DeepID-Net:multi-stage and deformable deep CNNs for object detection
论文贡献:
1.融合多种技术进行目标检测:feature representation learning, part deformation learning, sub-box feature extraction, context modeling, model averaging, and bounding box location refinement
2.预训练方法:使用1000类object-level带标记的样本,之前的使用image-level带标记的样本。
3.形变限制池化层(def-pooling)学习part的信息
4.multi-stage 训练,每步的分类器处理不同难度的样本,所有的分类器联合优化
5.model average策略,不同的网络结构和训练策略组成的不同模型进行融合。
baseline方法:RCNN

论文对RCNN方法做了改动或修补,框架如下:
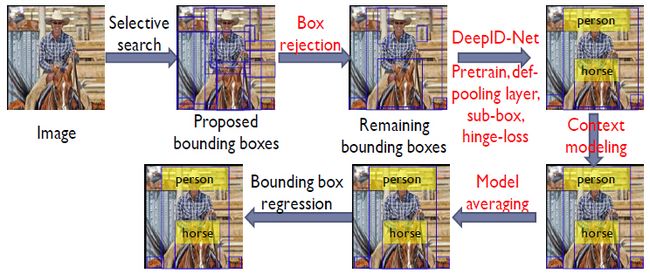
bbox rejection
Selective Search 提取proposals,使用现有的RCNN方法对bbox进行打分,得分满足以下条件的bbox剔除:
||si||<−1.1
得分是-1的是支持向量,剔出了94%的样本。
使用Deep-ID Net进行bbox分类
Deep-ID网络架构如下所示:

新的预训练策略
1.使用带标记object-level 1000类图像预训练网络
2.200-类目标检测任务微调
带有multi-stage 训练的全连接层
类似于级联,又能用BP联合优化的多级分类器,不同级分类器处理不同难度的样本,在conv5后实现,如下图所示:
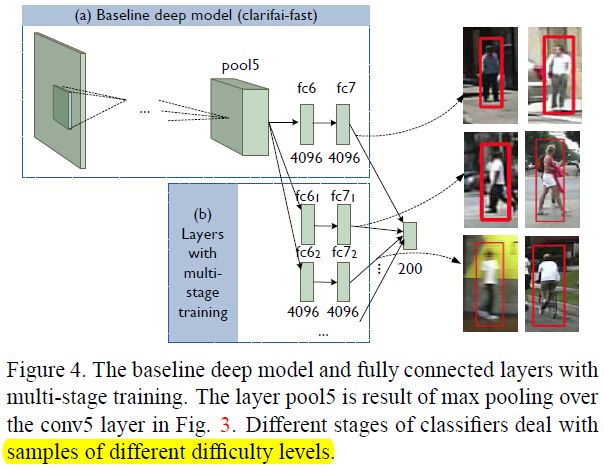
conv5层后面加了多个fc6,fc7,对于t步,权值随机初始化,BP进行训练,1~t的权值联合优化,每步新引入的分类器处理上一步被错分的样本,算法如下所示:

def-pooling层
目标的局部大小不一,设计不同尺寸的分类器与conv5层卷积,def-pooling层的结果如下所示:

包含四部分:
1.conv5层分别与3*3,5*5,9*9的滤波器卷积获得128通道的part特征图,用conv61,conv62,conv63表示。
2.输入def层学习形变约束
3.将def层的输出与1*1的滤波器卷积,得到fc7层
4.fc7层用来做类别预测
M表示con6输出的大小V*H,def层在block B内对M进行下采样:

其中 kx,ky 是下采样步长, (kx⋅x,ky⋅y) 是block中心,若 cn=0 ,对part放在任何位置没有惩罚,退化为最大池化,即def池化与最大池化的区别是有惩罚项。若 V=kx,H=ky ,def池化层退化为deformation层,形变层可认为是DPM中所使用的二次形变约束,M的输出只有一个,下图显示了该方法的细节。

def池化层与deformation层的区别:
deformation层只有一个输出,def层在多个空间位置有多个输出,可学习共享的模式,如下图所示:

sub-box特征
将bbox r0 划分为四个子窗口,子窗口尺寸为根窗口的一半,对于任意一个子窗口,选取在SS方法产生的bbox中选取与其IOU最大的,对四个窗口的特征求最大求平均得到最大池化和平均池化子窗口特征,与根窗口特征串联,得到 r0 最终的特征。subbox将mAP提升0.5%。
图像上下文信息
由于图像带有场景信息,1000类图像识别结果可以作为上下文特征,如下使用:
1.将1000类图像识别得分和200类目标检测得分串联得到1200维特征向量;
2.学习200类1-all线性SVM,测试时将1200维特征向量的线性组合作为refined的得分。
下图显示了排球1000类图像识别的得分,对泳帽和高尔夫球进行了抑制:

模型平均
使用了10个模型对结果进行平均,10个模型仅在预训练方式,损失函数,是否有def池化/subbox特征/proposal 剔除之间变换,每个模型参数如下表所示,模型平均后mAP为40.7%。