搞懂JavaScript引擎运行原理
译者:前端小智 原文:https://codeburst.io/js-essentials-the-javascript-engine-302ff38e8465
为了保证可读性,本文采用意译而非直译。
一些名词
JS引擎 — 一个读取代码并运行的引擎,没有单一的“JS引擎”;,每个浏览器都有自己的引擎,如谷歌有V。
作用域 — 可以从中访问变量的“区域”。
词法作用域— 在词法阶段的作用域,换句话说,词法作用域是由你在写代码时将变量和块作用域写在哪里来决定的,因此当词法分析器处理代码时会保持作用域不变。
块作用域 — 由花括号{}创建的范围
作用域链 — 函数可以上升到它的外部环境(词法上)来搜索一个变量,它可以一直向上查找,直到它到达全局作用域。
同步 — 一次执行一件事, “同步”引擎一次只执行一行,JavaScript是同步的。
异步 — 同时做多个事,JS通过浏览器API模拟异步行为
事件循环(Event Loop) - 浏览器API完成函数调用的过程,将回调函数推送到回调队列(callback queue),然后当堆栈为空时,它将回调函数推送到调用堆栈。
堆栈 —一种数据结构,只能将元素推入并弹出顶部元素。想想堆叠一个字形的塔楼; 你不能删除中间块,后进先出。
堆 — 变量存储在内存中。
调用堆栈 — 函数调用的队列,它实现了堆栈数据类型,这意味着一次可以运行一个函数。调用函数将其推入堆栈并从函数返回将其弹出堆栈。
执行上下文 — 当函数放入到调用堆栈时由JS创建的环境。
闭包 — 当在另一个函数内创建一个函数时,它“记住”它在以后调用时创建的环境。
垃圾收集 — 当内存中的变量被自动删除时,因为它不再使用,引擎要处理掉它。
变量的提升— 当变量内存没有赋值时会被提升到全局的顶部并设置为 undefined。
this —由JavaScript为每个新的执行上下文自动创建的变量/关键字。
调用堆栈(Call Stack)
看看下面的代码:
var myOtherVar = 10
function a() {
console.log('myVar', myVar)
b()
}
function b() {
console.log('myOtherVar', myOtherVar)
c()
}
function c() {
console.log('Hello world!')
}
a()
var myVar = 5有几个点需要注意:
变量声明的位置(一个在上,一个在下)
函数
a调用下面定义的函数b, 函数b调用函数c
当它被执行时你期望发生什么?是否发生错误,因为 b在 a之后声明或者一切正常?console.log 打印的变量又是怎么样?
以下是打印结果:
"myVar" undefined
"myOtherVar" 10
"Hello world!"来分解一下上述的执行步骤。
1. 变量和函数声明(创建阶段)
第一步是在内存中为所有变量和函数分配空间。但请注意,除了 undefined之外,尚未为变量分配值。因此, myVar在被打印时的值是 undefined,因为JS引擎从顶部开始逐行执行代码。
函数与变量不一样,函数可以一次声明和初始化,这意味着它们可以在任何地方被调用。
所以以上代码看起来像这样子:
var myOtherVar = undefined
var myVar = undefined
function a() {...}
function b() {...}
function c() {...}这些都存在于JS创建的全局上下文中,因为它位于全局空间中。
在全局上下文中,JS还添加了:
全局对象(浏览器中是
window对象,NodeJs 中是global对象)this 指向全局对象
2. 执行
接下来,JS 引擎会逐行执行代码。
myOtherVar=10在全局上下文中, myOtherVar被赋值为 10
已经创建了所有函数,下一步是执行函数 a()
