吴甘沙清华演讲:大数据的十个技术前沿(完结篇)
吴甘沙清华演讲:大数据的十个技术前沿(完结篇)
来源:数据派 时间:2015-01-05 17:39:06 作者:清华大数据产业联合会

吴甘沙院长从大数据技术前沿的十个问题入手,对大数据产业进行了深度解析。讲座分为三部分:
- 领先的大数据科研单位和企业正在如何利用大数据
- 解决大量的数据前提下,优化实时计算技术
- 怎样通过数据采集与分析做出更好、更精确的决策支持
演讲正文:



首先我们公司要求要有一些免责方面的要求,个人也是免责,今天讲的是我个人的认识。
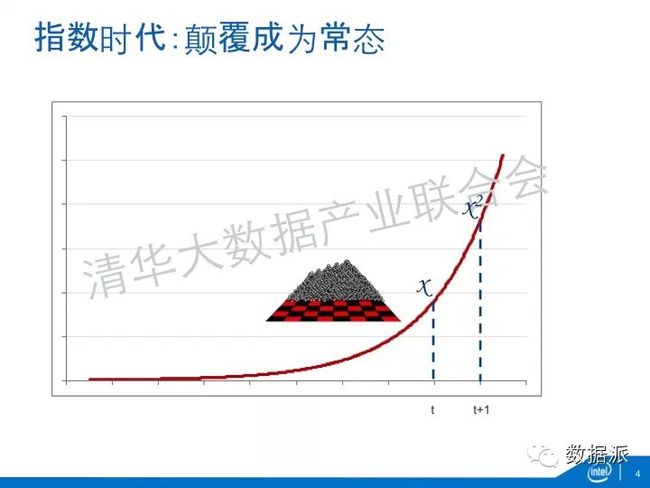
现在说大数据,我希望大家做研究的有一种思维方式,在美国有一个未来研究院的发起人,他叫阿马拉,他提到一个阿马拉法则,人们往往会高估技术的短期影响力,而低估技术的长期影响力。技术的长期影响力代表着技术的积累效应。我们现在常常用指数效应来说明,在现在这个指数时代,指数效应或者指数的颠覆性效应是一种新的常态。我们经常在大数据的领域听说,有人说我们现在的数据量非常大,最近两年产生的数据量相当于人类历史上产生的数据量总和的90%。有人说,最近一天产生的数据量相当于人类文明开始到2003年这数万年人类产生数据量的总和。IDC说,现在人类产生的数据总量每两年翻一番。所有这些都说了一个事情:指数的效应。
看一下这个曲线,在经历很长时间的缓慢增长之后,突然在一个点它拐头向上,产生了爆炸式的增长。在这个时间点,T如果是X的话,T 1就是X的平方。当X很大的时候,它在任何一个周期都会把前一个周期远远的抛离在深厚。

大家一定听过棋盘和麦粒的故事,8乘8的棋格,第一格放1粒,第二格放2粒,到后面积累就会爆发式的增长,到一个国家承受不了的程度。
摩尔定律,这张泛黄的纸片是当时英特尔的联合创始人之一戈登·摩尔(Gordon Moore)写下的纸片,他推动了现在社会的飞轮效应。每过18个月,晶体管数翻一番,它进一步带来了一系列指数式的链式反应。处理器的性能也翻一番,成本折半,功耗折半。同时,在一些临近的领域也触发了指数效应。比如说以氧化铁为主要承载物的存储,也有类似的指数效应。比如说主干网的带宽甚至每八个月都会翻一番。甚至是每美元能够买到的数码相机的像素的数目也呈现了指数级的效应。所有这些带来了数据的摩尔定律。
所以我一直一个论点是,在这个社会,大数据是我们的蛋白质。蛋白质是我们生命活动的基础,也是我们生命活动主要承载者,它对于我们这样一个社会实在是太重要了。我们形容数据是资产、是原油、是原材料、是货币,无论哪种形容的方法都不过分。因为它关系到70亿人数据化的生存,以及2020年500亿个互联设备的感知、互联和智能。所有这些乘起来产生了2020年35个ZB的数据。在2020年一年会产生35个ZB的数据。一个ZB相当于一千个EB,谷歌已经把互联网吸纳在他的数据存储中了。他的数据的存储量差不多在个位数的EB或者几十个EB之间。2020年一年就会产生一千个谷歌的数据。这是一个多大的量?当然我们不能只是强调数据量多大。而是说在这个数据里面我们能够提取出什么样的意义来。提取的过程就是这样一个函数,F(数据,T)。

这么大量的数据给我们带来了什么样的挑战。全集大于采样。传统的数据分析是能够采样的,他能够抓到一定的统计的数据特征。但是大数据要求的是倾听每一个个体的声音。他不希望把一些个体的东西变成噪声过滤掉。所以这是带来的第一个挑战。
第二个挑战是实时性。数据的价值是跟它的寿命成反比。当数据刚刚产生的时候,它的价值是最大的,尤其是个性化的价值是最大的。随着时间的推移,它会蜕变到只有几何的价值。我们需要实时处理,并且把这个实时的洞察跟我们长期积累下来的知识进行融合,变成之前或万物皆明的全时的智慧,这是第二个挑战。
第三个挑战是F,我们的分析方法是不是能够做到见微,又能够做到知著。同时,也能够理解每一个社会运行的规律。这对F要求非常高。第四,他反映了人与机器的关系,或者人与工具的关系。我们说希望数据能够说人话,数据的价值是人能够理解,并且能够执行的。
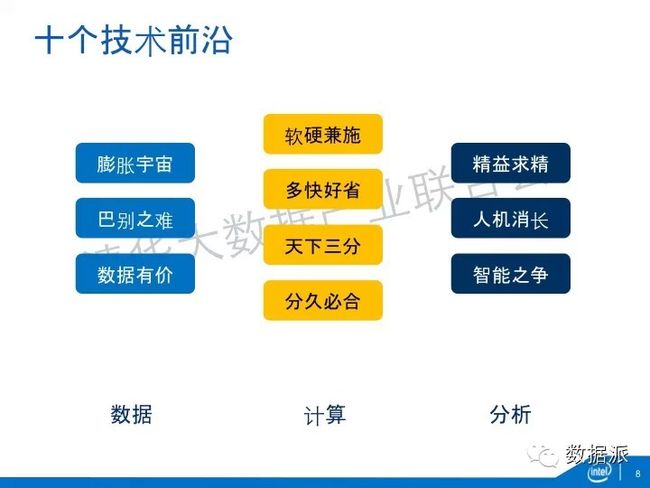
很多大数据的技术基本上是为了解决这四个问题。我今天要讲的十个技术前沿,基本上都落到刚才这四个需求里。但是我又把它分成三大类:
第一大类,解决数据的问题。
第二大类,解决大量的数据前提下,如何能够实时的计算问题。
第三大类,我的分析怎么能够提供更好的、更精确的价值的问题。
所以我下面会根据这十个技术前沿,跟大家介绍一下现在我们领先的大数据的科研单位以及企业都在做什么样的事情。

