数据结构(一)线性存储结构
一、基本概念
- 线性结构作为最常用的数据结构,其特点是数据元素之间存在一对一的线性关系。
- 线性结构拥有两种不同的存储结构,即顺序存储结构和链式存储结构。顺序存储的线性表称为顺序表,顺序表中的存储元素是连续的,链式存储的线性表称为链表,链表中的存储元素不一定是连续的,元素节点中存放数据元素以及相邻元素的地址信息。
- 线性结构中存在两种操作受限的使用场景,即队列和栈。栈的操作只能在线性表的一端进行,就是我们常说的先进后出(FILO),队列的插入操作在线性表的一端进行而其他操作在线性表的另一端进行,先进先出(FIFO),由于线性结构存在两种存储结构,因 此队列和栈各存在两个实现方式。
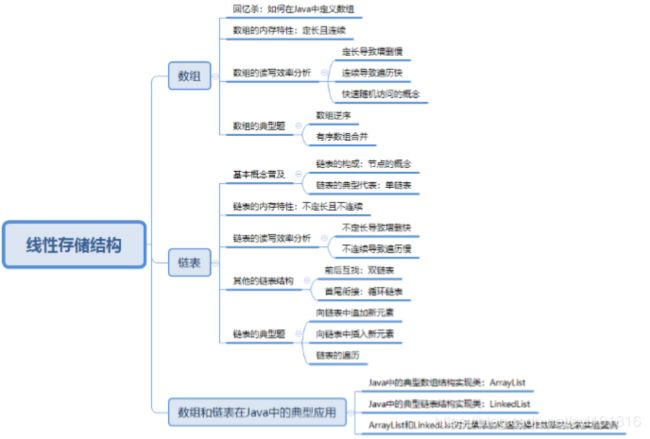
二、实现
2.1、数组
2.1.1 Java中的数组定义
int[] array = new int[] {0,1,2,3,4,5,6,7,8,9}; //数组的静态定义方式
int[] array = new int[10]; //数组的动态定义方式
- 在Java中定义数组的时候,数组的长度和内容只能够指定其中一个,不能即指定长度又指定内容,也不能不指定长度,也不指定内容;
- 声明数组类型的时候,我们推荐将数组元素类型和[]放在一起,将类似于int[]整体看做一个独立的数据类型;
- 在使用动态方式创建数组的时候,虚拟机在为数组开辟空间之后,这个数组中并不是“真空”的,而是使用元素默认值进行占位:
byte[]、short[]、int[]、long[]:默认值为0
float[]、double[]:默认值为0.0
boolean[]:默认值为false
char[]:默认值为Unicode值的0
引用数据类型数组,如String[]:默认值为null;
- 不管数组中存储的元素类型是基本数据类型的元素还是引用数据类型的元素,数组类型本身是一种引用数据类型
2.1.2 数组的内存特性
数组在内存中特性,我们可以使用一句话来进行概括:定长且连续。
- 定长指的是在Java中,一个数组对象在内存中一旦被创建,其长度将不能被修改;如果要修改一个数组的长度,那么只能重新new一个数组;
- 连续指的是在Java中,存在于同一个数组中的所有元素,其内存地址之间是连续有规律的
2.1.3 数组的读写
1、定长导致增删效率慢
- 数组一旦被创建,其长度是不可以被改变的,如果需要修改就要重新新建一个数组,在Java中创建对象是十分消耗时间和内存的一种操作,所以涉及到数组元素的插入和删除,必然会对数组对象的重新创建和数组元素的拷贝
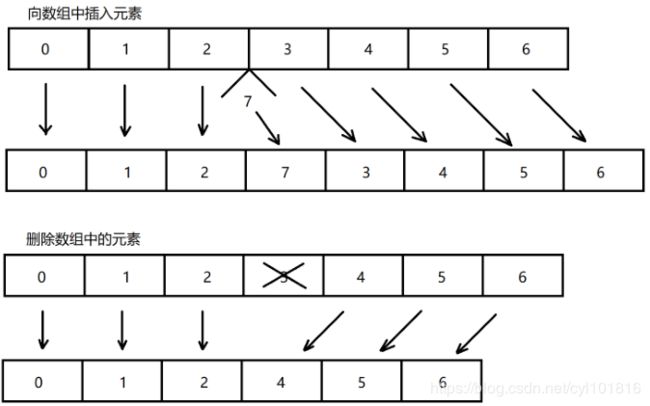
2、连续导致遍历效率快
- 在Java中,处于同一个数组中的元素之间的内存地址是有规律的,也就是说可以认为这些内存地址是连续存在的只要是连续存在的内存地址,那么我们就可以直接通过某种方式计算得到某一位元素的内存地址,进而访问这个数组元素。
也就是说,在通过下标访问数组中元素的时候,我们并不需要从数组的第一个元素开始,一个一个的向后查询这些元素,我们只要根据这些规律计算得到目标元素的内存地址就可以。
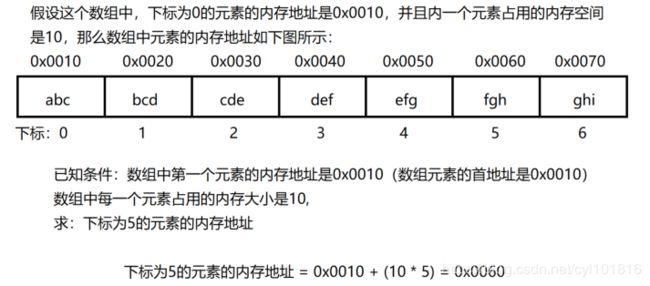
数组中下标为0的元素的内存地址就是这个数组在内存中的起始地址,也称之为数组的首元素地址,由此可见,通过公式计算元素的内存地址,比逐个遍历数组元素进行查找要快的多
3、可以快速随机访问
在按照下标访问数组中元素的时候,我们并不需要逐个遍历数组中的元素进行查找我们只需要按照数组元素首地址、单个数组元素大小和目标元素下标这三个参数直接套用公式,就能够计算得到目标元素的内存地址而其中,数组的首地址和数组中单个元素的内存大小都是在创建数组的时候就已经确定的,所以我们只要告诉虚拟机,我们要访问的数组元素下标就可以了。
公式:
- 数组目标元素内存地址 = 数组的首元素地址 + (数组元素占用内存大小 * 目标元素下标)