每次调用函数时,都会为该函数创建一个新的上下文(重复步骤1),并将其放入调用堆栈。
function a() {
console.log('myVar', myVar)
b()
}如下步骤:
创建新的函数上下文
a函数里面没有声明变量和函数函数内部创建了
this并指向全局对象(window)接着引用了外部变量
myVar,myVar属于全局作用域的。接着调用函数
b,函数b的过程跟a一样,这里不做分析。
下面调用堆栈的执行示意图:

创建全局上下文,全局变量和函数。
每个函数的调用,会创建一个上下文,外部环境的引用及
this。函数执行结束后会从堆栈中弹出,并且它的执行上下文被垃圾收集回收(闭包除外)。
当调用堆栈为空时,它将从事件队列中获取事件。
作用域及作用域链
在前面的示例中,所有内容都是全局作用域的,这意味着我们可以从代码中的任何位置访问它。现在,介绍下私有作用域以及如何定义作用域。
函数/词法作用域
考虑如下代码:
function a() {
var myOtherVar = 'inside A'
b()
}
function b() {
var myVar = 'inside B'
console.log('myOtherVar:', myOtherVar)
function c() {
console.log('myVar:', myVar)
}
c()
}
var myOtherVar = 'global otherVar'
var myVar = 'global myVar'
a()需要注意以下几点:
全局作用域和函数内部都声明了变量
函数
c现在在函数b中声明
打印结果如下:
myOtherVar: "global otherVar"
myVar: "inside B"执行步骤:
全局创建和声明 - 创建内存中的所有函数和变量以及全局对象和
this执行 - 它逐行读取代码,给变量赋值,并执行函数a
函数a创建一个新的上下文并被放入堆栈,在上下文中创建变量
myOtherVar,然后调用函数b函数b 也会创建一个新的上下文,同样也被放入堆栈中
函数b的上下文中创建了
myVar变量,并声明函数c
上面提到每个新上下文会创建的外部引用,外部引用取决于函数在代码中声明的位置。
函数b试图打印
myOtherVar,但这个变量并不存在于函数b中,函数b 就会使用它的外部引用上作用域链向上找。由于函数b是全局声明的,而不是在函数a内部声明的,所以它使用全局变量myOtherVar。函数c执行步骤一样。由于函数c本身没有变量
myVar,所以它它通过作用域链向上找,也就是函数b,因为myVar是函数b内部声明过。
下面是执行示意图:
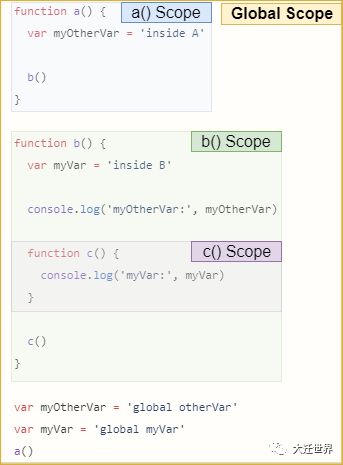
请记住,外部引用是单向的,它不是双向关系。例如,函数b不能直接跳到函数c的上下文中并从那里获取变量。
最好将它看作一个只能在一个方向上运行的链(范围链)。
a -> global
c -> b -> global
在上面的图中,你可能注意到,函数是创建新作用域的一种方式。(除了全局作用域)然而,还有另一种方法可以创建新的作用域,就是块作用域。
块作用域
下面代码中,我们有两个变量和两个循环,在循环重新声明相同的变量,会打印什么(反正我是做错了)?
function loopScope () {
var i = 50
var j = 99
for (var i = 0; i < 10; i++) {}
console.log('i =', i)
for (let j = 0; j < 10; j++) {}
console.log('j =', j)
}
loopScope()打印结果:
i = 10
j = 99第一个循环覆盖了 vari,对于不知情的开发人员来说,这可能会导致bug。
第二个循环,每次迭代创建了自己作用域和变量。这是因为它使用 let关键字,它与 var相同,只是 let有自己的块作用域。另一个关键字是 const,它与 let相同,但 const常量且无法更改(指内存地址)。