第一,膨胀的宇宙
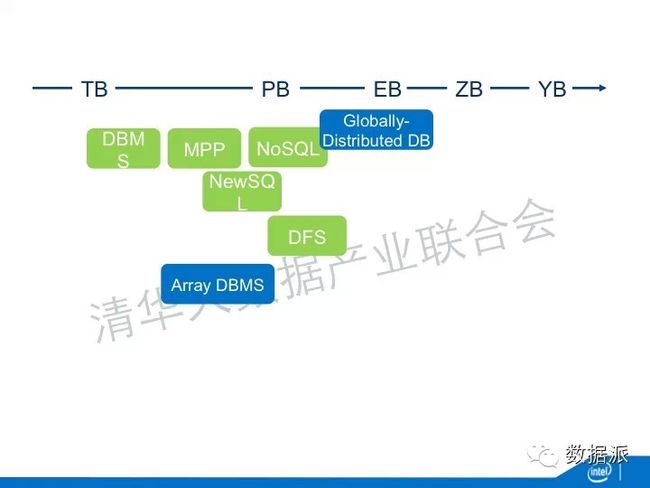
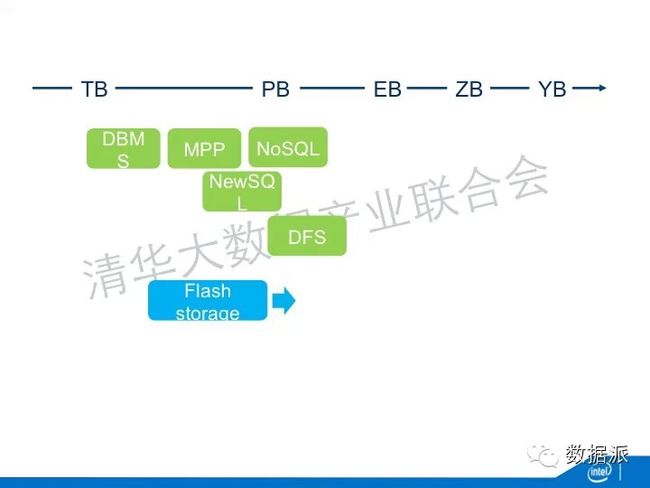
IDC创造一个名词叫做DATA UNIVERS——数据宇宙。它的膨胀速度是非常快的。现在我们的硬盘是TB,到PB到EB到ZB,甚至再到下一步DBMS。
在这条路线延续的同时,文件系统也在延续,文件系统对于非结构化的数据具有更好的存储能力。所以DFS能够处理比NoSQL更大的数据量。有一些NoSQL的数据就是建立在DFS的基础上。这时候有一部分人就想NoSQL损失了很多的特性,但是在商业场景里面,我从帐号里面取了钱,我要保证这笔交易是符合事物特性的,不会存在我取了一百块钱,但是在数据库里面显示那一百块钱还在里面。怎么在更大量数据的基础上来实现这种事物特性呢?于是就出现了NewSQL,NewSQL一方面处理的数据量比传统的数据库更大;另一方面,它又能够满足事务的特性。当然NoSQL还在进一步的演进,从几十个PB的规模,进一步演进到EB的规模,进一步出现Globally Distributed DB的规模,百万台服务器的规模。谷歌的Spanner就是一个典型的distributed DB。它为了达到事务特性,它需要部署很多新的技术,比如说利用GPS进行全球的时钟同步。
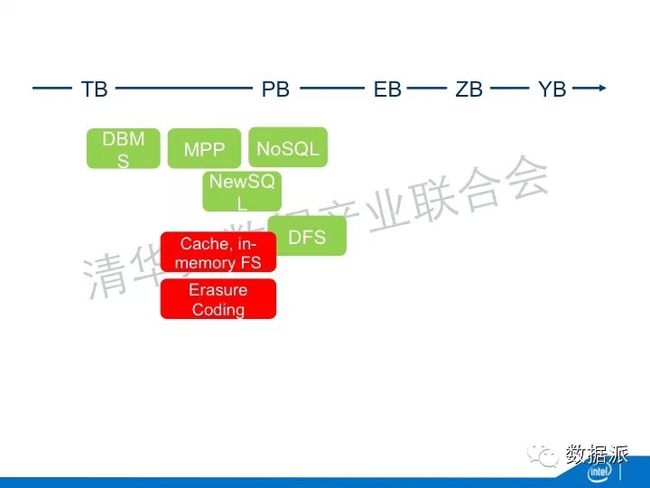
另外一个演进是Array DBMS,很多计算是现行函数,它跟关系函数很不一样。Array DBMS就应运而正了,最主流的是SciDB,它就是针对科学计算、针对现行计数的数据。这就是一个主流演进的图谱,但是它还没有结束。在文件系统方面,因为纯磁盘的访问使得它有吞吐量的瓶颈。于是出现了利用RAM做缓存的现象。比如说最著名的HDFS就有了内存、缓存的扩展。同时,也出新了in Memory的FS,它把文件系统放到大的内存里面。而且,现在主流的大数据的处理都是基于JAVA。JAVA内存回收是通过一个处理器。对于几百个EB的信息,垃圾回收器不是特别的有效。于是又出现了堆外面的内存,它在堆外面又放了大量的数据。
另外一个是Erasure Coding,它最早在通讯领域,是因为无线的信道有很大的出错的可能性。它通过编码机制能够使得我这个传输是能够容错,甚至是纠错的。现在它也被用到了大数据上面。大家如果熟悉Hadoop的话,就知道在DFS上面曾经出现了几种时限,每一种都是因为种种原因并没有得到推广。最近英特尔跟Cloudera一起,推了一种新的Erasure Coding。
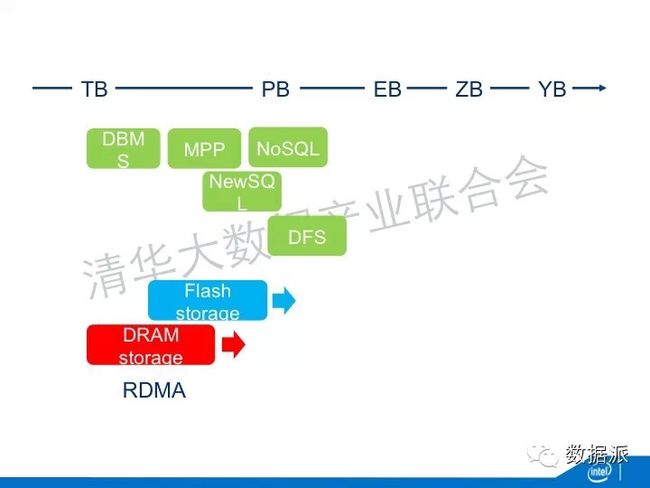
DRAM Storage也出现了,就是我所有的数据都存在DRAM里面,它进一步提升了吞吐量,减少了延迟。但是DRAM有一个问题,DRAM是易失的,一掉电这个数据就不存在了。你为了让他能够起到存储的作用,就必须要想办法,比如说通过冗余的方法在不同节点里面都存同一个数据,这样一台机器宕掉了,它的数据还能够存在。当你的数据都留在内存里面以后,不同节点之间数据的传输就变得非常重要。传统的数据传输是通过网卡、TCPIP的协议栈,这个效率是非常低的。在高性能计算里面,出现了RDMA,高性能计算里面都是非常高大上的,这些技术非常昂贵,本身的扩展性也不够。所以现在基于大数据的高扩展性的RDMA也是现在研究的热点。
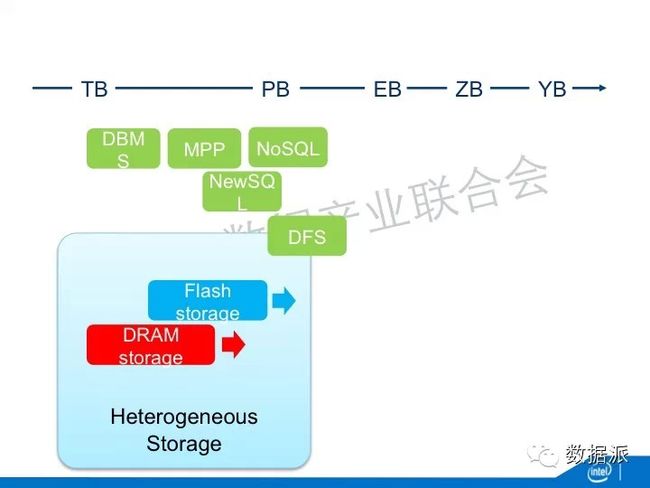
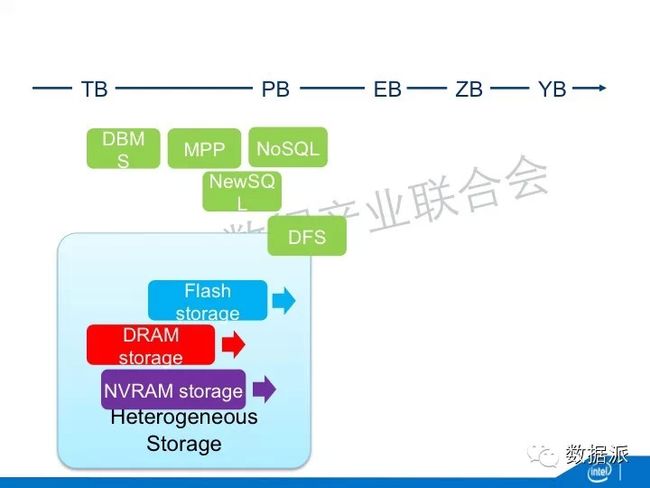

