企业自有数据格式杂乱,MapReduce如何搞定?
本文作为《Hadoop从入门到精通》大型专题第三章的最后一篇文章,主要介绍了SequenceFile和Avro之外的其它数据格式,以及与MapReduce的兼容性,并介绍了企业常用的自定义数据格式或CSV格式如何作为MapReduce作业输入等内容。
3.4 柱状存储
当数据写入I/O设备(比如文件或关系数据库中的表)时,布局该数据的常见方式是基于行,这意味着第一行的所有字段将首先被写入,紧接着是第二行的所有字段,依此类推。这是大多数关系型数据库默认的导出表方式,对于大多数据序列化格式(如XML,JSON和Avro容器文件)也是如此。
列式存储的工作方式则有些不同,其首先按列对数据进行排序,然后按行排列。首先写入所有记录第一个字段的值,然后是第二个字段,依此类推。图3.12显示了两种存储方案在数据布局方式上的差异。

图3.12 行和列存储系统数据布局方式
以柱状形式存储数据有两大主要好处:
-
读取列式数据的系统可以有效提取列的子集,从而减少I/O。基于行的系统通常需要读取整行,即使只需要一列或两列。
-
在编写柱状数据(例如run-length编码和位打包)时可以进行优化,以有效压缩正在写入的数据大小。通用压缩方案适用于压缩列式数据,因为压缩最适用于具有大量重复数据的文件。
因此,在处理有过滤或投影需求的大型数据集时,列式文件格式最有效,这正是OLAP类型用例以及MapReduce中常用的方式。
Hadoop中使用的大多数据格式(如JSON和Avro)都是有序的,这意味着在读取和写入这些文件时无法应用前面提到的优化。想象一下,图3.12中的数据位于Hive表中,你将执行以下查询:
![]()
如果数据是以基于行的格式布局,则必须读取每一行,即使只需要读取价格列。在面向列的表格中,只会读取价格列,这可能会导致处理大型数据集时大幅缩短处理时间。在Hadoop中可以使用许多列式存储选项:
-
RCFile是Hadoop中第一个可用的柱状格式,是Facebook和学术界在2009年合作研发的。RCFile是一个基本的柱状格式,支持单独的列存储、列压缩和读取期间投影,但是没有其他更高级的技术,例如run-length编码(游标编码或行程编码)。 因此,Facebook从RCFile转移到ORC文件。
-
ORC文件由Facebook和Hortonworks创建,以解决RCFile的缺点,与RCFile相比,它的序列化优化可以产生更小的数据大小,使用索引启用谓词下推以优化查询,过滤以跳过与列不匹配的谓词。ORC文件与Hive类型系统完全集成,可以支持嵌套结构。
-
Parquet是Twitter和Cloudera合作开发的,它采用ORC文件用于生成压缩文件。Parquet是一种与语言无关的格式,具有正式的使用规范。
RCFile和ORC文件旨在主要支持Hive,而Parquet独立于所有Hadoop工具,并尝试最大化与Hadoop生态系统兼容。表3.2显示了这些格式如何与各种工具和语言集成。
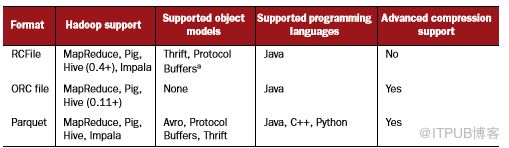
表3.2 Hadoop支持的列式存储格式
Elephant Bird提供了用RCFile使用Thrift和Protocol Buffers的能力。本节,由于考虑到与前一章节提及的Avro等对象模型的兼容性,我将专注于介绍Parquet。
