样本数据相似性距离度量算法
1. 闵可夫斯基距离
2. 欧氏距离
3. 标准化欧氏距离
4. 曼哈顿距离
5. 切比雪夫距离
6. 马氏距离
7. 夹角相似距离
8. 汉明距离
9. 杰卡德距离 & 杰卡德相似系数
10. 相关系数 & 相关距离
11. 信息熵
12.皮尔逊相关系数
13.编辑距离
14.DTW 距离
15.KL 散度
其他方法:
卡方检验 Chi-Square
衡量 categorical attributes 相关性的 mutualinformation
Spearman's rank coefficient
Earth Mover's Distance
SimRank 迭代算法等。
1. 闵可夫斯基距离(Minkowski Distance)
闵氏距离不是一种距离,而是一组距离的定义。(1) 闵氏距离的定义
两个n维变量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:
其中p是一个变参数。
当p=1时,就是曼哈顿距离
当p=2时,就是欧氏距离
当p→∞时,就是切比雪夫距离
根据变参数的不同,闵氏距离可以表示一类的距离。
(2)闵氏距离的缺点
闵氏距离,包括曼哈顿距离、欧氏距离和切比雪夫距离都存在明显的缺点。
举个例子:二维样本(身高,体重),其中身高范围是150~190,体重范围是50~60,有三个样本:a(180,50),b(190,50),c(180,60)。那么a与b之间的闵氏距离(无论是曼哈顿距离、欧氏距离或切比雪夫距离)等于a与c之间的闵氏距离,但是身高的10cm真的等价于体重的10kg么?因此用闵氏距离来衡量这些样本间的相似度很有问题。
简单说来,闵氏距离的缺点主要有两个:(1)将各个分量的量纲(scale),也就是“单位”当作相同的看待了。(2)没有考虑各个分量的分布(期望,方差等)可能是不同的。
(3)Matlab计算闵氏距离
例子:计算向量(0,0)、(1,0)、(0,2)两两间的闵氏距离(以变参数为2的欧氏距离为例)
X = [0 0 ; 1 0 ; 0 2]
D = pdist(X,'minkowski',2)
结果:
D = 1.0000 2.0000 2.2361
2. 欧氏距离(EuclideanDistance)
欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式。
(1)二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
(2)三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:
(3)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:
也可以用表示成向量运算的形式:
(4)Matlab计算欧氏距离
Matlab计算距离主要使用pdist函数。若X是一个M×N的矩阵,则pdist(X)将X矩阵M行的每一行作为一个N维向量,然后计算这M个向量两两间的距离。
例子:计算向量(0,0)、(1,0)、(0,2)两两间的欧式距离
X = [0 0 ; 1 0 ; 0 2]
D = pdist(X,'euclidean')
结果:
D = 1.0000 2.0000 2.2361
3. 标准化欧氏距离 (Standardized Euclidean distance )
(1)标准欧氏距离的定义标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路:既然数据各维分量的分布不一样,好吧!那我先将各个分量都“标准化”到均值、方差相等吧。均值和方差标准化到多少呢?这里先复习点统计学知识吧,假设样本集X的均值(mean)为m,标准差(standard deviation)为s,那么X的“标准化变量”表示为:
而且标准化变量的数学期望为0,方差为1。因此样本集的标准化过程(standardization)用公式描述就是:
标准化后的值 = ( 标准化前的值 -分量的均值 ) /分量的标准差
经过简单的推导就可以得到两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的标准化欧氏距离的公式:
如果将方差的倒数看成是一个权重,这个公式可以看成是一种加权欧氏距离(Weighted Euclidean distance)。
(2)Matlab计算标准化欧氏距离
例子:计算向量(0,0)、(1,0)、(0,2)两两间的标准化欧氏距离 (假设两个分量的标准差分别为0.5和1)
X = [0 0 ; 1 0 ; 0 2]
D = pdist(X, 'seuclidean',[0.5,1])
结果:
D = 2.0000 2.0000 2.8284
4. 曼哈顿距离(Manhattan Distance)