所以这几种新的介质放在一起就出现了Heterogeneous Storage,你能够根据数据访问的频率,能够智能的把数据放在不同的介质上面。比如说访问最频繁的就放在DRAM或者是Flash,不太频繁的就放在传统的磁盘里。这做的好与不好关系非常大。谷歌有一个工作,他能够保证他只把1%的数据放在闪存里面,但是这1%的数据的闪存接受了28%的数据的访问。如果你的数据分布算法做的好的话,你可以以非常低的成本提供更大的吞吐量。
未来,会出现Memory,它的性能跟DRAM相差不多,但是它的容量更大,它不会丢失,如果数据里面的内存不会丢失,整个系统的软件就有可能会发生一些革命性的变化。比如说你不用再做序列化和反序列化了。你甚至不用文件了。因为原来用文件是因为我在磁盘里的数据的状态跟内存里面数据状态是不一样了。但是你现在在这个状态里面,你休息的状态跟被使用的状态是一样的。你不需要从文件里面把数据读出来,转化成为计算的格式。所以non-volatile的出现会对大数据的软件化出现革命性的变化。
non-volatile还有一种选择是磁带机。它还在被大量的使用。谷歌是全世界磁带系统最大的买家。因为他要备份他的几十个EB的数据。他大量的数据都是在磁带机里面,磁带本身的介质也在变化,最先出现的钡铁的形式,它的稳定性更好。

第二,巴别之难
圣经里有一个巴别塔,最早人类都是同一种,讲的语言也都是一样的。上帝觉得你们太舒服了。他说人类要造一个巴别塔,他让你们说不同的语言,让你们沟通产生困难,让你们分布到不同的地方去。数据也面临同样的问题,数据并不是在同一个地方说同一种语言。
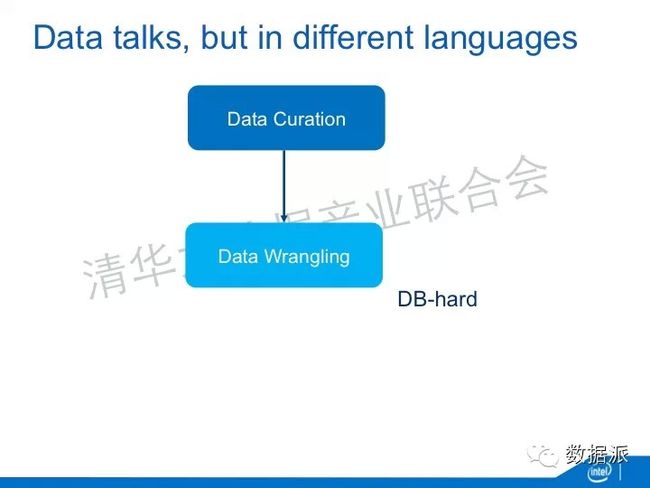
数据能够相互说话,但是他们用不同的语言。他们的格式可能是不一样的,他们的语意不一样,他们的度量衡不一样。数据可能是不完备的,甚至是相互之间矛盾,这样导致了一个问题,我们没有办法利用更多的数据来产生更好的价值。为了实现这个一定要做一件事情叫Data Curation,数据的治理,数据质量的提升。Data Curation里面最有提升价值的是Data Wrangling。在计算历史上有很多hard的问题,有一种NP—hard,还有一个叫DB—hard,它的意思是你在这个地方输入地址是这样写的,在另外一个地方输入地址的写法不一样,事实上他们代表的是同样一个东西。Data Wrangling就是希望把数据的逻辑打破。
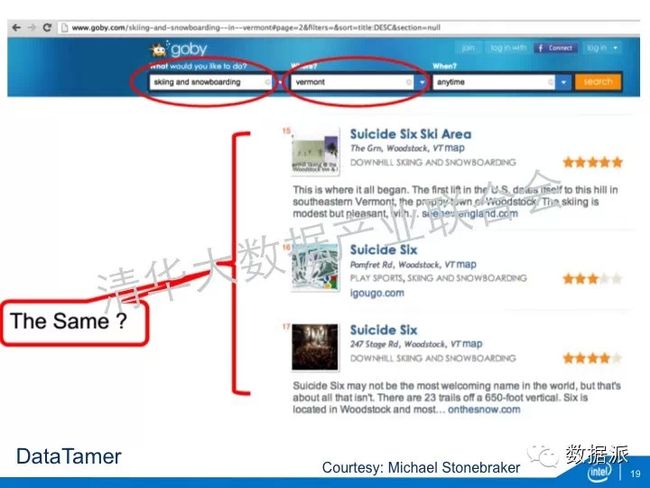


怎么通过自动化的学习方式,怎么能够发现数据中的规律,尤其是文本这样一种典型的非结构化数据,怎么能够发现规律。其次怎么能够发现重要的实体。本体论里面一个重要的概念,反应我们一个描述对象的属性的单位就是entity,我们怎么找到这些entity,这一切是希望能够通过自动化的学习来完成。而且希望能够从半结构化或者多结构化的数据进一步推展到完全非结构化的数据。
你提炼出来的这些数据和原数据,需要有一种更好的组织方式。现在一个冉冉升起的组织的工具叫做Apache的UIMA。如果这个大家比较陌生,大家一定听说过IBM的Watson。前两年在美国的一个类似于开心辞典的节目,一个计算机战胜了两个非常高智商的人。在它的信息的组织就是通过Apache的UIMA来组织,它的组织能够使后期的分析最简化。这个是解决巴别之难的现在的主要研究工作。
第三,数据有价

数据是比特,比特是可以低成本无限的复制,一旦一个数据或者一个东西失去了稀缺性以后,它的价值就是零了。所以,数据有价首先要保证你要定一些数据的权利。在这样一些权利的指导下,你要保证数据的安全。大数据的安全本身又分为大数据系统的安全、数据本身的安全,以及数据使用当中的安全。最后是数据怎么来进行定价。我在第三个前沿里面希望能够给大家分析一下这一块主要的研究成果。

