet18(512,1024)
self.outlayer = nn.Linear(512*h*w,10)
def forward(self, x):
'''
:param x:
:return:
'''
x =F.relu(self.conv1(x))
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
x = x.view(x.size(0),-1)
x = self.outlayer(x)
return x