3.4.1 了解对象模型和存储格式
在开始使用之前,我将介绍一些Parquet的概念,这些对于理解Parquet和Avro(以及Thrift和Protocol Buffers)之间的相互作用非常重要:
-
对象模型是数据的内存表示。Parquet公开了一个简单的对象模型,它可以作为示例参考也仅此而已。Avro,Thrift和Protocol Buffers是功能齐全的对象模型。一个例子是Avro Stock类,它由Avro生成,使用Java POJO对模式进行丰富建模。
-
存储格式是数据模型的序列化表示。Parquet是一种以列为导向的序列化数据存储格式。Avro,Thrift和Protocol Buffers都是以行为导向的序列化数据存储格式。
-
Parquet对象模型转换器负责将对象模型转换为Parquet数据类型,反之亦然。 Parquet与许多转换器捆绑在一起,以最大限度提高Parquet的互操作性和采用率。
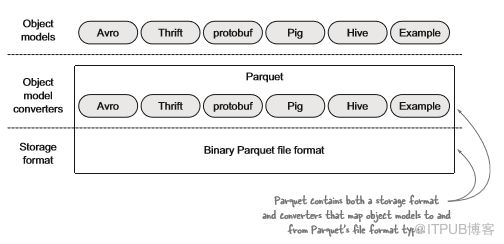
图3.13 Parquet存储格式和对象模型转换器
Parquet的独特之处在于支持常见对象模型(如Avro)的转换器。数据以Parquet二进制形式存储,但是当处理数据时,用户依然可以选择首选对象模型,例如Avro。这种方式的好处在于:用户可继续使用Avro等丰富的对象模型与数据交互,并使用Parquet将数据有效地放置在磁盘上。
存储格式互操作性
存储格式通常不可互操作,当将Avro和Parquet结合在一起时,就相当于结合了Avro对象模型和Parquet存储格式。因此,如果现有的Avro数据位于使用Avro存储格式序列化的HDFS中,则无法使用Parquet存储格式读取,因为这是两种截然不同的数据编码方式。 反之亦然——使用普通的Avro方法(例如MapReduce中的AvroInputFormat)无法读取Parquet,必须使用Parquet输入格式实现和Hive SerDes来处理Parquet数据。
总而言之,如果希望以列形式序列化数据,请选择Parquet。选择Parquet后,需要确定要使用的对象模型。建议选择企业中使用最多的对象模型,如果不清楚则建议使用Avro(前一章节介绍了Avro的优势)。
3.4.2 Parquet 和Hadoop生态系统
Parquet的目标是最大限度支持整个Hadoop生态系统。,目前已支持MapReduce,Hive,Pig,Impala和Spark,我们希望未来能看到起得到其他系统的支持,比如Sqoop。
由于Parquet是标准文件格式,因此任何一种技术都可读取编写好的Parquet文件。 最大限度地提高对Hadoop生态系统的支持对于文件格式的成功至关重要,而Parquet有望成为大数据中无处不在的文件格式。
此外,Parquet没有专注于特定的技术子集——用Parquet官网的话来说,“在生态系统支持方面,我们对玩游戏不感兴趣”(http://parquet.io)。 这意味着该项目的主要目标是最大限度支持可能使用的工具,这一点非常重要,毕竟技术雷达上会不断出现新的工具。
3.4.3 Parquet block和page sizes