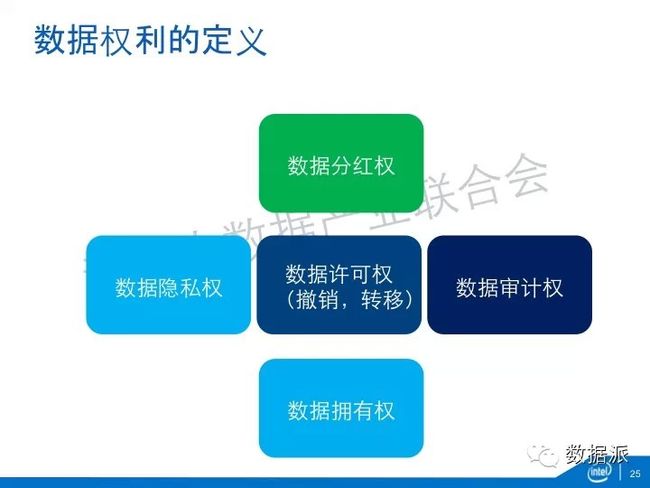
第一,数据权利的定义。数据我认为有五个基本权利:第一,拥有权,这个数据是属于谁的,这个拥有权是不含糊的。就像我们现在拥有的其他的物理的财产一样,拥有权可能会出现变更,比如说离婚了,这个权利怎么分割,人死了怎么来传承。这里面都涉及到数据拥有权的研究。第二,数据隐私权,我什么东西不能给你看。第三,数据许可权,我什么东西可以给你看,今天给你看了明天不能给你看。第四,数据审批权,我按照这样一个规范许可给你以后,需要有一种机制审计,确保你是按照这种规范、按照这种许可的条例使用我的数据。第五,数据分红权,对于新产品的数据价值,我有没有可能得到分红?这是我定义的数据几种权利。
下面就是数据的安全问题,首先我怎么保证一个大数据的系统安全,比如说Hadoop,慢慢加入了基于Kerberos的用户和服务鉴权。HDFS文件和数据块权限控制。未来是高度分布、去中心化场景下的安全,数据使用实体之间并不需要存在信任。不存在单点可控制的机制。最典型的就是类似于比特币和Ripple的获取。比如说block chain,它是对数据最价值的获取。

对数据的安全,第一个方法是加密,Hadoop新的功能就是可以对数据进行加密。第二,访问控制。Apache Accumulo,它也是一个开源数据库。在Hbase里面也在加入类似访问控制的安全。
动态数据的安全,这个数据只有你能访问,我不能访问。这种静态控制不能防止一种攻击,你有权访问了,你把数据取出来了又给了我。因为他不存在一种动态的进行跟踪的机制。所以现在有对数据的移动进行动态的审计。
个人对数据的控制。现在我们个人对自己的数据有了一定的控制权限,比如说Do Not Track,现在浏览器都有这种功能,如果你不把它打开,各种各样的互联网服务商就可以根据你的Cookie不断的跟踪你,你在京东上看中一双鞋,你到淘宝上它就会一直跟踪你。你打开Do Not Track,它就不能跟踪你了。现在各种不同的AP可以跟踪你,你一旦关闭“跟踪”选项,他就不能跟踪你。个人数据的删除你可以要求一些互联网的服务提供商把你的数据删掉。这是MIT做的,他以隐私的方式向第三方提供数据,并且获得价值。

数据安全中现在最热的一个研究领域,叫做数据脱敏。尤其是开放数据,我如果要把数据开放出去的话,我怎么能够保证这个数据里面不会把一些个人的隐私信息泄露出来,在历史上很多的数据开放就导致了这样的问题。美国的国会,有人把他的搜索数据跟美国选举公开信息进行了匹配,使得他个人的隐私被暴露了出来。去标识符往往是不彻底的,这里有一个准标识符,对于个人来说,姓名是标识符,准标识符是性别、出生年月、邮编,在美国做的研究,只要根据这三个信息,准标识符的信息,有90%几的可能可以把个人确定下来。你要防止这样的隐私供给。
还有一种基于统计的攻击。如果我能够知道一个人的活动规律,同时我知道他一天在四个不同的时间点,出现在不同的基站周围,我有95%的可能性把他确定下来,所以要防止这些隐私攻击,现在推出了很多的技术,比如说K-anonymity,当你的准标识符都相同的话,这个数据组里面我还是至少有k个值,不是只有一个值,如果只有一个值,你马上把这个人确定下来。希望能够有K个值。L-diversity中,他是希望K个数据中至少有L个不同的值。第一种匿名的机制只保证有K个数据,但是他还是有类似性。左翼进一步要求这K个数据有L个不同的值。T-Closennss进一步保护你的隐私性。Differential privacy会人为的插入一些噪声,但是又不干扰你进行分析,他在插入噪声的同时又不影响这些噪声的分析,这是插分隐私。当然这里面要注意隐私的安全性和数据的可用性。因为你插入的噪声太多了,数据本身的价值下降。

第三种安全是数据使用的安全,我们希望数据使用能够做到可用但不可见,相交但不相识。我希望几个人的数据凑在一起产生更大的价值。但是我又不希望你能看到我的数据,或者我看到你的数据。这里面有几种技术,一种是同态加密技术,CsyptDB/Moomi。另外一种是基于加密协议的多方安全计算。第三种是基于可信计算环境的多方安全计算。可信计算环境需要一些硬件的支持。我这些列举的TXT、TPM、VT—d,都是英特尔现在平台上的,他能够保证你的数据是可信的,环境是隔离的。但是这个数据在磁盘里面是加密的,但是它被放在内存里面,就变成明文了,虽然我们有VT这样一种技术保证它的数据是隔离的,但是还是存在着被攻击的可能性。下一步技术叫SGX,它的攻击的可能性也没有了,因为在内存里面也是密文,一直到CPU里面进行计算的时候,才变成明文。

另外一个审计和定价的问题。系统安全了,数据安全了,使用安全了,我可能要进行一个审计。
定价,任何一个财产的定价,一个是根据效用,第二个是稀缺性。所谓效用就是你这个数据被使用的多频繁,他对结果的影响有多大,根据这样一种效果,我来判断各方数据的贡献,从而进行定价。稀缺性是根据数据价值的密度以及历史的价格的稀缺性进行定价。刚才的研究我们做了一个技术叫数据咖啡馆。咖啡馆是16世纪在英国出现的,它就是让三教九流不同的人能够聚在一起进行思想的碰撞,产生新的价值。数据咖啡馆就是希望能够让不同方的数据碰在一起,现在有很多垂直的电商,他们都是经营不同的业务。他们对于客户的认识是非常片面的,不精确的。比如说一家电商是卖衣服鞋帽的,另外一家是卖化妆品的,他们没有办法对一个客户获得像淘宝这样对个人精确的刻划。所以他们需要把精确的数据碰在一起,产生对客户全面的画像。在这里面还有不同的场景,比如说一个大电商,一个小电商,小电商肯定是缺乏数据的。他可以通过一种机器学习的方式来帮助这家小电商迅速的把他的对客户的认识建立起来。还有一种情况是这种小电商的数据比较少,标记数据比较少会出现机器学习中冷启动的问题,他可以利用另外一家电商的数据把他弄起来。

还有一个案例是癌症的。癌症是一个长尾病变,过去五十年癌症的治愈率只提升了8%,在所有的疑难杂症中是提升最少的,它的很大的原因是研究不同机构癌症的基因组样本非常的有限。如果说能够通过数据咖啡馆把这些数据汇聚到一起,我们一定能够加速癌症研究的技术突破。我们现在跟美国几家研究机构有一个愿景,在2020年前我们希望能够达到这样一个目标。在一天之内一个癌症患者来到医院能够完成全基因组测序,同时分析出致癌的基因,并且给出个性化的治疗方案。这有赖于疾病的治疗。这就是我们刚才说的,数据相逢但不相识。数据的价值一定是根据使用来决定的,没有使用不应该有数据的买卖,你先使用再定价再买卖。我们专门做了一个数据的定价机制。底层是多方安全技术。

在多方的架构里面,数据的提供方是不会让你的分析师看到数据的。不同的提供方也不会让另外一方看到数据。分析师的代码里面也有他的知识产权。他也不会让数据的提供方看到他的代码。这样形成了一种隔离,形成了相逢,但不必相识。这我认为是代表了这一领域的最前沿的研究。这个研究我们跟清华大学的贺飞老师有合作,他在形式化这一块有很好的工作。

