Python 爬取 6000 篇文章分析 CSDN 是如何进入微信 500 强的


CSDN 小姐姐们恭祝所有朋友新年快乐!
作者 | 罗昭成,设计 | 张藐,责编 | 唐小引
出品 | CSDN(ID:CSDNnews)
亲爱的小伙伴们,马上就到 2019 年了,你的 2018 年的计划都完成了吗?
这一年,互联网、技术圈发生了很多大事。譬如,曾经风光无限的 ofo 陷退押金风波;子弹短信横空出世,震惊朋友圈;“长春长生”疫苗事件,闹得沸沸扬扬,一位程序员挺身而出追根溯源;暗网论坛中公开出售华住旗下所有酒店的数据,用户隐私惨遭泄漏;因人工智能的火热 Python 在编程语言榜步步攀升……
这一年,CSDN 以技术人的独特视角,描述了众多技术人所关心的焦点事件,为技术人第一时间推送并解读业界正在发生的事情,并以技术干货、前沿技术、编程语言、程序员职场与技能提升等内容,希望能够帮助所有从事开发的朋友们更好地成长。
在这连朝接夕全年不休地推送文章给所有朋友的同时,我们也收获了更多的关注者、更高的阅读量、更多的认可、更高的赞许,甚至于某一日突然发现在内容创业服务平台新榜上被打上了“500 强”的标识。更至关重要的,是所有开发者朋友们,每一次的阅读、转发、点赞(好看),都是我们能够在凌晨还开着电脑奋笔疾书的动力。
CSDN 是属于所有技术人的,在这个大家庭里,我们一起学习技能共同成长,分享精彩的程序人生。过去一年里,有着非常多的开发者朋友通过 CSDN 公众号分享了自己的经验及思考,并与读者互动交流,譬如《C++20 要来了!》、《为什么中国的底层创新做不起来?| 畅言》、《Google Fuchsia 对中国操作系统的启示 | 畅言》等等。
在 2017 年末,CSDN 的一位好朋友用数据分析了 CSDN 公众号一年都做了什么。现在,在这辞旧迎新之际,又有一位好朋友用 Python 抓取数据来分析 CSDN 到底给千万开发者带来了什么?
最后更有惊喜福利等你哟!
以下为正文:
![]()
如何爬取微信公众号文章?
作者注:先解释义,网络爬虫指的是按照一定的规则,自动抓取万维网信息的程序或者脚本。
读过笔者之前写的文章的朋友,肯定会知道,要抓取微信公众号文章,第一件事就是去找接口,之前都是在 Web 站点上去找。Chrome 的调试工具,能够很清晰地看到所有的网络请求,简单的分析,就能找到对应的 API ,但是在移动端,这件事情显然就变得复杂了很多。
Android 抓包
对于许多从事移动开发的朋友们来说,抓包是一个常用需求,在这里,笔者简要介绍一下基本步骤:
在你的个人电脑上安装抓包软件,推荐 Charles 和 Fiddler ,使用 Mac 的朋友建议使用 Charles ,使用 Windows 的朋友建议使用 Fiddler;
将手机与电脑连接在同一个局域网中;
在手机的 Wi-Fi 设置里面,手动设置代理,使用你的个人电脑代理手机的网络请求;
代理请求,抓取 HTTPS。
众所周知,HTTP 是进行明文传输的,可以很方便地看到上行与下行的数据。但是 HTTPS 使用的是加密传输,要看到上行与下行的数据,我们得事先知道通信的密码,才能解密看到真实内容。
为了解决这个问题,抓包工具会作为一个中间代理人,手机端与抓包工具进行通信,抓包工具再与服务端进行通信。手机端与抓包工具建立 HTTPS 请求使用的公钥是抓包工具下发给他的。所以,为了能正常通信,需要安装抓包工具生成的根证书。
通过上面两步,你可以轻松地抓取到使用 HTTPS 的请求。稍加分析,就能找到微信公众号文章列表获取数据的接口,在这个地方,笔者就不再多做赘述。
![]()
获取文章的点赞与阅读数量
现在,我们很轻松地就把 CSDN 好几年的文章爬了下来。但是要想拿到文章的阅读、点赞数,还需要去分析获取这两个数据的请求。经过仔细的分析,单从接口上来说,是可以获取到阅读、点赞数,但是获取这两项数据的请求,是微信客户端发的,上行参数中进行了签名和文章唯一 ID 的生成,找不到对应的生成算法。所以,此路不通。
为了能拿到这两项数据,网络上有一种方式的实现,使用的是 AnyProxy + MonkeyRunner ,笔者也是采用与之类似的方式:
AnyProxy + ADB Shell
AnyProxy 是一个基于 Node.js 的,可供插件配置的 HTTP/HTTPS 代理服务器。和上面提到的 Charles 、 Fiddler 类似,但更加适合开发者使用。
笔者使用 ADB Shell 中的命令,来模拟点击,以自动化的形式打开微信公众号中的文章。然后在启动 AnyProxy ,使用它提供的插件配置的功能,拿到评论的数据,并写入数据库中。
var url = require("url")
module.exports = {
*beforeSendResponse(requestDetail, responseDetail)
{
try {
var pathName = url.parse(requestDetail.url).pathname
if(pathName == "/mp/getappmsgext") {