图3.14 显示了Parquet文件格式的高级表示,并突出了关键概念。
通过命令行读取Parquet文件
Parquet是一种二进制存储格式,因此使用标准的hadoop fs -cat命令会在命令行产生垃圾。在这种技术中,我们将探索如何使用命令行查看Parquet文件内容,并检查Parquet文件中包含的模式和其他元数据。
问题
希望使用命令行来检查Parquet文件的内容。
解决方案
使用Parquet工具捆绑的实用程序。
讨论
Parquet与工具JAR捆绑,其中包含一些有用的实用程序,可以将Parquet文件中的信息转储到标准输出。
在开始之前,需要创建一个Parquet文件以便测试这些工具。以下示例通过编写Avro记录来创建Parquet文件:

使用的第一个Parquet工具是cat,它将Parquet文件数据简单转储到标准输出:

我们可以在前面的示例中使用Parquet head命令而不是cat来仅发出前五个记录,dump命令允许指定应该转储的列子集,尽管输出不可读。
Parquet有自己的内部数据类型和模式,由转换器映射到外部对象模型,我们可以使用schema选项查看内部Parquet架构:

Parquet允许对象模型使用元数据来存储反序列化所需的信息。例如,Avro使用元数据来存储Avro架构,如下命令输出所示:
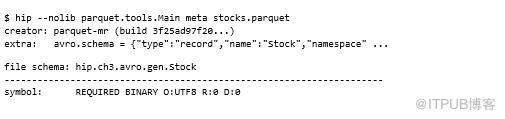
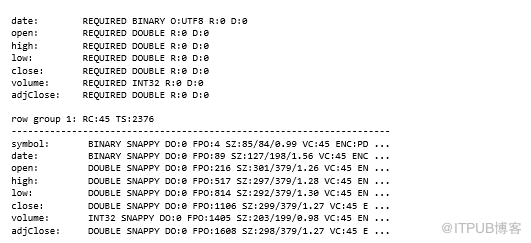
接下来让我们看看如何编写和阅读Parquet文件。
使用Java在Parquet中读取和编写Avro数据
使用新文件格式时,首先要做的事情之一是了解独立的Java应用程序如何读取和写入数据。 此技术显示了如何将Avro数据写入Parquet文件并将其返回。
问题
希望使用Avro对象模型直接从Hadoop之外的Java代码读取和写入Parquet数据。
解决方案
使用AvroParquetWriter和AvroParquetReader类。
讨论
Parquet是Hadoop的柱状存储格式,其支持Avro并允许使用Avro类处理数据,使用Parquet文件格式可有效对数据编码,以便利用数据列式布局。
Parquet是一种存储格式,具有正式的编程语言无关规范,可以直接使用Parquet而不需要其他任何数据格式,例如Avro,但Parquet的核心是简单数据格式,不支持复杂类型,如map或union,这就是Avro发挥作用的地方。Avro支持更丰富的类型以及代码生成和模式演变等功能。因此,将Parquet与Avro等丰富的数据格式结合在一起,可以完美匹配复杂的模式功能以及高效的数据编码。
对于此技术,我们将继续使用Avro Stock架构。首先,让我们看看如何使用这些Stock对象编写Parquet文件。

以下命令通过执行前面的代码生成Parquet文件:

之前的技术展示了如何使用Parquet工具将文件转储到标准输出。但是,如果想用Java读取文件怎么办?

以下命令显示上述代码输出:
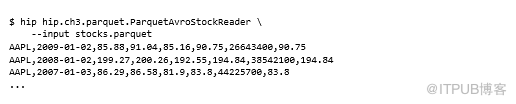
Parquet和MapReduce
此技术检查如何在MapReduce中使用Parquet文件。我将介绍使用Parquet作为数据源以及MapReduce中的数据接收器。
问题
希望使用在MapReduce中序列化为Parquet的Avro数据。
解决方案
使用AvroParquetInputFormat和AvroParquetOutputFormat类。
讨论
Parquet中的Avro子项目带有MapReduce输入和输出格式,可让你使用Parquet作为存储格式读取和写入Avro数据。以下示例是计算每个symbol的平均stock价格:


在Parquet中使用Avro非常简单,并且比使用Avro序列化数据更容易,可以运行以下示例:
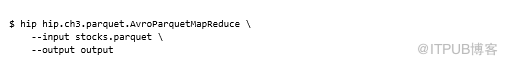
Parquet附带了一些工具来帮助使用Parquet文件,其中一个允许将内容转储到标准输出:
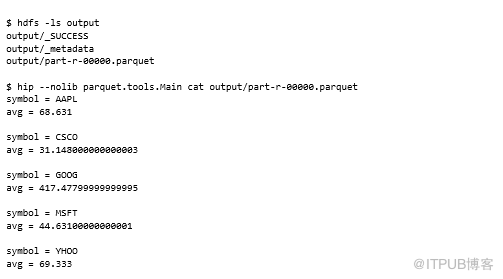
你可能已经注意到输出目录中有一个名为_metadata的附加文件。当Parquet OutputComitter在作业完成时运行,它会读取所有输出文件(包含文件元数据)的页脚并生成此汇总的元数据文件。之后,MapReduce(或Pig / Hive)作业使用此文件将减少作业启动时间。
总结
如果不想使用这种方式,则可以使用一些其他选项来使用Avro数据,比如Avro的GenericData类:
-
如果使用GenericData对象编写Avro数据,那么这就是Avro将其提供给mapper的格式。
-
排除包含Avro生成代码的JAR也会导致GenericData对象被送到mapper。
-
可以通过改变输入模式来使Avro无法加载特定类,从而强制它提供GenericData实例。
以下代码显示了如何执行第三个选项——基本上采用原始模式并复制,但在此过程中,因为提供了一个不同的类名,Avro将无法加载(参见“foobar” 在第一行):
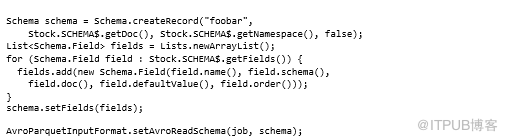
如果想在本地使用Parquet数据怎么办?Parquet附带了一个示例对象模型,允许使用任何Parquet数据,而不管用于写入数据的对象模型,使用Group类来表示记录,并提供一些基本的getter和setter来检索字段。
以下代码再次显示了如何计算stock平均值。输入是Avro / Parquet数据,输出是全新的Parquet架构:


示例对象模型非常基础,目前缺少一些功能——例如,没有双类型的getter,这就是之前的代码使用getValueToString方法访问stock值的原因,但是正在努力提供更好的对象模型,包括POJO适配器。
Parquet,Hive和Impala
在Hive和Impala中使用时,Parquet自成一体。柱状存储因其能够使用下推来优化读取路径而自然适合这些系统,该技术显示了Parquet如何在这些系统中使用。
问题
希望能够在Hive和Impala中使用Parquet数据。
解决方案
使用Hive和Impala对Parquet的内置支持。
讨论
Hive要求数据存在于目录中,因此首先需要创建一个目录并将库存Parquet文件复制到其中:

接下来,创建一个外部Hive表并定义架构。如果不确定模式结构,请查看正在使用的Parquet文件模式信息(使用Parquet工具中的模式命令):
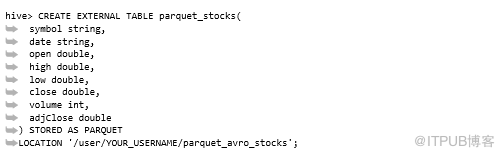
自Hive 0.13就添加了对Parquet作为本机Hive存储的支持(请参阅https://issues.apache.org/jira/browse/HIVE-5783)。如果使用的是较旧版本的Hive,则需要使用ADD JAR命令手动加载所有Parquet JAR并使用Parquet输入和输出格式。
可以运行简单查询以从数据中提取唯一的stock代码:

可以使用相同的语法在Impala中创建表。
用Parquet进行谓词下推和投影
二者需要执行引擎推向存储格式以优化可能的低级别操作。这产生了空间和时间优势,因为不需要获取不需要的列并将其提供给执行引擎。
这对于列式存储尤其有用,因为下推允许存储格式跳过查询时不需要的列,并且列式格式可以非常有效地执行此操作。
问题
希望在Hadoop中使用谓词下推来优化查询
解决方案
将Hive、Pig与Parquet结合使用可提供开箱即用的投影和下推功能。使用MapReduce,则需要在驱动程序代码中采用一些手动步骤来启用下推。
讨论
AvroParquetInputFormat有两种方法可用于谓词下推,在以下示例中,仅投影Stock对象的两个字段,并添加谓词以便仅选择Google stock:



当提供的谓词过滤掉记录时,就会向mapper提供空值。这就是为什么在使用mapper输入之前必须检查null。
如果运行该作业并检查输出,只能找到谷歌stock的平均值,证明该谓词有效:

总结
该技术不包括任何Hive或Pig下推细节,因为二者都可自动执行下推。如果你的Parquet使用的第三方库或工具没有下推工具,可以请求社区帮助。
3.4.4 Parquet限制
使用Parquet时,需要注意以下几点:
-
Parquet在写入文件时需要大量内存,因为会缓冲内存中的写入以优化数据编码和压缩。如果编写Parquet文件时遇到内存问题,可以增加堆大小(建议2GB),或者减少parquet.block.size配置。
-
对Parquet使用重度嵌套的数据结构可能会限制Parquet下推优化。 如果可能,请尝试展平架构。
-
Impala不支持Parquet中的嵌套数据或复杂数据类型(如map,struct或者array),这在Impala 2.x版本中修复。
-
当Parquet文件包含单个行组以及整个文件适合HDFS块时,Impala等工具的效果最佳。 实际上,当你在MapReduce等系统中编写Parquet文件时很难实现这个目标,但是在制作Parquet文件时要记住这一点。
我们已经介绍了使用常见文件格式以及各种数据序列化工具与MapReduce实现紧密兼容。现在是时候看看如何支持企业专有文件格式,甚至是没有MapReduce输入或输出的文件格式。
3.5自定义文件格式
在任何企业,我们通常都会发现过多的自定义或不常见的文件格式,可能有后端服务器以专有格式转储审计文件,或旧代码或使用不常用的格式写入文件的系统。如果想在MapReduce中使用此类数据,则需要编写自己的输入和输出格式类来处理数据。
3.5.1输入和输出格式
在本章开头,我们就了解了MapReduce中输入和输出格式类的功能。输入和输出类需要将数据提供给map函数并写入reduce函数输出。
编写CSV输入和输出格式
想象一下,如果你在CSV文件中有大量数据,并且正在编写多个MapReduce作业,这些作业以CSV格式读写数据。由于CSV是文本,因此可以使用内置的TextInputFormat和TextOutputFormat,并在MapReduce代码中解析CSV。但是,这很快就会变得很累,并导致在所有作业中复制和粘贴相同的解析代码。
问题
希望在MapReduce中使用CSV并以更丰富的格式呈现CSV记录,如果使用的TextInputFormat将提供表示行的字符串。
解决方案
编写适用于CSV的输入和输出格式。
讨论
我们将介绍编写自己的格式类以使用CSV输入和输出所需的步骤。CSV是可以使用的更简单的文件格式之一,这将使您更容易专注于MapReduce细节,而无需过多考虑文件格式。
自定义InputFormat和RecordReader类将解析CSV文件,并以用户友好的格式将数据提供给mapper,其支持非逗号分隔符的自定义字段分隔符。如果不想重新发明轮子,你可以在开源OpenCSV项目(http:// opencsv.sourceforge.net/)中使用CSV解析器,这将处理引用的字段并忽略引用的分隔符。
InputFormat
第一步是定义InputFormat。InputFormat的功能是验证提供给作业的输入集,识别输入拆分,并创建RecordReader类以读取源的输入。以下代码从作业配置中读取分隔符(如果提供)并构造CSVRecordReader:

当压缩时,可以看到返回一个标志以指示它无法拆分。这样做的原因是除了LZOP之外,压缩编解码器不可拆分。但是,可拆分LZOP不能与常规的InputFormat类一起使用,它需要特殊的LZOP InputFormat类。
至此,InputFormat类已完成,我扩展了FileInputFormat类,该类包含计算沿HDFS块边界的输入拆分代码,使不必自己计算输入拆分。FileInputFormat管理所有输入文件和拆分。
RecordReader执行了两个主要功能。首先,它必须根据提供的输入拆分打开输入源,并且可选地在该输入拆分中寻找特定的偏移量。RecordReader的第二个功能是从输入源读取各个记录。
在此示例中,逻辑记录等同于CSV文件的一行,因此将使用MapReduce中的现有LineRecordReader类处理文件。当使用InputSplit初始化RecordReader时,它将打开输入文件,寻找输入拆分的开始,并继续读取字符,直到到达下一条记录的开头,如果是一行,则表示换行符。以下代码显示了LineRecordReader.initialize方法的简化版本:

LineRecordReader以LongWritable / Text形式返回每一行的键/值对。因为需要在Record Reader中提供某些功能,所以需要在类中封装LineRecordReader。RecordReader需要向mapper提供记录的key/value对表示,在这种情况下,key是文件中的字节偏移量,value是包含CSV行的标记化部分数组:
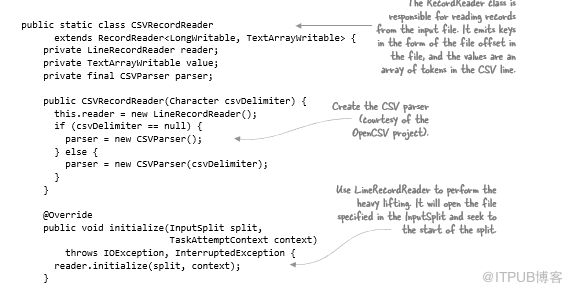
接下来,需要提供读取下一条记录的方法,并获取该记录的key和value:


此时,我已经创建了一个可以使用CSV文件的InputFormat和RecordReader,是时候转到OutputFormat了。
OutputFormat
OutputFormat类遵循类似于InputFormat类的模式,OutputFormat类处理创建输出流逻辑,然后将流写入委托给RecordWriter。
CSVOutputFormat间接扩展了FileOutputFormat类(通过TextOutputFormat),处理与创建输出文件名相关的所有逻辑,创建压缩编解码器的实例(如果启用了压缩),以及输出提交。
这使得OutputFormat类的任务是支持CSV输出文件的自定义字段分隔符,并在需要时创建压缩的OutputStream。它还必须返回CSVRecordWriter,因为它会将CSV行写入输出流:


在以下代码中,RecordWriter将reducer发出的每条记录写入目标输出。我需要reducer输出键以数组形式表示CSV行中的每个标记,并指定reducer输出值必须是NullWritable,这意味着不关心输出的值部分。
我们来看看CSVRecordWriter类,排除仅设置字段分隔符和输出流的构造函数,如下所示。