第四,软硬兼施
就是软的硬的两手抓。

首先,对大数据来说,一定要选择更好的硬件架构。体现在:计算、存储、互联。在计算这一块,首先要选择的是大小核,Brawny cores是大核,主要是至强服务器芯片,wimpy cores是小核,主要是ARM服务器芯片。前几年大小核争得很厉害,但最近随着某些ARM服务器芯片厂商破产,大家都比较明白了,对于绝大多数大数据应用,大核肯定优于小核。大家可以关注一下两个人的论述,一个是Urs Holzle,谷歌基础设施的一把手,另一个是James Hamilton,亚马逊AWS的主要架构师。
第二,异构计算。首先是集成异构多核,英特尔有一类服务器芯片,在一个芯片上同时集成了CPU和GPU,现在百度在研究利用这类芯片做深度学习的可能性。第二类是GPGPU,单独的GPU的卡来做,比如大家都在用的深度学习框架Caffe就有针对GPGPU的优化。类似的,英特尔也有Xeon Phi,也就是世界排名第一超级计算机天河2号中用的芯片。目前来说,GPGPU和Phi都是插在PCIe插槽上的加速器,它们的加速性能都受到PCIe带宽的限制。明年Phi的新版本可以独立启动系统,因此PCIe的限制就不存在了,这对GPGPU是一种优势。另外,FPGA是现在用的比较多的一种方法,美国自然科学基金会最近的一个报告说对于深度学习,FPGA比GPGPU还更有效。还有一种是ASIP(ApplicationSpecific Instruction Processor),比如说NPU(Neural Processing Unit),现在很多神经网络的应用希望有专门的神经网络的芯片来做。
第三,大数据跟高性能计算的典型区别是在于,大数据是一个数据密集型的,数据是存在内存里面的。所以一个很重要的架构上的变化就是让内存跟处理器能够更加靠近。比如说利用eDRAM,使得处理器跟内存之间有更大的缓存。或者把内存和处理器堆叠起来,获得更大的带宽。或者把处理器反过来放到内存里面去,叫Computingin Memory。

对于存储而言,SSD到PCIe SSD到闪存存储,这一路的发展需要重构系统的软件栈。尤其是对于全闪存存储,文件系统可能不需要了,我可能直接让应用操作在闪存里面的数据。NVRAM是未来,因为数据不会丢失,所以像checkpointing这样的技术就不需要了。另外,数据静态保存和动态使用的状态统一了,所以不需要文件,不需要序列化和反序列化,整个系统栈会更浅更简单。
在互联上,节点和节点之间的互联已经到40Gbps,未来100Gbps甚至更高,现在最新的技术叫Silicon photonics(硅光),可以轻松上到几百个Gbps,基于硅光也好,高速以太网也好,为了发挥内存计算的效用,需要更便宜、更高扩展性的RDMA。

在选择了硬件架构之后,软件跟硬件架构需要做协同的优化。协同优化反映在几个方面:
第一,针对硬件的特点,对软件栈进行优化,这里又有不同的做法。
首先,我们要把硬件暴露给软件栈。大家现在玩Hadoop、Spark的话,都知道它们是跑在JVM上面的,你没有办法针对硬件的架构特征做优化。那你就需要通过一种方式来打破这个界限。比如英特尔尝试的NativeTask,把MapReduce里面排序的那部分通过Java Native Interface转到原生代码里做,针对系统缓存架构做优化,MapReduce的总体系统提升了30-50%。Spark最近创了Terasort的世界纪录,其中网络通讯这块也通过Java Native Interface转到原生的netty来做。还有,现在很多基于JAVA的大数据计算库,它都能够利用底层非常优化的线性代数原生库。
其次,重新设计软件栈,像刚才说过的全闪存存储和NVRAM。甚至硬盘现在也IP化、对象存储化,传统的软件栈需要重新设计。
还有一个场景是云化,Hadoop在云化,Spark也有了Databricks Cloud,但一旦云化了以后会带来很多的问题,比如Hadoop、HDFS他对于数据的本地性要求非常高,你一旦虚拟化了以后,数据在虚拟机中迁移,性能影响很大。所以VMWare贡献了HVE,Hadoop Virtual Extensions。云化另外要解决的问题是资源管理,YARN是第一步,但还有很多的研究问题没有解决。另外,把Hadoop和Spark置于Docker中运行是目前的一个热点。
所有这些都能够帮助大数据的软件站针对硬件来优化。
协同设计第二个大的方向是硬件可重构,尤其是英特尔现在推出的Rack Scale Architecture,你能够对一个机架进行重构,重构的基础是资源的池化和disaggregation。我可能是一个抽屉的全部是计算模块,一个抽屉全部是存储模块,一个抽屉是网络,一个抽屉是内存。我把资源池化。通过非常高速的硅光进行互联,可以把这些资源池重新进行划分,把它配置成针对不同应用需求的虚拟的服务器。这是一个非常重要的发展方向。在机架之上,是针对多数据中心的软件定义基础设施。
软硬件架构协同优化的典型体现是大学习系统。它是机器学习算法与底层系统更好的配合。我这里列出了比较有名的学习系统,VW,GraphLab,DistBelief,Project Adam,Petuum。其中VW和ProjectAdam跟微软研究院相关(VW最早在雅虎研究院开始),GraphLab和Petuum是源自英特尔支持的CMU云计算科研中心,DistBelief是谷歌的,他们的特点都是把机器学习的算法和底层架构做更好的协同优化。除了DistBelief,其他都有开源。

第五,多快好省
就是处理数据量多,更快,质量好,成本还省。


实现多快好省的方式,第一个是软硬件的协同设计,刚才说了。
下面说一下内存计算,它不是在技术栈的某一层的技术,在硬件平台层,要大内存,全闪存,用最新的NVRAM、用RDMA。
在数据管理和存储层,要有内存数据库,更好的内存缓存,要有堆外的内存,内存文件系统。
在计算处理层,要用新的内存计算的平台如Spark,或者在传统的数据库上面再堆一层内存计算的新层次,如In memory datagrids。
在数据分析和可视化层,你要重新设计数据结构。
这里面举了几个例子,分析,现在大数据的问题中有很大一部分是图问题,或者是复杂网络问题,这里面选了两个:GraphLab,一个是GraphChi,GraphChi把数据的结构进行了改变,使它能够流处理,最后在一台机器上能够达到十台、几十台集群能够达到的性能。这就是重新设计数据结构带来的好处。这个数据结构是不是能够支持可改性,也是很重要的。现在新的趋势就是在线的机器学习,就是你一边训练,一边做识别。这个过程中涉及到核心模型数据结构的可改变性,GraphChi就能够支持图结构的修改。另一个场景是可视化,Nanocube在16GB内存上能够对TB级的数据进行实时的处理,他采用了一种新的数据结构叫做in—memory data cube。所谓的原位(in-situ)分析和可视化,就是在内存原地进行分析和可视化,而无需做数据的转化和移动。