从名字就可以猜出这种距离的计算方法了。想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除非你能穿越大楼。实际驾驶距离就是这个“曼哈顿距离”。而这也是曼哈顿距离名称的来源,曼哈顿距离也称为城市街区距离(City Block distance)。(1)二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离
(2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的曼哈顿距离
(3) Matlab计算曼哈顿距离
例子:计算向量(0,0)、(1,0)、(0,2)两两间的曼哈顿距离
X = [0 0 ; 1 0 ; 0 2]
D = pdist(X, 'cityblock')
结果:
D = 1 2 3
5. 切比雪夫距离 (Chebyshev Distance )
国际象棋玩过么?国王走一步能够移动到相邻的8个方格中的任意一个。那么国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?自己走走试试。你会发现最少步数总是max( | x2-x1 | , | y2-y1 | ) 步。有一种类似的一种距离度量方法叫切比雪夫距离。(1)二维平面两点a(x1,y1)与b(x2,y2)间的切比雪夫距离
(2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的切比雪夫距离
这个公式的另一种等价形式是
看不出两个公式是等价的?提示一下:试试用放缩法和夹逼法则来证明。
(3)Matlab计算切比雪夫距离
例子:计算向量(0,0)、(1,0)、(0,2)两两间的切比雪夫距离
X = [0 0 ; 1 0 ; 0 2]
D = pdist(X, 'chebychev')
结果:
D = 1 2 2
6. 马氏距离(Mahalanobis Distance)
(1)马氏距离定义有M个样本向量X1~Xm,协方差矩阵记为S,均值记为向量μ,则其中样本向量X到u的马氏距离表示为:
而其中向量Xi与Xj之间的马氏距离定义为:
若协方差矩阵是单位矩阵(各个样本向量之间独立同分布),则公式就成了:
也就是欧氏距离了。
若协方差矩阵是对角矩阵,公式变成了标准化欧氏距离。
(2)马氏距离的优缺点:量纲无关,排除变量之间的相关性的干扰。
(3) Matlab计算(1 2),( 1 3),( 2 2),( 3 1)两两之间的马氏距离
X = [1 2; 1 3; 2 2; 3 1]
Y = pdist(X,'mahalanobis')
结果:
Y = 2.3452 2.0000 2.3452 1.2247 2.4495 1.2247
7. 夹角余弦(Cosine)
有没有搞错,又不是学几何,怎么扯到夹角余弦了?各位看官稍安勿躁。几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异。(1)在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:
(2) 两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦
类似的,对于两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n),可以使用类似于夹角余弦的概念来衡量它们间的相似程度。
即:
夹角余弦取值范围为[-1,1]。夹角余弦越大表示两个向量的夹角越小,夹角余弦越小表示两向量的夹角越大。当两个向量的方向重合时夹角余弦取最大值1,当两个向量的方向完全相反夹角余弦取最小值-1。
夹角余弦的具体应用可以参阅参考文献[1]。
(3)Matlab计算夹角余弦
例子:计算(1,0)、( 1,1.732)、( -1,0)两两间的夹角余弦
X = [1 0 ; 1 1.732 ; -1 0]
D = 1- pdist(X, 'cosine') %Matlab中的pdist(X, 'cosine')得到的是1减夹角余弦的值
结果:
D = 0.5000 -1.0000 -0.5000
8. 汉明距离(Hamming distance)
(1)汉明距离的定义两个等长字符串s1与s2之间的汉明距离定义为将其中一个变为另外一个所需要作的最小替换次数。例如字符串“1111”与“1001”之间的汉明距离为2。
应用:信息编码(为了增强容错性,应使得编码间的最小汉明距离尽可能大)。
(2)Matlab计算汉明距离
Matlab中2个向量之间的汉明距离的定义为2个向量不同的分量所占的百分比。
例子:计算向量(0,0)、(1,0)、(0,2)两两间的汉明距离
X = [0 0 ; 1 0 ; 0 2];
D = PDIST(X, 'hamming')
结果:
D = 0.5000 0.5000 1.0000
9. 杰卡德相似系数(Jaccard similarity coefficient)
