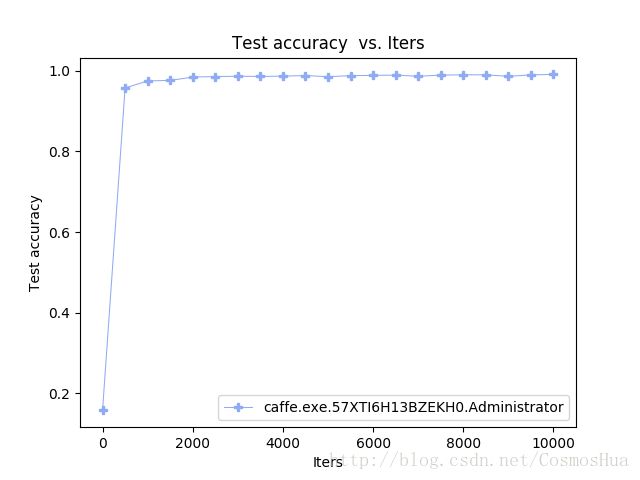
用Caffe自带程序画accuracy曲线
我的系统环境:Win10+VS2013+Anaconda3(Python=3.5)+Caffe
Caffe环境的搭建和配置,这里就不赘述了。懒人办法:可直接去GitHub下载编译好的Caffe程序。
在Caffe的训练过程中,为了更好的观察或优化训练过程,将其图形化是最好的啦。
但自己写代码记录训练过程有些麻烦,可能还要修改Caffe的源码。其实,Caffe已经自带了这样的小工具,供我这样的懒人使用。
1. 准备Caffe画图小工具
在下载好的zip包caffe-windows中,解压出以下3个文件:
caffe-windows\tools\extra\parse_log.py
caffe-windows\tools\extra\extract_seconds.py
caffe-windows\tools\extra\plot_training_log.py.example为方便起见,可将plot_training_log.py.example改名为plot_training_log.py。
由于这3个文件是用python2.7编写的,而我用的是Python3.5,所以直接运行会出现错误。(可参见:Python3.x和Python2.x的区别)
解法1:打开parse_log.py和plot_training_log.py:
(1)查找“print”命令,将所有的“print xxx”全部改为“print(xxx)”。
(2)查找“xrange”命令,将所有的“xrange”全部替换为“range”。
解法2:安装python2.7环境:
(1)在cmd中输入:conda create -n py2 python=2.7。
(2)为环境安装必需的包:conda install matplotlib。
(3)测试:先激活py2环境:在cmd中输入activate py2,然后输入plot_training_log.py,看是否报错。
2. 输出Caffe训练过程到日志
将Caffe的训练过程输出到文件中,可在Caffe参数中指定log的输出目录(-log_dir=./log,其中.表示”当前文件夹”)。例如:
caffe.exe train -solver=./lenet_solver.prototxt -log_dir=./log训练完后,会在F:\Caffe目录下找到一个长名文件,例如:“caffe.exe.HUA.Administrator.log.INFO.20170601-154746.10244”。
需要将其改为后缀为log文件(plot_training_log.py的要求):“caffe.exe.HUA.Administrator.log”。
Note:用Notepad或记事本打开,就会发现里面其实就是cmd窗口中显示的那堆文字。
3. 解析log日志
将解压出的那3个文件拷贝到log日志所在的目录中,先执行parse.py解析log文件。例如:
python parse_log.py caffe.exe.HUA.Administrator.log ./解析的结果是2个文件(输出到当前文件,可用记事本打开查看):
caffe.exe.HUA.Administrator.log.test和caffe.exe.HUA.Administrator.log.train。
Note:这两个文件就是用plot_training_log.py画图时要用到的数据文件。
1.因生成的xxx.train和xxx.test的第1行为说明字符,需修改以下脚本。
2.分隔符不是空格,而是,,故将line.split()改为line.split(',')。
4. 绘制曲线
4.1 修改python源代码:
#源代码:
def load_data(data_file, field_idx0, field_idx1):
data = [[], []]
with open(data_file, 'r') as f:
for line in f:
line = line.strip()
if line[0] != '#':
fields = line.split()
data[0].append(float(fields[field_idx0].strip()))
data[1].append(float(fields[field_idx1].strip()))
return data
#修改方案1:
def load_data(data_file, field_idx0, field_idx1):
data = [[], []]
with open(data_file, 'r') as f:
lines = [line.strip() for line in f] #changed
for line in lines[1:]: #changed
if len(line)>0 and line[0] != '#': #changed
fields = line.split(',') #changed
data[0].append(float(fields[field_idx0].strip()))
data[1].append(float(fields[field_idx1].strip()))
return data
#修改方案2:
def load_data(data_file, field_idx0, field_idx1):
data = [[], []]
f = open(data_file,'r') #changed
lines = f.readlines() #changed
for i in range(1, len(lines)): #changed
line = lines[i].strip() #changed
if len(line)>0 and line[0] != '#': #changed
fields = line.split(',') #changed
data[0].append(float(fields[field_idx0].strip()))
data[1].append(float(fields[field_idx1].strip()))
fr.close() #changed
return data#源代码:for Python2.7
def random_marker():
markers = mks.MarkerStyle.markers
num = len(markers.keys())
idx = random.randint(0, num - 1)
return markers.keys()[idx]
#修改方案:for python3.5
def random_marker():
markers = mks.MarkerStyle.markers
num = len(markers.keys())
idx = random.randint(0, num - 1)
return list(markers.keys())[idx] #changedOptional:在windows环境下,可以将
#os.system('%s %s' % (get_log_parsing_script(), path_to_log))这行注释掉。
4.2 开始绘制曲线:
在cmd中输入:
python plot_training_log.py 0 acc.png caffe.exe.HUA.Administrator.log即可生成训练过程中的“Test accuracy vs. Iters”曲线。其中,0代表曲线类型,acc.png输出的图片名称。
Caffe中可以绘制多种曲线类型,具体参数如下:
Notes:
1. Supporting multiple logs.
2. Log file name must end with the lower-cased ".log".
Supported chart types:
0: Test accuracy vs. Iters
1: Test accuracy vs. Seconds
2: Test loss vs. Iters
3: Test loss vs. Seconds
4: Train learning rate vs. Iters
5: Train learning rate vs. Seconds
6: Train loss vs. Iters
7: Train loss vs. Seconds 
仔细观察,会发现上图其实有误:因accuracy随着迭代次数下降。
4.3 修正错误字段:
要修正以上错误,只需要调整脚本中field的对应项即可。注意:只是修改数字和增加learning rate,并未修改key值!
def create_field_index():
train_key = 'Train'
test_key = 'Test'
field_index = {train_key:{'Iters':0, 'Seconds':1, train_key + ' learning rate':2, train_key + ' loss':3}, #changed
test_key:{'Iters':0, 'Seconds':1, 'learning rate':2, test_key + ' accuracy':3, test_key + ' loss':4}} #changed
fields = set()
for data_file_type in field_index.keys():
fields = fields.union(set(field_index[data_file_type].keys()))
fields = list(fields)
fields.sort()
return field_index, fields