另外一种实现多快好省的方式就是降低空间和时间的复杂度。
降低空间复杂度就是把大数据变小。变小的方式有很多,比如说压缩(尤其是列式存储),又如缓存和多温度存储,把最重要的大数据找出来放在内存和闪存里面。又比如说采用稀疏的结构。亚马逊在做商品推荐的时候,用户以及他购买的商品矩阵是稀疏的,你通过稀疏的结构能够把空间复杂度下降。把大数据变小太重要了,最近Spark采取了一种Shuffle机制的改变,从基于hash的变成了基于sort的,极大地降低了内存使用,无论是terasort的世界纪录也好,还是在实际的应用场景,如大规模的广告分析logistics regression,都非常有用。
另外一种是时间复杂度降低。比如,使用简单的模型。在机器学习发展中有一度大家觉得复杂的模型更好。随着大数据时代的来临,研究发现用简单的模型就可以了,只要你数据量足够多。这里面有一篇典型的文章,谷歌PeterNorvig他们写的,大概意思是:数据有一种不可名状的魔力,使得一个非常简单的模型(用web文本处理为例是n-gram),大量的数据喂进去以后,针对机器翻译就有了一个很大的质的提升。而这种简单的模型往往它的计算复杂度是比较低的。
第二种是通过简单模型的组合。模型组合(ensemble)是一个机器学习的专业领域。我不想说的特别专业,我只给大家举一个例子,Netflix曾经举办过一个竞赛,你只要把我推荐有效性提升10%,我给你一百万美金。很多团队参加这个竞赛,但是每个团队都没有达到10%,后来团队与团队之间进行组合,最后达到了10%,拿到了一百万美金。IBMWatson事实上是一百多种模型的组合。如果每种模型是O(N2),它们的组合一定比一个O(N3)的复杂模型更快。
还有一种是采样和近似,采样是传统统计方法,但在大数据里面也有用武之地,比如BlinkDB,只要能够容忍百分之几的误差,它在TB级数据上能够实现秒级的延迟。近似也是类似,我用更简单的数据结构来做一些精确度要求不是那么高的判断。比如说在互联网中经常有一个计算叫UV。如果你用近似算法,复杂度一下子就能够下来了。
还有一个是降维和混合建模。数据在高维空间中、但数据点很稀疏,这也催生了一些降低复杂性的方法。比如混合建模,把适用于小数据规模的带参数模型与大数据规模的无参模型结合起来,先用后者在不同的低维空间建模,再由前者把这些模型综合起来,这种方法能够有效地解决稀疏性和计算量的问题。还有一种方法是针对高维数据进行降维,然后再对其施以更快的通用算法。所有这些方法能降低降低学习的复杂性。

关于多快好省我最后要讲的就是分布式和并行化。
典型的分布式优化是ACID到BASE的变化。ACID是传统的数据库里面要获得事务特性必须得做的。但是这个成本非常高。大家就改成了BASE,他只要最终是一致的。这也是蛮有意思的。ACID在英文里面是酸的意思,BASE英文里面是碱的意思,后者实现了并行的可能。
对于迭代计算,有两种方法,Jacobi方法和Gauss-Seidel方法。对于Gauss-Seidel方法,当前迭代可以使用最新的数据,因此收敛一般会快,但需要异步通信,实现复杂。对于Jacobi方法,当前迭代一定是基于上一个迭代的数据,问题是,一旦分布式了以后,上一个迭代的数据是分布在很多不同的节点上。如果说你要完全的获得新的数据的话,你就需要等待所有的节点算完,把这些新的数据拿过来。这是不利于分布式的优化的。因为很多机器学习算法能够容忍模糊性,他能够基于当前节点上过时的数据(而不是要等其他节点最新的数据)进行计算,打破迭代之间数据的依赖。这样使很多节点并行计算,最终他还是能够收敛。这里,谷歌采用了参数服务器的方式,CMU既有参数服务器,也有更通用的SSP,Stale Synchronous Parallel。
机器学习都会碰到几种并行,首先是数据并行,更复杂的是图并行,或者是模型的并行。模型的并行需要基于模型或图的机构做相应的数据划分、任务调度,原来比较火的是GraphLab,最近比较火的是Petuum,都是源自CMU。
总体来说,并行化和分布式的重点就是减少通讯,大家做系统,一定会碰到这些问题,一旦把一个系统分布式化,你要解决缓存的问题、一致性的问题、本地性的问题,划分的问题、调度的问题,同步的问题,同步有BSP的全同步,GraphLab的异步,或SSP的半同步。在状态更新时,可以批量进行更新,或者个别进行更新的问题。通讯是可以传输全部数据,也可以只传输改变的数据。有一个教授叫IonStoica,他有一篇论文,关于Bit Torrent,也就是现在大家下载电影常用的一个协议,他就是传输变量,在Spark中得到使用。

第六,天下三分


在最早的时候,人们都希望能够用一套架构把所有的问题处理。后面Michael Stonebraker提出我针对不同的计算需求提供不同的引擎,效果更好。所以,出现了数据和计算的分野。
现在主流的数据类型有几种:第一,表,或者是KV。第二种是数组或者是矩阵。第三种是图。他们可以用不同的计算范式处理。表格最适合的是关系的函数。数组和矩阵是以线性代数为代表的复杂的分析。图是需要图计算。
同样,我对计算范式也做了分类。
首先把大的计算范式分成了计算图和图计算。对于计算图,图上每一个节点是一个计算。先完成这个计算,再通过不同的边到下一个阶段的计算。它只有数据依赖,没有计算依赖。而图计算,图上的每一个节点是数据,边代表他们之间计算的依赖。
在计算图里面又分成两类,一类叫做批量的计算,他的典型特征是数据量太大了,数据不动,计算扔过来算。另一类是流式计算,是计算不动,数据恒动,计算分到每一个节点上,源源不断的数据流经这些节点,进行计算。
批量计算里面又分几类,一类是MapReduce,二阶段,BSP(比如Pregel)是三阶段,还有DAG(有向无环图)和多迭代计算,比如Spark、Tez。
流式计算里面也有不同类型,比如一次处理一个记录(record-at-a-time)还是mini-batch,Storm是前者,SparkStreaming是后者。不同的流式计算在容错上有不同实现,尤其是时钟语义和投递保证上。关于投递保证,假设我是一封信的话,最高的保证是一定能够到达接受者有且只有一次,而较低的保证是至少到达一次。另外,流式计算可以是做简单计算,比如基于时间窗的统计,或更复杂的流式在线学习。

编程模型这一块,有数据并行,有流式计算的任务并行,还有图并行。现在往往要求图结构支持关系操作,比如跟一张表来join,这是现在很多图计算编程模型新加入的。还有,最新出来一种概率编程模型,针对概率图的机器学习是更好的编程模型。
在大数据领域最近也在推事件驱动编程模型。一个非常火的范式叫reactive范式。最早在Erlang里,叫Actor模式,现在在Scala Akka语言里面,有更好的实现,他在针对异步的处理逻辑的时候,有更好的可扩展性。

第七,融合
既然分了,就有合。

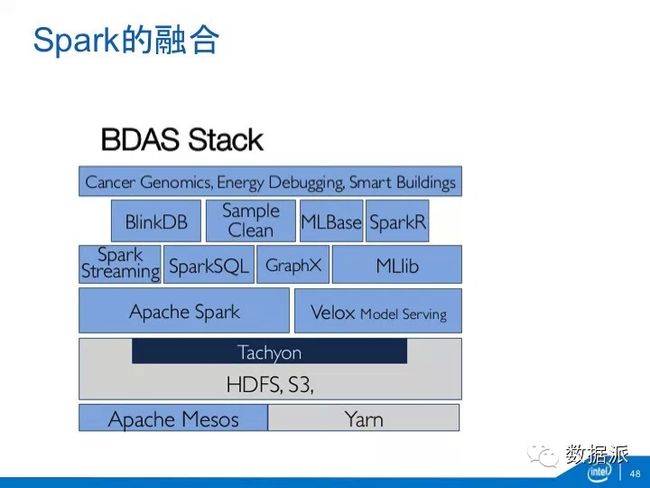

我拿Spark做为一个案例,它的BDAS软件栈底层是HDFS加上Tachyon内存文件系统,接着是Spark内存计算框架加上Velox的模型管理。在上面支持各种不同的计算范式,如Spark Streaming的流计算,SparkSQL的交互查询,GraphX的图计算,MLlib的机器学习等。由于SparkSQL的核心数据结构SchemaRDD起到基础性的作用,其他几个计算范式可能会建筑在SparkSQL之上。
有了这个BDAS以后,大家可以想像处理不同场景,比如说流查询,我把Spark Stremaing的流式和SparkSQL代表的数据仓库整合在一起;实时加上批量,SparkStreaming是实时,Spark本身是批量,实时加上历史数据分析获得全时洞察;Spark Streaming的流处理加上MLlib的机器学习,实现在线学习。又比如说图流水线,传统上先要对图数据进行处理,进行ETL,中间进行图计算,最后后处理。传统的图计算引起只能做中间这部分,前后还得靠MapReduce去做。而在Spark之上,可以一条流水线做完。最后,SparkSQL和MLlib可以有机结合,把交互分析和机器学习揉在一起。