通过这种公式计算的方式得到数组元素内存地址的方式,称之为快速随机访问(QuickRandom Access)。
2.1.4 案例
1、数组逆序
//思路解析:
//使用两个变量i和j,分别指向数组的起点和终点,i变量向后走,j向前走
//在遍历数组的过程中将array[i]和array[j]中的元素值使用一个临时空间进行互换,循环条件为i2、数组合并
public class SortedArrayMerge {
public int[] sortedArrayMerge(int[] arr1, int[] arr2) {
//[1]创建一个新数组,作为结果数组,结果数组的长度是两个参数数组长度之和
int[] resultArray = new int[arr1.length + arr2.length];
//[2]分别创建两个变量,用来遍历两个数组
int i = 0; //变量i遍历arr1数组
int j = 0; //变量j遍历arr2数组
//[3]同时还得创建第三个变量,用来控制结果数组下标的变化
int k = 0; //变量k控制结果数组下标的变化
//[4]使用循环比较arr1[i]和arr2[j]之间的大小关系,将较小的一个元素落入结果数组中
while(i < arr1.length && j < arr2.length) { //循环结束条件是其中的某一个数组已经被遍历完成
//谁小谁就落在结果数组中,哪一个参数数组的元素落在结果数组中,哪一个参数数组的下标就向前进1
if(arr1[i] < arr2[j]) {
resultArray[k] = arr1[i];
i++;
}else {
resultArray[k] = arr2[j];
j++;
}
//但是不管是哪一个参数数组中的元素落入结果数组,结果数组的下标都要+1
k++;
}
//[5]为了防止其中一个数组已经遍历结束,另一个数组中还有剩余元素,将另一个数组中的剩余元素全部直接拷贝到结果数组中
if(i < arr1.length) { //arr1没有遍历完成
while(i < arr1.length) {
resultArray[k] = arr1[i];
i++;
k++;
}
}
if(j < arr2.length) { //arr2没有遍历完成
while(j < arr2.length) {
resultArray[k] = arr2[j];
j++;
k++;
}
}
//[6]返回结果数组
return resultArray;
}
public static void main(String[] args) {
int[] arr1 = new int[] {1,3,4,5,7};
int[] arr2 = new int[] {0,1,5,7,7,8,9};
SortedArrayMerge sam = new SortedArrayMerge();
int[] resultArray = sam.sortedArrayMerge(arr1, arr2);
System.out.println(Arrays.toString(resultArray));
}
}
2.2 链表
链表和数组不同,它的结构在内存中不是连续的。

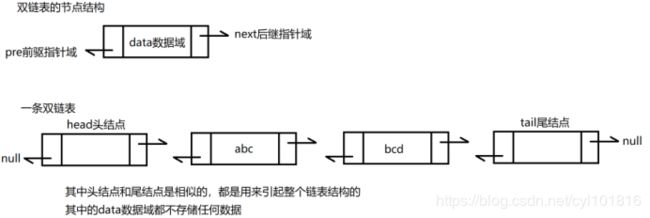
- 链表的节点一般分为两个部分:data数据域,用来存储要保存的数据,例如一个字符串、一个User对象等等;next后继指针域,用来保存下一个节点的内存地址,串起整个链表结构;
- 在链表中,链表的第一个节点通常不存储任何数据,他仅仅用来引起整个链表,我们将这个特殊的节点称之为数组的头结点
- 在整条链表中,我们只要知道了链表头结点的内存地址,就可以顺着之后每一个节点的next后继指针域向下,逐个找到后续的所有节点;
- 链表的最后一个节点的后继指针域取值为null,这一特性在遍历整个链表的时候,常用来判断是否还有后继节点。
