(十二)利用 vecstacks 自动进行 stacking
作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
(一)机器学习中的集成学习入门
(二)bagging 方法
(三)使用Python进行交易的随机森林算法
(四)Python中随机森林的实现与解释
(五)如何用 Python 从头开始实现 Bagging 算法
(六)如何利用Python从头开始实现随机森林算法
(七)AdaBoost 简介
(八)Python 中的 AdaBoost 分类器实例
(九)AdaBoost 中参数对于决策边界复杂度分析
(十)stacking 简介
(十一)为什么堆叠的集成模型容易赢得 kaggle 比赛?
(十二)利用 vecstacks 自动进行 stacking
介绍
在将机器学习算法推向新的高度时,利用堆栈(堆栈式泛化)是一个非常热门的话题。例如,如今大多数获胜的 Kaggle 提交都使用某种形式的堆栈或其变体。最初由 David Wolpert 在1992年的论文 Stacked Generalization 中介绍,他们的主要目的是减少泛化错误。根据 Wolpert 的说法,他们可以被理解为“更复杂的交叉验证版本”。虽然Wolpert 当时注意到大部分堆栈是“黑色艺术”,但似乎构建越来越大的堆栈泛化胜过更小的堆栈泛化。然而,随着这些模型的大小不断增加,它们的复杂性也会增加。自动化构建不同体系结构的过程将大大简化此过程。本文的其余部分将讨论我最近遇到的软件包 vecstack 正在尝试这样做。
堆栈泛化是什么样的?
堆栈泛化结构背后的主要思想是使用一个或多个第一级模型,使用这些模型进行预测,然后将这些预测用作特征以在顶部拟合一个或多个第二级模型。 为了避免过度拟合,交叉验证通常用于预测训练集的OOF(out of fold)部分。 这个包中有两种不同的变体,但我将在本段中描述“变体A”。 为了得到这个变体的最终预测,我们采用所有预测的均值。 整个过程可以使用vecstacks文档中的这个GIF进行可视化:
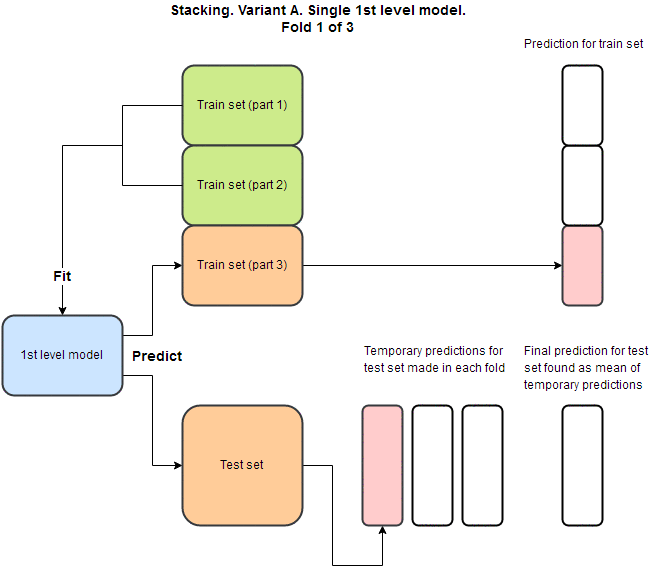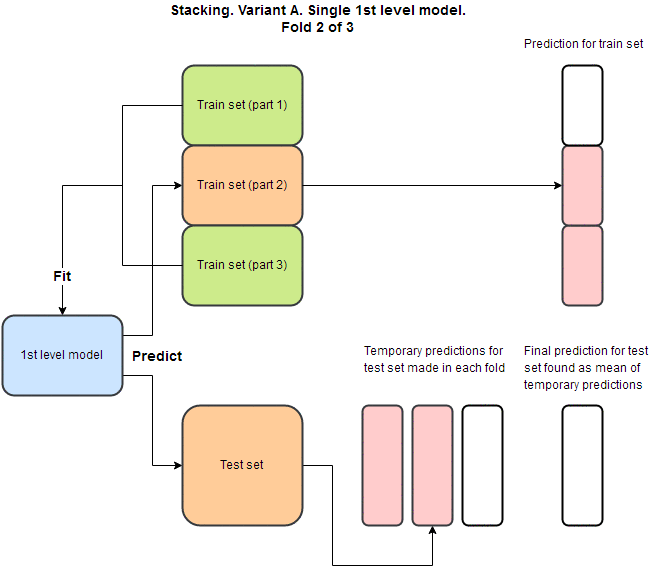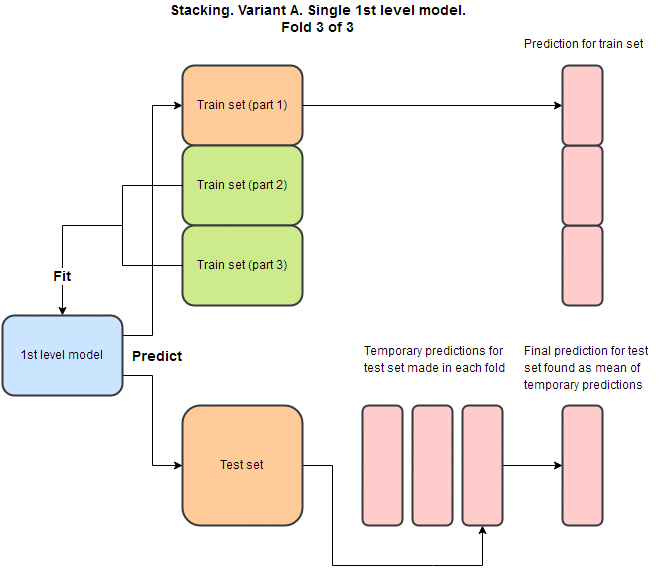
使用案例:构建用于分类的堆栈泛化模型
看完文档之后,是时候尝试自己使用这个包了,看看它是如何工作的。 为此,我决定使用UCI机器学习库中提供的葡萄酒数据集。 该数据集的问题是使用13个特征,这些特征都代表葡萄酒的不同方面,以预测葡萄酒是来自意大利的三个品种中的哪一个。
首先,让我们导入我们项目所需的软件包:
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from vecstack import stacking
现在我们已准备好导入我们的数据并查看它以更好地理解它:
link = 'https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data'
names = ['Class', 'Alcohol', 'Malic acid', 'Ash',
'Alcalinity of ash' ,'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines',
'Proline']
df = pd.read_csv(link, header=None, names=names)
df.sample(5)
运行上面的代码块:

请注意,我使用.sample()代替.head()以避免因假设整个数据集具有前五行的结构而被误导。 幸运的是,这个数据集没有任何缺失值,因此我们可以轻松地使用它来立即测试我们的问题,而无需任何通常需要的数据清理和准备。
在此之后,我们将根据 vecstacks 文档中的示例将结果与输入变量分开并执行 80:20 的train-test-split。
y = df[['Class']]
X = df.iloc[:,1:]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
我们越来越接近有趣的部分。 还记得早些时候的GIF图吗? 现在是时候为我们的堆栈泛化定义第一级模型。 这一步绝对值得写一个系列文章,但为了简单起见,我们将使用三种模型:KNN分类器,随机森林分类器和XGBoost分类器。
models = [
KNeighborsClassifier(n_neighbors=5,
n_jobs=-1),
RandomForestClassifier(random_state=0, n_jobs=-1,
n_estimators=100, max_depth=3),