块作用域由大括号 {} 创建的作用域
再看一个例子:
function blockScope () {
let a = 5
{
const blockedVar = 'blocked'
var b = 11
a = 9000
}
console.log('a =', a)
console.log('b =', b)
console.log('blockedVar =', blockedVar)
}
blockScope()打印结果:
a = 9000
b = 11
ReferenceError: blockedVar is not defineda是块作用域,但它在函数中,而不是嵌套的,本例中使用var是一样的对于块作用域的变量,它的行为类似于函数,注意
varb可以在外部访问,但是constblockedVar不能。在块内部,从作用域链向上找到
a并将leta更改为9000。
使用块作用域可以使代码更清晰,更安全,应该尽可能地使用它。
事件循环(Event Loop)
接下来看看事件循环。这是回调,事件和浏览器API工作的地方
我们没有过多讨论的事情是堆,也叫全局内存。它是变量存储的地方。由于了解JS引擎是如何实现其数据存储的实际用途并不多,所以我们不在这里讨论它。
来个异步代码:
function logMessage2 () {
console.log('Message 2')
}
console.log('Message 1')
setTimeout(logMessage2, 1000)
console.log('Message 3')上述代码主要是将一些 message 打印到控制台。利用 setTimeout函数来延迟一条消息。我们知道js是同步,来看看输出结果
Message 1
Message 3
Message 2打印 Message 1
调用 setTimeout
打印 Message 3
打印 Message 2
它记录消息3
稍后,它会记录消息2
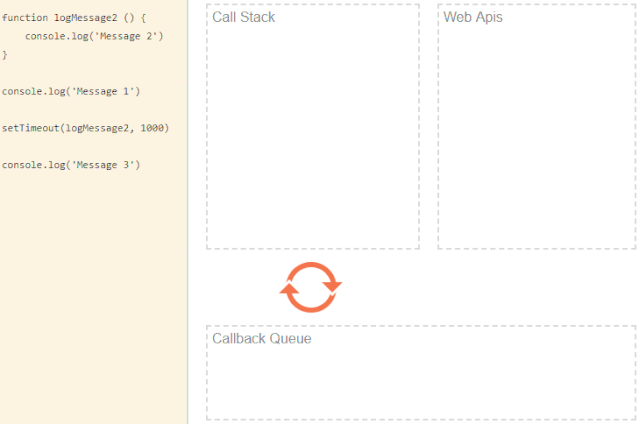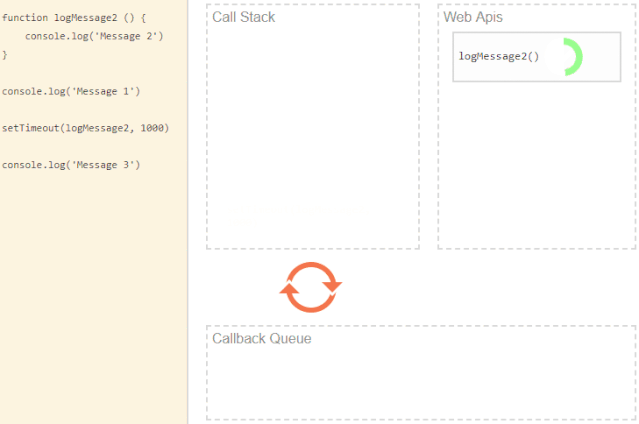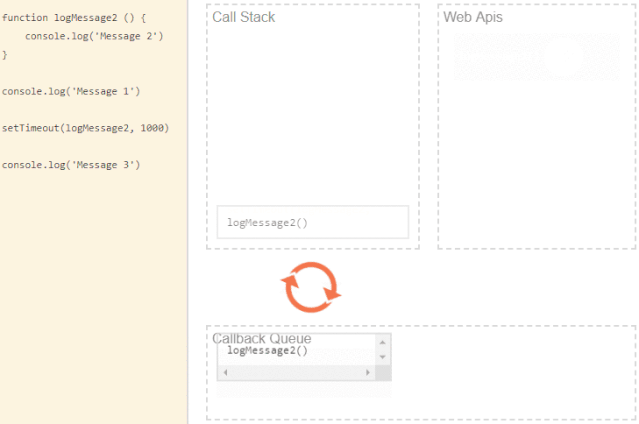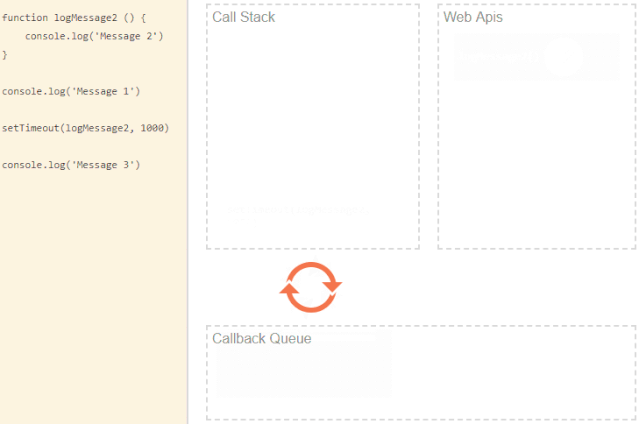
setTimeout是一个 API,和大多数浏览器 API一样,当它被调用时,它会向浏览器发送一些数据和回调。我们这边是延迟一秒打印 Message 2。
调用完 setTimeout 后,我们的代码继续运行,没有暂停,打印 Message 3 并执行一些必须先执行的操作。
浏览器等待一秒钟,它就会将数据传递给我们的回调函数并将其添加到事件/回调队列中( event/callback queue)。然后停留在队列中,只有当调用堆栈(call stack)为空时才会被压入堆栈。
代码示例
要熟悉JS引擎,最好的方法就是使用它,再来些有意义的例子。
简单的闭包
这个例子中 有一个返回函数的函数,并在返回的函数中使用外部的变量, 这称为闭包。
function exponent (x) {
return function (y) {
//和math.pow() 或者x的y次方是一样的
return y ** x
}
}
const square = exponent(2)
console.log(square(2), square(3)) // 4, 9
console.log(exponent(3)(2)) // 8块代码
我们使用无限循环将将调用堆栈塞满,会发生什么,回调队列被会阻塞,因为只能在调用堆栈为空时添加回调队列。
function blockingCode() {
const startTime = new Date().getSeconds()
// 延迟函数250毫秒
setTimeout(function() {
