爬取上交所公司信息,根据公司股票代码获取公司注册地址以及地址的经纬度
之前爬取网页上的静态数据时,直接解析页面html内容即可,但是有时候会遇到table数据内容存放于动态的JavaScript中,使用浏览器才能加载出来,简单的爬取网页的html内容,发现找不到数据。此时需要phantomjs这个模拟器,能解析出隐藏在JavaScript中的动态table数据。
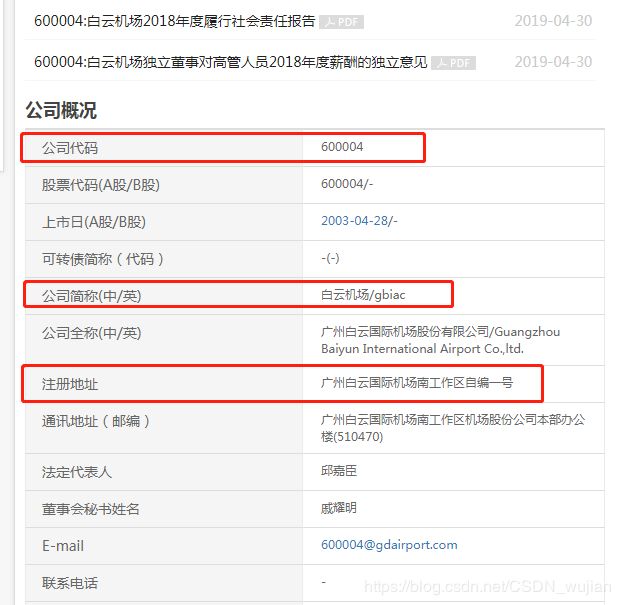
任务:根据上交所上市公司的股票代码,爬取该公司的注册地址,并利用百度地图api获取地址的经纬度。
爬取的url:http://www.sse.com.cn/assortment/stock/list/info/company/index.shtml?COMPANY_CODE=600004
方法代码如下:
- 下载phantomjs.exe文件,利用selenium和PhantomJS模拟浏览器的方式去动态获取网页内容。
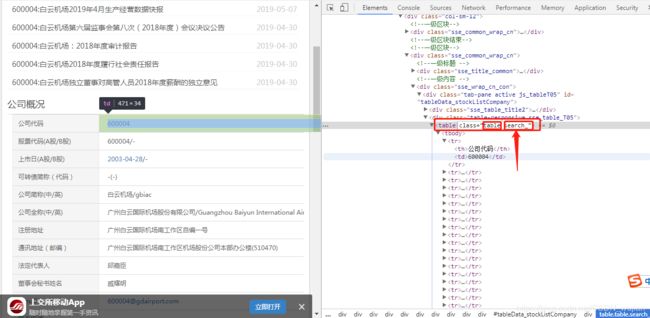
- 解析模拟浏览器获取到的内容,driver.find_element_by_class_name找到需要查找的html中的标签 “search_”。
- 读取数据,取出股票代码,逐个获取注册地址信息。
- 利用百度地图API获取地址的经纬度。
selenium和PhantomJS模拟浏览器的访问url,获取并解析JavaScript中的动态table数据,代码如下:
# encoding:utf-8
import time
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
# 使用selenium
phantomjs_path = "../phantomjs/phantomjs.exe"
driver = webdriver.PhantomJS(executable_path=phantomjs_path)
driver.set_window_size(1366, 768)
headers = {
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/56.0.2924.87 Safari/537.36',
'Referer': 'http://www.sse.com.cn/'
}
def get_company_addr(company_id):
url = "http://www.sse.com.cn/assortment/stock/list/info/company/index.shtml?COMPANY_CODE=%s" % company_id
# 使用selenium
driver.get(url)
time.sleep(2.5)
try:
element = driver.find_element_by_class_name('search_')
except Exception as e:
print("********")
print(e)
return None
data_list = element.text.split("\n")
company_name = data_list[4].split()[1]
company_name = company_name.split("/")[0]
addr = data_list[6].split()[1]
addr = addr.split("/")[0]
print(company_id, company_name, addr)
return company_name, addr
批量股票代码数据获取地址信息,添加异常处理,对应代码如下:
# 获取上交所的上市企业信息的经纬度信息
def get_addr_infos():
data_path = "data/最终3321.xlsx"
data = pd.read_excel(data_path, header=None, dtype="object")
company_id_list = data[1].tolist()[:1296]
df = pd.DataFrame(dtype="object")
df["股票代码"] = company_id_list
df["公司名称"] = None
df["注册地址"] = None
df["经度"] = None
df["纬度"] = None
for i in range(len(company_id_list)):
print(company_id_list[i])
infos = get_company_addr(company_id_list[i])