saveReadCount(requestDetail, responseDetail)
}
} catch(err) {
console.log("err")
}
}
};
![]()
数据清洗与整理
在前面拿到的文章列表与点赞和评论数据中,保存的都是网络请求的详细数据,我们需要将所需的数据从原始数据中清洗出来,并将点赞数与请论数与文章关联起来。
注: 微信公众号的文章使用的是 __biz,mid,index 三个值来唯一确定一篇文章。
读取文章列表原始数据,并解析数据。逻辑很简单,代码如下:
def insertInto(cursor, msg):
list = json.loads(msg)["list"]
for listItem in list:
if not listItem.has_key("app_msg_ext_info"):
continue
commMsgInfo = listItem["comm_msg_info"]
appMsg = listItem["app_msg_ext_info"]
addAppMsg(cursor, commMsgInfo, appMsg)
if appMsg.has_key("multi_app_msg_item_list"):
subAppMsg = appMsg["multi_app_msg_item_list"]
for subAppItem in subAppMsg:
addAppMsg(cursor, commMsgInfo, subAppItem)通过文章中的相关信息,将阅读量与点赞数量关联到同一篇文章的数据中,解析阅读量与点赞数量有代码如下:
def getCount(articId):
conn = sqlite3.connect("wechat_read_cont.db")
conn.text_factory = str
cursor = conn.cursor()
articId = articId.replace("=", "%3D")
selectSql = "select responseBody from read_cont where url = \"" + articId + "\""
cursor.execute(selectSql)
values = cursor.fetchall()
if len(values) <= 0:
return "-1", "-1"
data = values[0]
appmsgstat = json.loads(data[0])["appmsgstat"]
conn.close()
return appmsgstat["read_num"], appmsgstat["like_num"]![]()
数据分析
经过前面一系列的处理,我们需要的数据已经存入了数据库表中去了。经过艰难的爬取,数据终于到手,先来膜拜一下 10W+文章:
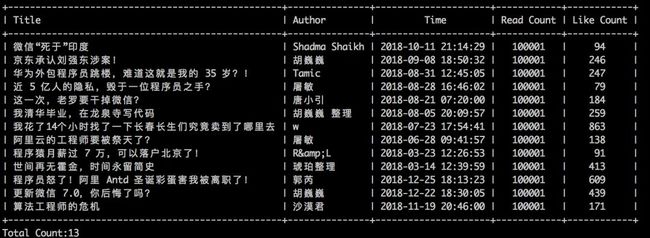
10W+文章阅读信息
因为是在控制台直接打印为了更好的格式化展示数据,使用了prettytable , 数据处理的代码如下:
def getArticInfos(min, max):
conn = sqlite3.connect('wechat.db')
conn.text_factory = str
cursor = conn.cursor()
cursor.execute("select title, author, datetime, readCount from messages")
values = cursor.fetchall()
table = PrettyTable(["Title", "Author", "Time", "Read Count"])
table.align["Title"] = "l"
table.align["Author"] = "l"
table.padding_width = 1
totalCount = 0
for item in values:
readCount = int(item[3], 10)
if readCount >= min and readCount < max:
table.add_row([str(item[0]), str(item[1]), str(item[2]), str(item[3])])
totalCount += 1
print table
print "Total Count:" + str(totalCount)
conn.close()
if __name__ == '__main__':
getArticInfos(100001, 100002)10W+ 已经成为了微信公众号文章的重要指标。在一个用户总量并不是很大的程序员圈子里面。产出如此多的 10W+ 文章,真的是行业翘楚啊。
听小道消息说,CSDN 是 2017 年下半年才着重开始运营公众号,恰巧,爬取的数据有 CSDN 全量文章数据,总计 6000 篇,所以我们可以对比看看 CSDN 公众号产出的文章数量:

历年文章数量
从上图可以看出,2018 年 CSDN 公众号差不多产出 2000 篇文章,平均每天产出至少 6 篇文章。不得不说,一个专业的技术媒体,他的实力是不容小看的。当然,CSDN 的编辑大大们,也辛苦了。感谢你们为我们贡献了如此多的知识内容。
回过头来,再来看一下从 2017 年到 2018 年,数据的增长趋势是什么样子的。如下图:

每月发表文章数
从上图可以看到从 2017 年 9 月份开始,文章总数开始增加,甚至出现直接翻倍的情况,说明 CSDN 开始投入人力资源运营公众号,2018 年春节,文章数量略有减少,年后文章数量开始增多,最多的时候,一个月产出了 236 篇文章,真是佩服得五体投地。
2018 年都已经结束,CSDN 都发表了 2000 篇左右的文章。这些文章都有些什么内容?拿到标题,使用“Jieba”分词,制作词云图,如下图所示:

词云
我们可以明确地看到,随着 AlphaGo 横空出世,机器学习、人工智能在技术领域崛起,未来已来深入人心。机器学习让 Python 这门编程语言在更多的开发者面前展现出来,从图中也可以看到,Python 在 CSDN 的文章中出现频率也非常高,CSDN 深度为千万开发者解析,想开发者所想,手动为他们点赞。
不仅如此,不管是正面的科技大佬 "马云"、“马化腾”,还是负面的科技大佬“贾跃亭”等都频繁地出现在我们的视野中,CSDN 的小姐姐们也在第一时间为我们提供科技界的新闻趣事。
2019 年刚刚开始。准备好迎接新的一年了吗?没准备好也没关系,反正 2019 年都会来的。
最后为所有小伙伴们送上一句至理名言:
我 2019 年的目标就是搞定 2018 年那些原定于 2017 年完成的安排,不为别的,只为兑现我 2016 年时要完成的 2015 年年度计划的诺言。

图片来源:表情说说,发布者:Hey.M
![]()
One more thing...
最后的最后,为了感谢广大陪伴 CSDN 一起前行的读者朋友们。本次 CSDN 联合博文视点,为大家送出 5 类总计 10 本的高评分科技图书。
在本文评论区留言点赞最高的前十名,即可获得一本科技图书(随机发货哦),开奖时间为 1 月 1 日下午 17:00 整,喜欢就赶快留言吧!
 从零开始,Python 编程从入门到实践一网打尽。网络爬虫、大数据分析与展现、并发编程等一个不漏。
从零开始,Python 编程从入门到实践一网打尽。网络爬虫、大数据分析与展现、并发编程等一个不漏。

本书作者老钱在使用 Redis 上积累了丰富的实战经验,可以帮助更多后端开发者更快、更深入地掌握 Redis 技能,还能帮助读者更轻松地通过技术面试,进入心仪企业。
《Netty进阶之路:跟着案例学Netty》
Netty 将Java NIO 接口封装,提供了全异步编程方式,是各大 Java 项目的网络应用开发必备神器。
本书作者是国内 Netty 技术的先行者和布道者,本书是他继《Netty木又威指南》之后的又一力作。
《你也能看得懂的Python算法书》 本书面向算法初学者,首先介绍当下流行的编程语言 Python,详细讲解 Python 语言中的变量和循序、分支、循环三大结构,以及列表和函数的使用,为之后学习算法打好基础。
本书面向算法初学者,首先介绍当下流行的编程语言 Python,详细讲解 Python 语言中的变量和循序、分支、循环三大结构,以及列表和函数的使用,为之后学习算法打好基础。
然后以通俗易懂的语言讲解双指针、哈希、深度优先、广度优先、回溯、贪心、动态规划和至短路径等经典算法。
《智能问答与深度学习》 本书由浅入深地介绍了人工智能在文本任务中的应用。不但介绍了自然语言处理、深度学习和机器阅读理解等基础知识,还简述了信息论、人工智能等的发展过程。
本书由浅入深地介绍了人工智能在文本任务中的应用。不但介绍了自然语言处理、深度学习和机器阅读理解等基础知识,还简述了信息论、人工智能等的发展过程。

热 文 推 荐
☞ 36 小时,程序员可以开发出什么?
☞ 董明珠:格力绝不裁员;腾讯缺席首批游戏版号;iPhone XS Max 口袋自燃 | 极客头条
☞ 软件开发者只要会敲代码就可以了?
☞ 无业务不技术:那些誓用区块链重塑的行业,发展怎么样了?
☞ 下一次 IT 变革:边缘计算(Edge computing)
☞ 12306 脱库 410 万用户数据究竟从何泄漏?
☞ 年度重磅:《AI聚变:2018年优秀AI应用案例TOP 20》正式发布
☞ 老程序员肺腑忠告:千万别一辈子靠技术生存!
print_r('点个好看吧!');
var_dump('点个好看吧!');
NSLog(@"点个好看吧!");
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
fmt.Println("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
 点击“阅读原文”,打开 CSDN App 阅读更贴心!
点击“阅读原文”,打开 CSDN App 阅读更贴心!