const calledAt = new Date().getSeconds()
const diff = calledAt - startTime
// 打印调用此函数所需的时间
console.log(`Callback called after: ${diff} seconds`)
}, 250)
// 用循环阻塞堆栈2秒钟
while(true) {
const currentTime = new Date().getSeconds()
// 2 秒后退出
if(currentTime - startTime >= 2) break
}
}
blockingCode() // 'Callback called after: 2 seconds'我们试图在 250毫秒之后调用一个函数,但因为我们的循环阻塞了堆栈所花了 两秒钟,所以回调函数实际是两秒后才会执行,这是JavaScript应用程序中的常见错误。
setTimeout不能保证在设置的时间之后调用函数。相反,更好的描述是,在至少经过这段时间之后调用这个函数。
延迟函数
当 setTimeout 的设置为0,情况是怎么样?
function defer () {
setTimeout(() => console.log('timeout with 0 delay!'), 0)
console.log('after timeout')
console.log('last log')
}
defer()你可能期望它被立即调用,但是,事实并非如此。
执行结果:
after timeout
last log
timeout with 0 delay!它会立即被推到回调队列,但它仍然会等待调用堆栈为空才会执行。
用闭包来缓存
Memoization是缓存函数调用结果的过程。
例如,有一个添加两个数字的函数 add。调用 add(1,2)返回 3,当再次使用相同的参数 add(1,2)调用它,这次不是重新计算,而是记住1 +2是3的结果并直接返回对应的结果。Memoization可以提高代码运行速度,是一个很好的工具。
我们可以使用闭包实现一个简单的memoize函数。
// 缓存函数,接收一个函数
const memoize = (func) => {
// 缓存对象
// keys 是 arguments, values are results
const cache = {}
// 返回一个新的函数
// it remembers the cache object & func (closure)
// ...args is any number of arguments
return (...args) => {
// 将参数转换为字符串,以便我们可以存储它
const argStr = JSON.stringify(args)
// 如果已经存,则打印
console.log('cache', cache, !!cache[argStr])
cache[argStr] = cache[argStr] || func(...args)
return cache[argStr]
}
}
const add = memoize((a, b) => a + b)
console.log('first add call: ', add(1, 2))
console.log('second add call', add(1, 2))执行结果:
cache {} false
first add call: 3
cache { '[1,2]': 3 } true
second add call 3第一次 add 方法,缓存对象是空的,它调用我们的传入函数来获取值 3.然后它将 args/value键值对存储在缓存对象中。
在第二次调用中,缓存中已经有了,查找到并返回值。
对于 add函数来说,有无缓存看起来无关紧要,甚至效率更低,但是对于一些复杂的计算,它可以节省很多时间。这个示例并不是一个完美的缓存示例,而是闭包的实际应用。