代码3.6 以CSV格式生成MapReduce输出的RecordWriter
现在,需要在MapReduce作业中应用新的输入和输出格式类。
MapReduce
如果MapReduce作业使用CSV作为输入,将生成以冒号分隔的CSV,而不是逗号。该作业将执行有身份标识的map和reduce功能,这意味着不会在通过MapReduce时更改数据。输入文件将使用制表符分隔,输出文件将以逗号分隔。输入和输出格式类将通过Hadoop配置属性支持自定义分隔符的概念。
MapReduce代码如下:


map和reduce函数除了将输入回显到输出之外没有其他功能,但包含它们以便可以在MapReduce代码中看到如何使用CSV:

如果针对制表符分隔文件运行此示例MapReduce作业,则可以检查mapper输出并查看结果是否符合预期:
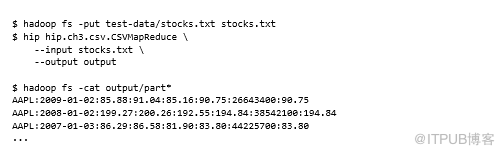
至此,我拥有了一个可以在MapReduce中使用和生成CSV的函数InputFormat和OutputFormat。
Pig
Pig的piggybank库包含一个CSVLoader,可用于将CSV文件加载到元组中,支持CSV记录中的双引号字段,并将每个项目作为字节数组提供。
有一个名为csv-serde的GitHub项目,具备可序列化和反序列化CSV的Hive SerDe。与之前的InputFormat示例一样,它也使用OpenCSV项目来读取和写入CSV。
总结
这种技术演示了如何编写自己的MapReduce格式类来处理基于文本的数据。当然,国内也有不少工具可以满足这一要求。可以说,使用TextInputFormat并在mapper中拆分会更简单。 如果需要多次这样做,可能会遇到复制粘贴反模式,因为用于标记CSV的相同代码可能存在于多个位置。如果代码是在编写代码重用的情况下编写的,那么将受到保护。
MapReduce中的大多数OutputFormats使用FileOutputFormat,使用FileOutputCommitter进行输出提交。当查询FileOutputFormat有关输出文件的位置时,它会将输出所在位置的决定委托给FileOutputCommitter,而FileOutputCommitter又指定输出应该转到作业输出目录下的临时目录(
如果数据接收器是HDFS,则可以使用FileOutputFormat及其提交机制。当使用除文件之外的数据源(例如数据库)时,事情开始变得棘手,这需要包括将数据从Hadoop导出到数据库,这将在之后的章节中讨论。
3.6 总结
本章展示了如何在MapReduce中使用常见的文件格式,如XML和JSON;研究了更复杂的文件格式,如SequenceFile,Avro和Parquet,它们提供了处理大数据的有用功能,例如版本控制,压缩和复杂数据结构;介绍了使用自定义文件格式的过程,以确保其可以在MapReduce中工作。
至此,我们掌握了在MapReduce中使用任何文件格式。第四章将着重介绍存储模式,以帮助你有效地处理数据并优化存储和磁盘或网络I/O。
相关文章:
1、《第一章:Hadoop生态系统及运行MapReduce任务介绍!》链接: http://blog.itpub.net/31077337/viewspace-2213549/
2、《学习Hadoop生态第一步:Yarn基本原理和资源调度解析!》链接: http://blog.itpub.net/31077337/viewspace-2213602/
3、《MapReduce如何作为Yarn应用程序运行?》链接: http://blog.itpub.net/31077337/viewspace-2213676/
4、《Hadoop生态系统各组件与Yarn的兼容性如何?》链接: http://blog.itpub.net/31077337/viewspace-2213960/
5、《MapReduce数据序列化读写概念浅析!》链接: http://blog.itpub.net/31077337/viewspace-2214151/
6、《MapReuce中对大数据处理最合适的数据格式是什么?》链接: http://blog.itpub.net/31077337/viewspace-2214325/
7、《如何在MapReduce中使用SequenceFile数据格式?》链接: http://blog.itpub.net/31077337/viewspace-2214505/
8、《如何在MapReduce中使用Avro数据格式?》链接: http://blog.itpub.net/31077337/viewspace-2214709/
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31077337/viewspace-2214826/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31077337/viewspace-2214826/