在其他方面,融合也在发生:
比如数据管理和数据分析的融合,在传统的数据库中,有两类处理:一类叫做OLTP,做数据管理,一类叫做OLAP,做数据分析。两者基于不同的数据格式,之间需要ETL。现在的趋势是两者融合,在一套数据上计算。
MPP和Hadoop各有优势,现在也在融合。
就连高性能计算或超算也在跟大数据融合,前者原来是计算密集的,以模拟为核心的,现在也有很多数据密集的应用,重心也从模拟转移到数据分析,出现了high performance data analysis和data intensivesupercomputing等新的子领域。

第八,精益求精
提升分析的精确度。

很多传统机器学习的模型不可能支持更多的数据,当你加入更多数据的时候,这些模型已经没有办法提供更好分析的结果。在很多情况下,先前所说的简单模型加上更多数据不一定适合了。尤其是针对信息维度非常丰富的非结构化数据,图片、影音等等,需要更复杂的模型取代简单的模型,比如无参的、非线性的、生成性的模型。这些复杂模型在更多数据的时候有更好提升。现在最典型的复杂模型就是深度学习,上百亿参数、20多层的神经网络很常见。
另一种适合更多数据尤其是高维数据的方法是把不同模型混合起来。比如说参数模型比较适合小数据,无参模型比较适合大一点的数据,你可以在数据不同维度把它们混合起来。又比如说线性和非线性的混合。这样能够实现对更多数据的包容性。
数据多了,模型更复杂了,计算量疾速增大,所以优化算法的选择也很重要。在机器学习里面,数据是一方面,模型是一方面,算法又是一方面。传统是希望用非常复杂的算法找到最优的答案,现在我们认为用good enough的算法就好了。
所以,这些是对机器学习在更多数据下进一步提升边际收益的方法。
第二个问题,传统的机器学习不能覆盖数据的长尾特征。大数据一个跟传统数据分析的典型区别就是我要倾听每一个个体的声音,传统的机器学习往往基于指数分布的假设,指数分布是没有长尾的,他把个性化的声音当做低频噪声割掉。这样不能达到大数据分析的期望。所以在很多场景下,PCA、LDA、pLSA等等传统的基于指数假设的机器学习模型也许已经不适合了。改进的办法有很多,比如你需要根据数据的频率不同,进行不同的分级训练;或者通过模型的组合更好地发现数据里面隐藏的信号;更通用的办法是通过深度的神经网络或者概率图这些新的方式发现长尾。
提升精确度的方法,还有一个就是在线和流式的学习。我们传统的机器学习是离线的,训练归训练,识别归识别,他们是割裂的。你的模型可能是基于很久远的历史数据学习来的,这个模型并不能反应数据最新的变化。所以,最好是能够在线学习。通过增量的训练,通过模型的更新和新模型的快速部署,实现在线流式的学习。

第九,人机消长
人和机器在数据分析中角色的变化。


最早19世纪末的时候computer这个词指的是人,而现在完全变成了机器。人跟机器作用的变化,首先是原来机器不能做、人做的事情,现在机器都能做了。传统的数据分析是这样的,我先有一个假设,基于这个假设,我采集一些数据,建立一些模型,再去测试。现在大数据的场景下,数据是全集的,你不需要做一个特定的假设,相反,通过机械化的数据挖掘能够找到所有相关性来取代主观的假设。所以让数据能够自己找到数据,让相关性主动找到你。
传统意义上机器擅长做结构化的分析,不擅长做语义的分析,我们经常用《魔球》这样一部电影来说大数据的作用。它能够利用数据分析,用非常低的成本组建一支胜率非常高的棒球队。但是《魔球》没有公开说的是他们还是要用很高的成本请球的星探来分析个人的情况,比如说这个球员抗压能力、意志力怎么样。现在机器语义分析能力增强,能够取代人的作用。沃森这台机器主要的功能是延续了几十年的信息检索技术,但是他在前端加上了语义理解。他能够理解你问的问题是什么。
另一个方面,传统上的数据分析和可视化需要人有相当强的能力,数据科学家可以玩,但领域专家或终端用户小白玩不了。但是现在的发展趋势是机器取代人的专业能力。比如MLBase通过机器学习的方法帮助你找到最好的模型,VizDeck通过机器学习帮助你找到最好的可视化的方式。
人和机器作用变化的另一个方面是工具能够增强人的能力。工具变得更为人性化,让小白能够更好地从数据中提取价值。
这些年来进步最大的是可视化方面,因为最终的决策往往基于人对数据意义的理解。所以出现了很多可视化的工具、库和框架,能够对各类数据,包括文本、网络/图数据、时空数据和多维数据,轻松地可视化。同时,可视化要求变得更为交互,一次可视化呈现的不只是一种意义的理解,而同时又呈现了新的问题和探索方向,引导用户的下一个动作做另一种可视化的选择。所以,在可视化的界面隐喻、交互组件的设计上越来越人性化,实时地、自然地实现多侧面、多分辨率和多焦点的交互。
工具增强人还体现在社会化基础设施和大规模协作分析。比如云化就是把数据存储、计算能力社会化的做法。很多有数据思维的小公司,却不懂Hadoop、Spark、分布式计算、容错,那么他们可以利用云基础设施。Spark的商业化领导者Databricks最新提供了Databricks Cloud,把Spark的能力社会化了,降低了很多数据使用者的门槛。
如果说上述的只是在基础设施,分析能力这块也是可以社会化的,大规模协作分析是一个必然趋势。CrowdDB解决了前面所说的DB-hard的问题,通过人的众包对数据进行治理、规范化。Kaggle是个社会化分析平台,把数据问题和分析资源对接。如果说谷歌翻译是集中化的、权威数据主导的分析过程,Duolingo则是社会化的、民主化的、普通人主导的大规模协作分析过程,而达到的效果可能并不逊色。Duolingo是发明reCAPCHA(输入网站登录验证码的同时对数据数字化)的那个哥们发明的,用户在学习英语的过程也是对互联网翻译的过程,100万用户只需要学习80个小时就能把整个wikipedia从英语翻译成西班牙语。

特别值得提一下机器学习中人的作用的变化。
第一个是数据标记。传统的机器学习叫做监督学习,也就是说,根据一部分已经标记的数据做训练,获得模型。这个数据标记是人完成的,需要大量的人力,在机器学习界有个好的标记数据集是很难得的,像ImageNet,很多计算机视觉的研究都是基于它的。上面方面Duolingo的那个哥们还做过一个社会化协作分析项目叫ESP Game,让人们在玩游戏的过程中对图像打tag,甚至谷歌曾经都license过这个技术。
而机器学习的最新进展在弱化数据标记的作用。比如无监督学习,完全不用标记数据;半监督学习,只需要很少的标记数据,可以利用更多的非标记数据来学习;转移学习(transfer learning)可以用另一个领域的标记数据,弥补这个领域标记数据的不足;self-taught learning号称能使用任意的非标记数据,当然,这个还有待检验。
机器学习中第二个跟人相关的工作是特征工程。特征工程靠人的经验,一开始对特征的优化,提升很快,但是几个月以后它的边际效应就几乎趋向于零了,现在出现了更好的方法,通过机器的非监督学习,自己去学习特征。在深度学习里面,你可能一个模型是有几十亿、几百亿的参数。靠人肯定是没有办法做好的。现在一个新的做法就是通过Unsupervised的学习来自己做深度学习的特征学习。
最后一个跟人相关的是机器学习工具的易用性。现在越来越强调让非专业人士、领域专家做数据分析,因此机器学习中的很多繁琐之处必须标准化、工具化。现在出现了机器学习全流水线的框架设计,让非专业用户可以用简单的脚本语言和工具从头到尾完成数据分析,同时通过模型管理工具(如前面提到的Velox)对机器学习的迭代和生命周期进行管理。