flag = 0
while infos is None and flag < 3:
time.sleep(10)
print("---第%s 次查询公司的注册地址---"%flag)
infos = get_company_addr(company_id_list[i])
flag += 1
if infos is None:
print("查询公司地址信息失败")
infos = ("", "")
df.loc[i, "公司名称"] = infos[0]
df.loc[i, "注册地址"] = infos[1]
print("获取上交所公司地址信息完毕")
df.to_excel("data/上交所股票列表.xlsx", encoding="gbk", index=False)
批量把公司的地址获取对应的经纬度数据,参考我之前的博客:Python基于百度地图API根据地址获取经纬度
# encoding:utf-8
import requests
import time
# 此处需要ak,ak申请地址:https://lbs.amap.com/dev/key/app
ak = "xxxxxxxxxxx"
headers = {
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/56.0.2924.87 Safari/537.36',
'Referer': 'https://restapi.amap.com/'
}
# 地理信息解析
def amp_geocode(addr=None):
url = "https://restapi.amap.com/v3/geocode/geo?parameters"
params = {"key": ak,
"address": addr}
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
try:
loc_info = response.json()["geocodes"][0]["location"]
lng = loc_info.split(",")[0]
lat = loc_info.split(",")[1]
print(loc_info)
time.sleep(0.25)
return (lng, lat)
except Exception as e:
print("Exception in amp_geocode",e)
time.sleep(5)
return None
else:
print("========>", response.status_code)
time.sleep(5)
return None
# 获取上交所的上市企业信息的经纬度信息
def get_loc_info():
data_path = "data/上交所股票列表.xlsx"
df = pd.read_excel(data_path, dtype="object")
company_id_list = df["股票代码"].tolist()
df["经度"] = None
df["纬度"] = None
for i in range(len(company_id_list)):
addr=df.loc[i,"注册地址"]
print(addr)
loc = amp_geocode(addr)
flag = 0
while loc is None and flag < 3:
time.sleep(8)
print("**** 第 %s 次地址解析****"%flag)
loc = amp_geocode(addr)
flag += 1
if loc is None:
loc = (0, 0)
df.loc[i, "经度"] = loc[0]
df.loc[i, "纬度"] = loc[1]
print("获取上交所公司的经纬度信息完毕")
df.to_excel("data/上交所股票列表2.xlsx", encoding="gbk", index=False)
if __name__ == "__main__":
get_addr_infos()
get_loc_info()
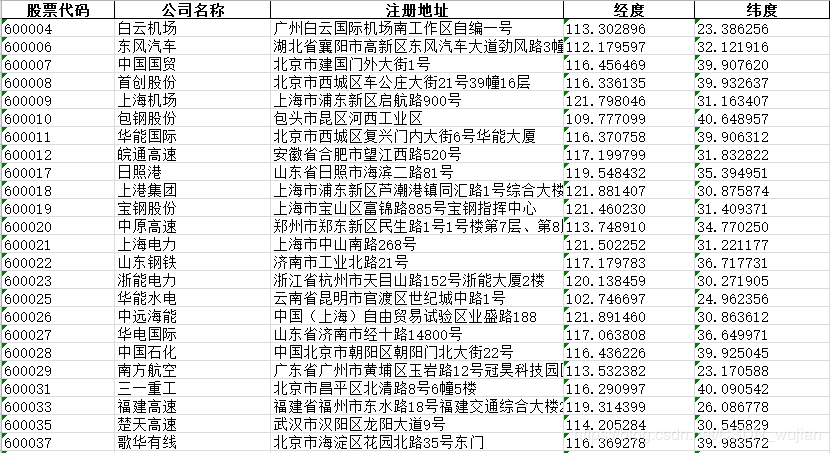
最终的结果如下:
总结
- 针对使用JavaScript动态加载的数据,这是一种防爬的措施,要使用selenium、phantomjs模拟真实浏览器,这样才能访问到数据,再解析出来。
- 爬虫时刻注意异常处理,防止各种突发状况。
- 多动手实际做做,很多爬虫和防爬一直不断的改进升级,需要根据实际情况采取相应的变化措施。