XGBClassifier(random_state=0, n_jobs=-1, learning_rate=0.1,
n_estimators=100, max_depth=3)
]
这些参数在设置之前未进行调整,因为本文的目的是测试包。 如果要优化性能,则不应只复制和粘贴这些。
从文档中获取下一部分代码,我们基本上使用第一级模型执行GIF的第一部分来进行预测:
S_train, S_test = stacking(models,
X_train, y_train, X_test,
regression=False,
mode='oof_pred_bag',
needs_proba=False,
save_dir=None,
metric=accuracy_score,
n_folds=4,
stratified=True,
shuffle=True,
random_state=0,
verbose=2)
堆栈函数需要输入的几个参数如下:
-
models:我们之前定义的第一级模型
-
X_train,y_train,X_test:我们的数据
-
regression:布尔值,指示是否要将该函数用于回归。 在我们的情况下设置为False,因为这是一个分类问题
-
mode:使用前面描述的交叉验证过程中的折叠
-
needs_proba:布尔值,指示是否需要类标签的概率
-
save_dir:将结果保存到目录Boolean
-
metric:要使用的评估指标(我们在开头导入了accuracy_score)
-
n_folds:用于交叉验证的折叠数
-
stratified:是否使用分层交叉验证
-
shuffle:是否要改组数据
-
random_state:设置随机状态以获得再现性
-
verbose:2这里指的是打印所有信息
这样做,我们得到以下输出:
task: [classification]
n_classes: [3]
metric: [accuracy_score]
mode: [oof_pred_bag]
n_models: [4]
model 0: [KNeighborsClassifier]
fold 0: [0.72972973]
fold 1: [0.61111111]
fold 2: [0.62857143]
fold 3: [0.76470588]
----
MEAN: [0.68352954] + [0.06517070]
FULL: [0.68309859]
model 1: [ExtraTreesClassifier]
fold 0: [0.97297297]
fold 1: [1.00000000]
fold 2: [0.94285714]
fold 3: [1.00000000]
----
MEAN: [0.97895753] + [0.02358296]
FULL: [0.97887324]
model 2: [RandomForestClassifier]
fold 0: [1.00000000]
fold 1: [1.00000000]
fold 2: [0.94285714]
fold 3: [1.00000000]
----
MEAN: [0.98571429] + [0.02474358]
FULL: [0.98591549]
model 3: [XGBClassifier]
fold 0: [1.00000000]
fold 1: [0.97222222]
fold 2: [0.91428571]
fold 3: [0.97058824]
----
MEAN: [0.96427404] + [0.03113768]
FULL: [0.96478873]
再次提到GIF,现在剩下要做的就是将我们选择的第二级模型拟合到我们的预测中,以进行最终预测。 在我们的例子中,我们将使用XGBoost分类器。 此步骤与sklearn中的常规拟合和预测没有显著差异,除了我们使用我们的预测S_train而不是使用X_train训练我们的模型。
model = XGBClassifier(random_state=0, n_jobs=-1, learning_rate=0.1,
n_estimators=100, max_depth=3)
model = model.fit(S_train, y_train)
y_pred = model.predict(S_test)
print('Final prediction score: [%.8f]' % accuracy_score(y_test, y_pred))
Output: Final prediction score: [0.97222222]
结论
使用 vecstacks 的堆栈自动化,我们设法预测正确的葡萄酒品种,准确率约为97.2%! 如您所见,API不会与sklearn API发生冲突,因此在尝试加快堆栈工作流程时可以提供有用的工具。