第十,最后说一下智能之争

现在大家都说人工智能。它代表着生物智能和机器智能的一种博弈。这个光谱的一边是生物智能,生物智能擅长的模式匹配。人的认知过程是不停在做匹配、识别、联想,从记忆中提取数据。机器智能是通过计算,大量的计算是机器擅长的东西,比如统计学习。
因此,人工智能也分成了几个派别:
一个派别认为机器智能并不一定要学习人的生物构造,机器有机器的特点。他们经常引用的一个例子是,当莱特兄弟不试图模仿鸟类的翅膀的时候,他们开始研究空气动力学的时候,人类才有了飞上蓝天的机会。所以机器智能并不一定要学习生物智能,他可以通过更擅长的计算实现智能。这里有很多厉害人物,如统计学的大事MichaelJordan,老派的Peter Norvig,新派的邢波。
另一个派别认为我们必须要了解人脑是怎么工作的。通过各种各样的脑计划绘制出人脑的数据地图,了解我们的思维Mind是怎么工作的,然后我们把计算的架构往这上面去搬。这里有很多生物学家,有一些老派的科学家如侯世达(GEB作者)、彭罗斯(数学家,《皇帝的新脑》作者),有一些民科(如雷·库兹韦尔)。
现在主流的是第三个派别计算智能(computationalintelligence)。计算智能是上述两个派别之间的折中,它是认为可以用生物的认识作为约束和启发,但还是以计算为基础来实现智能,比如说人工神经网络、演化计算、模糊逻辑,人工免疫系统和群体智能等。人工免疫系统其实就是模仿人体内的分布式的免疫系统。不同地方的淋巴结能够识别入侵的病毒或者是细菌的特征,进行分布式的杀灭。现在主流的做神经网络、深度学习的科学家都是属于这一类。这里不得不提Palm Computer的创始人Jeff Hawkins,他虽然不是科班出身,但赞助和支持了很多有益的工作。

这些是现在正在热烈讨论的问题。
第一,深度学习有没有可能包打天下。在中间的这些人都认为深度学习能够把所有的问题都解决了。不但解决了计算机视觉的问题,又解决了语音识别的问题,现在又解决了自然语言处理的问题,百度甚至把它用来提升搜索质量、广告推荐的质量,都取得了一定的效果。但是质疑者是说深度学习没有一个理论基础,你没有机器学习算法的可解释性,都是一些莫名其妙的hacks。包括谷歌自己发现深度学习可能是存在一些deep flaws,比如两张图片人眼看起来是完全一模一样的,其中有一些细微的像素差别。但是深度学习只能认出一张,不能认出另外一张。为此,现在深度学习的大师们也在试图发展出一些理论,在计算理论、生物隐喻上。比如说GeoffHinton,他现在谷歌,他提出了胶囊理论(Capsules Theory),模仿人类大脑中的皮质柱,如果人的大脑皮质想象成是一个有6层细胞厚度的皮层,它是由一个个圆柱体构成的,他希望用这个隐喻来改进深度学习每一层完全非结构化的问题,把每一层的神经元进行分组、功能化。
第二个问题智能的未来是不是一定就是类脑计算?我个人对这个方向还是比较看好。现在希望通过两个角度得到提升。一个是通过脑计划绘制大脑的数字地图,通过对思维的研究、记忆的研究进一步了解人脑工作机制。另一方面是人工神经网络的不断改进,他的普适性在增强,也从生物神经网络获得了更多的启示。比如反馈,人脑从输入到处理的前向连接是后向连接(从处理到输入)的十分之一,也就是回路是前向连接的十倍之多。现在的人工神经网络还是往前的多,回路少。所以要更多的反馈。另外要把时间因素算进去。现在的很多人工神经网络不带有时间因素,人是不断的在学习,他看到的东西、想到的东西是有时间因素的,因此需要在线学习能力的提升。
第三,需不需要更新的类脑计算架构。大脑作为一台计算机,每天消耗20瓦,100多毫克的葡萄糖。但是要用计算机模拟大脑的神经网络规模,可能是几百万瓦。这样一个基于传统von neumann架构的神经网络,不仅识别率不如大脑,而且功耗要高很多。所以希望能够实现低功耗的具有识别、联想、推理能力的类脑的架构。当然,新的架构也有不同路线:一类是传统人工神经网络的加速器,如计算所的电脑、大电脑、普电脑,Yann LeCun的NeuFlow;另一类是更接近生物神经网络的处理器,如IBM的TrueNorth,高通的Zeroth。前者的识别精度高,但没有在线学习能力;后者目前精度低,但能够在线学习,也许未来有不错的前景。
所有这些是当前在智能之争上面讨论的问题。
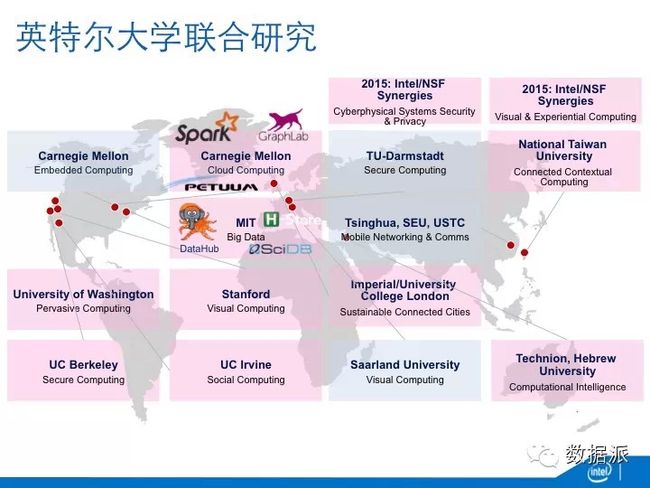
英特尔试图在十个前沿都有所涉猎,结合自己的研究和资助、跟踪大学的研究。这是我们在全球范围内跟大学的联合研究项目,在美国有七个研究中心,世界范围内有六家,包括有一个未来无线通讯网络,5G方面的研究中心是跟清华、东南大学和中科大一起的。图中带粉色底色的研究中心基本都跟大数据有关系,我们的这些研究单位都取得了很好的成绩。比如说在卡内基梅隆的云计算中心,最早Spark是该中心的项目之一(虽然研究主体在伯克利),GraphLab,Petuum都是这里出来的。在MIT的大数据中心领导者之一就是前面反复提到的Michael Stonebraker,这里很多工作围绕新一代的DBMS,如内存数据库H-Store,科学计算数据库SciDB,数据汇集、原位计算、可视化的DataHub等。在斯坦福的中心主要做可视化,领导的教授是Pat Hanrahan,他是Tableau的创始人之一。还有,以色列的计算智能中心,深度学习很强。这些中心的很多工作都已经开源。
我们主要希望能够通过这些协作研究,了解大数据发展的前沿。同时,也能够使得我们的架构更好的跟随大数据的算法和系统的发展。今天讲的就是这些。