链表节点的Java代码可以按照如下的格式进行声明:
class Node{
Object data;//数据域的定义,为了能够保存任意数据类型的数据,采用Object数据类
Node next;//后继指针域,因为一个节点的下一位还是一个节点,所以使用Node数据类
}2.2.1.1 单链表
单链表的每一个节点只有一个next后继指针域,所以在遍历这个链表的时候,只能够单向的从前向后进行遍历不能够从后向前进行遍历,所以这种链表结构称之为单链表。
2.2.1.2 双链表
如果我们在链表的节点中定义两个指针域,一个指向当前节点的下一个节点,一个指向当前节点的前一个节点那么我们就可以从前后两个方向来遍历这个链表,由此也就产生了双链表结构。
2.2.1.3 循环链表
如果一个链表的最后一个节点的后继指针域并不是指向null,而是回过头来直接指向第一个存储数据的节点那么这种结构就形成了环链表结构,也称之为循环链表循环链表结构在诸如磁盘模拟算法、解决约瑟夫环问题等场景下,有着大量的应用。
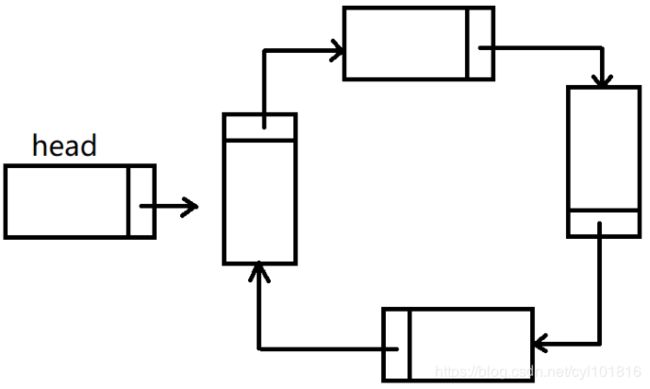
2.2.2 内存特性
链表的内存特性,正好和数组是相反的,一句话概括就是:不定长且不连续。
- 不定长:在内存中,链表的节点数量是动态分配的,一个链表结构中存在多少个节点,取决于我们向这个链表中添加了多少元素。如果我们想要向这个链表中追加元素或者插入元素,那么我们只要新建一个节点保存这个元素,并且改变几个引用值,就可以完成操作并不需要重建整个链表,更不需要拷贝原始链表中的任何元素
- 不连续:在每次添加新元素到链表中的时候,链表的节点都是重新new出来的。正如大家知道的,每次new出来的对象,即使数据类型是一样的,但是他们之间的内存地址也是互相没有关系的
即使是存储在同一个链表中的不同节点,他们之间的内存地址也是没有规律,不连续的这样一来,如果我们想要遍历链表中所有的节点,或者按照下标找到链表中的特定节点,那么不得不每一次都重新从链表的头结点出发一个一个的遍历节点,查找想要的元素。
2.2.3 链表的读写效率
1.不定长导致增删快
在同一个链表中插入元素的时候,是不需要重新创建一整条链表的,我们只要创建一个新节点并且改变原始链表中的一些后即指针的取值,就能够实现节点的添加操作;同理,从链表中删除节点也是一样的操作,都不涉及到整个链表的重新创建。
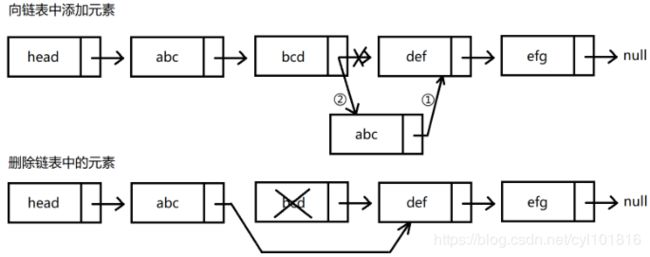
- 在向链表中添加节点和删除节点的时候,我们更多的是在操作节点的后继指针的取值,而并没有创建或者删除整个链表结构这样一来,和数组相比,我们就能够节省下来大量用于创建对象和拷贝原始数据的时间。所以,链表的不定长特性导致链表增删元素比较快。
2.不连续导致遍历慢
当一个链表需要存储一个新的元素的时候,都要重新new一个节点对象出来,而重新new出来的节点对象的内存地址和其他节点的内存地址之间是没有任何关系的。所以从这一点看来,如果我们想要按照下标对链表中的元素进行访问,类似于数组中的快速随机访问的公式就是不可用的了。所以我们在按照下标访问链表元素的时候,就不得不每一次都从链表的头结点开始,每向后遍历一个节点就记一次数,直到到达目标下标的节点为止。
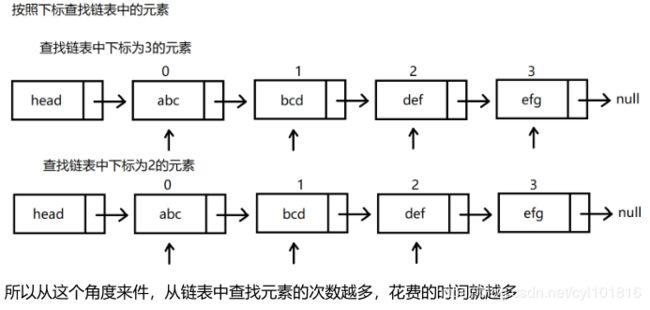
2.2.4 案例
1、向链表中追加新元素,插入新元素,遍历链表
public class MyLinked {
private static class Node {
public Object data; //数据域
public Node next; //后继指针域
}
//链表的头结点
private Node head = new Node();
//创建一个节点类型变量,用来指向链表的最后一个节点
private Node lastNode = head; //初始状态下,这个变量直接指向链表的头结点