(1) 杰卡德相似系数两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。
杰卡德相似系数是衡量两个集合的相似度一种指标。
(2) 杰卡德距离
与杰卡德相似系数相反的概念是杰卡德距离(Jaccard distance)。杰卡德距离可用如下公式表示:
杰卡德距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。
(3) 杰卡德相似系数与杰卡德距离的应用
可将杰卡德相似系数用在衡量样本的相似度上。
样本A与样本B是两个n维向量,而且所有维度的取值都是0或1。例如:A(0111)和B(1011)。我们将样本看成是一个集合,1表示集合包含该元素,0表示集合不包含该元素。
p :样本A与B都是1的维度的个数
q :样本A是1,样本B是0的维度的个数
r :样本A是0,样本B是1的维度的个数
s :样本A与B都是0的维度的个数
那么样本A与B的杰卡德相似系数可以表示为:
这里p+q+r可理解为A与B的并集的元素个数,而p是A与B的交集的元素个数。
而样本A与B的杰卡德距离表示为:
(4)Matlab 计算杰卡德距离
Matlab的pdist函数定义的杰卡德距离跟我这里的定义有一些差别,Matlab中将其定义为不同的维度的个数占“非全零维度”的比例。
例子:计算(1,1,0)、(1,-1,0)、(-1,1,0)两两之间的杰卡德距离
X = [1 1 0; 1 -1 0; -1 1 0]
D = pdist( X , 'jaccard')
结果
D = 0.5000 0.5000 1.0000
10. 相关系数 ( Correlation coefficient )与相关距离(Correlationdistance)
(1) 相关系数的定义相关系数是衡量随机变量X与Y相关程度的一种方法,相关系数的取值范围是[-1,1]。相关系数的绝对值越大,则表明X与Y相关度越高。当X与Y线性相关时,相关系数取值为1(正线性相关)或-1(负线性相关)。
(2)相关距离的定义
(3)Matlab计算(1, 2 ,3 ,4 )与( 3 ,8 ,7 ,6)之间的相关系数与相关距离
X = [1 2 3 4 ; 3 8 7 6]
C = corrcoef( X' ) %将返回相关系数矩阵
D = pdist( X , 'correlation')
结果:
C =
1.0000 0.4781
0.4781 1.0000
D =
0.5219
其中0.4781就是相关系数,0.5219是相关距离。
11. 信息熵(Information Entropy)
信息熵并不属于一种相似性度量。那为什么放在这篇文章中呢?信息熵是衡量分布的混乱程度或分散程度的一种度量。分布越分散(或者说分布越平均),信息熵就越大。分布越有序(或者说分布越集中),信息熵就越小。
计算给定的样本集X的信息熵的公式:
参数的含义:
n:样本集X的分类数
pi:X中第i类元素出现的概率
信息熵越大表明样本集S分类越分散,信息熵越小则表明样本集X分类越集中。。当S中n个分类出现的概率一样大时(都是1/n),信息熵取最大值log2(n)。当X只有一个分类时,信息熵取最小值0
12 序列之间的距离
汉明距离可以度量两个长度相同的字符串之间的相似度,如果要比较两个不同长度的字符串,不仅要进行替换,而且要进行插入与删除的运算,在这种场合下,通常使用更加复杂的编辑距离(Edit distance, Levenshtein distance)等算法。编辑距离是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。编辑距离求的是最少编辑次数,这是一个动态规划的问题,有兴趣的同学可以自己研究研究。
时间序列是序列之间距离的另外一个例子。DTW 距离(Dynamic Time Warp)是序列信号在时间或者速度上不匹配的时候一种衡量相似度的方法。神马意思?举个例子,两份原本一样声音样本A、B都说了“你好”,A在时间上发生了扭曲,“你”这个音延长了几秒。最后A:“你~~~好”,B:“你好”。DTW正是这样一种可以用来匹配A、B之间的最短距离的算法。
DTW 距离在保持信号先后顺序的限制下对时间信号进行“膨胀”或者“收缩”,找到最优的匹配,与编辑距离相似,这其实也是一个动态规划的问题:
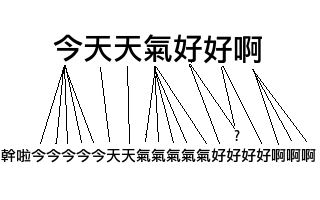