//创建一个变量,用来记录当前链表中已经存在的节点数量
private int size = 0;
/**
* 向链表的结尾添加元素的方法
* @param data 加入链表的元素
*/
public void add(Object data) {
//[1]创建一个新节点,用来保存加入链表的数据
Node node = new Node();
node.data = data;
//[2]将新节点挂在最后一个节点的末尾
lastNode.next = node;
//[3]lastNode变量指向这个节点
lastNode = node;
//[4]节点数量+1
size++;
}
/**
* 向链表指定下标插入元素的方法
* @param index 指定的元素下标
* @param data 新的数据
*/
public void add(int index, Object data) {
//[1]首先判断下,用户指定插入的节点下标是不是超过了最大节点数量,如果是,那么直接使用追加的方式添加节点
if(index >= size) {
add(data);
return; //方法结束
}
//-----走到这一步,说明用户指定添加元素的下标,并没有超过最大元素数量,使用插入的方式将节点添加到链表中-----
//[2]使用一个新节点保存新元素
Node node = new Node();
node.data = data;
//[3]创建一个计步器变量,用来记录从链表头结点开始已经访问了多少个节点
int step = 0;
//[4]从链表的头结点开始,一个节点一个节点的向后查找并计步,直到找到插入为止之前的一个节点为止
Node current = head; //使用一个节点型变量,用来指示当前遍历到的节点
while(step < index) {
current = current.next; //遍历下一个节点
step++; //计步器自增
}
//[5]将新节点插入到指定的下标位上
node.next = current.next;
current.next = node;
size++;
}
/**
* 遍历链表的方法
*/
public void iterate() {
//[0]整个遍历的前提条件是链表中存在元素
if(size > 0) {
//[1]创建一个临时变量,用来标记当前正在遍历的节点
Node current = head.next; //最开始这个变量指向链表头的下一个节点,也就是真正保存数据的第一个节点
//[2]使用循环遍历整个数组,边遍历边打印
System.out.print("[");
while(current != null) {
System.out.print(current.data + " ");
current = current.next;
}
System.out.print("]");
}
}
public static void main(String[] args) {
MyLinked ml = new MyLinked();
ml.add("a");
ml.add("b");
ml.add("c");
ml.add("d");
ml.add("e");
ml.add(0, "f");
ml.add(2, "g");
ml.add(100, "h");
ml.iterate();
}
}
2.3 数组和链表在Java中的典型应用
在Java中,如果我们要在不同的应用场景下,使用数组或者链表的特性对数据进行存储和遍历,并不需要每一次都手动封装这些数据结构,因为在Java中已经将这些数据结构封装好了。
1、ArrayList ——数组的典型封装
2、LinkedList——链表的典型封装
详细的使用可以参考:https://blog.csdn.net/cyl101816/article/details/76851191