#!/usr/bin/python2 # -*- coding:UTF-8 -*- # code related at: http://blog.mckelv.in/articles/1453.html import sys distance = lambda a,b : 0 if a==b else 1 def dtw(sa,sb): ''' >>>dtw(u"干啦今今今今今天天气气气气气好好好好啊啊啊", u"今天天气好好啊") 2 ''' MAX_COST = 1<<32 #初始化一个len(sb) 行(i),len(sa)列(j)的二维矩阵 len_sa = len(sa) len_sb = len(sb) # BUG:这样是错误的(浅拷贝): dtw_array = [[MAX_COST]*len(sa)]*len(sb) dtw_array = [[MAX_COST for i in range(len_sa)] for j in range(len_sb)] dtw_array[0][0] = distance(sa[0],sb[0]) for i in xrange(0, len_sb): for j in xrange(0, len_sa): if i+j==0: continue nb = [] if i > 0: nb.append(dtw_array[i-1][j]) if j > 0: nb.append(dtw_array[i][j-1]) if i > 0 and j > 0: nb.append(dtw_array[i-1][j-1]) min_route = min(nb) cost = distance(sa[j],sb[i]) dtw_array[i][j] = cost + min_route return dtw_array[len_sb-1][len_sa-1] def main(argv): s1 = u'干啦今今今今今天天气气气气气好好好好啊啊啊' s2 = u'今天天气好好啊' d = dtw(s1, s2) print d return 0 if __name__ == '__main__': sys.exit(main(sys.argv))
13概率分布之间的距离
前面我们谈论的都是两个数值点之间的距离,实际上两个概率分布之间的距离是可以测量的。在统计学里面经常需要测量两组样本分布之间的距离,进而判断出它们是否出自同一个 population,常见的方法有卡方检验(Chi-Square)和 KL 散度( KL-Divergence),下面说一说 KL 散度吧。
先从信息熵说起,假设一篇文章的标题叫做“黑洞到底吃什么”,包含词语分别是 {黑洞, 到底, 吃什么}, 我们现在要根据一个词语推测这篇文章的类别。哪个词语给予我们的信息最多?很容易就知道是“黑洞”,因为“黑洞”这个词语在所有的文档中出现的概率太低啦,一旦出现,就表明这篇文章很可能是在讲科普知识。而其他两个词语“到底”和“吃什么”出现的概率很高,给予我们的信息反而越少。如何用一个函数 h(x) 表示词语给予的信息量呢?第一,肯定是与 p(x) 相关,并且是负相关。第二,假设 x 和 y 是独立的(黑洞和宇宙不相互独立,谈到黑洞必然会说宇宙),即 p(x,y) = p(x)p(y), 那么获得的信息也是叠加的,即 h(x, y) = h(x) + h(y)。满足这两个条件的函数肯定是负对数形式 ![]()
对假设一个发送者要将随机变量 X 产生的一长串随机值传送给接收者,接受者获得的平均信息量就是求它的数学期望:
![]()
![]()
这就是熵的概念。另外一个重要特点是,熵的大小与字符平均最短编码长度是一样的(shannon)。设有一个未知的分布 p(x), 而 q(x) 是我们所获得的一个对 p(x) 的近似,按照 q(x) 对该随机变量的各个值进行编码,平均长度比按照真实分布的 p(x) 进行编码要额外长一些,多出来的长度这就是 KL 散度(之所以不说距离,是因为不满足对称性和三角形法则),即:
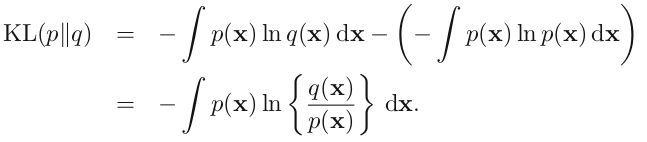
KL 散度又叫相对熵(relativeentropy)。了解机器学习的童鞋应该都知道,在 Softmax 回归(或者 Logistic 回归),最后的输出节点上的值表示这个样本分到该类的概率,这就是一个概率分布。对于一个带有标签的样本,我们期望的概率分布是:分到标签类的概率是 1, 其他类概率是 0。但是理想很丰满,现实很骨感,我们不可能得到完美的概率输出,能做的就是尽量减小总样本的 KL 散度之和(目标函数)。这就是 Softmax 回归或者 Logistic 回归中 Cost function 的优化过程啦。(PS:因为概率和为 1,一般的 logistic 二分类的图只画了一个输出节点,隐藏了另外一个)
参考资料:
[1]机器学习中距离和相似性度量方法
http://www.cnblogs.com/daniel-D/p/3244718.html
http://en.wikipedia.org/wiki/Jaccard_index
[3] Wikipedia. Hamming distance
http://en.wikipedia.org/wiki/Hamming_distance
[4] Pearson product-moment correlation coefficient
http://en.wikipedia.org/wiki/Pearson_product-moment_correlation_coefficient