CIFAR-10 识别模型
1.首先要对数据集进行数据增强
深度学习通常会要求拥有充足数量的训练样本。一般来说,数据的总量越多, 训练得到的模型的效果就会越好。
在图像任务中,通常会观察到这样一种现象:对输入的图像进行一些简单的平移、缩放、颜色变换,并不会影响图像的类别。图2 -14 所示为翻转了位置的汽车图像,并适当降低了对比度和亮度,得到的图像当然还是汽车。它们都可以被用作是汽车的训练样本。
对于图像类型的训练、数据,所谓的数据增强( Data Augmentation )方法是指利用平移、缩放、颜色等变换,人工增大训练、集样本的个数3 从而获得更充足的训练数据,使模型训练的效果更好。

常用的数据增强方法如下:
- 平移:将图像在一定尺度范围内平移。
- 旋转·将图像在一定角度范围内旋转。
- 翻转:水平翻转或上下翻转图像。
- 裁剪:在原有图像上裁剪出一块。
- 缩放:将图像在一定尺度内放大或缩小。
- 颜色变换:对图像的RGB 颜色空间进行一些变换。
噪声扰动:给国像加入一些人工生成的躁声。
使用数据增强方法的前提是,这些数据增强方法不会改变图像的原有标签。例如在MNIST 数据集中,如果使用数据增强,就不能使用旋转180° 的方法,因为标签为“ 6 ”的数字在旋转180° 后会变成“ 9 ”。
TensorFlow 中数据增强的实现
训练CIFAR-10 识别模型用到了数据增强来提高模型的性能。实验证明,使用数据增强可以大大提高模型的泛化能力,并且能够预防过拟合。
实现数据增强的代码如下:
# 随机裁剪图片,从32x32裁剪到24x24
distorted_image = tf.random_crop(reshaped_image, [height, width, 3])
# 随机翻转图片。每张图片有50%的概率被水平左右翻转,另有50%的概率保持不变
distorted_image = tf.image.random_flip_left_right(distorted_image)
# 随机改变亮度和对比度
distorted_image = tf.image.random_brightness(distorted_image,
max_delta=63)
distorted_image = tf.image.random_contrast(distorted_image,
lower=0.2, upper=1.8)原始的训练图片是reshaped_image 。最后会得到一个数据增强后的训练样本distorted image 。从reshaped_image 到distorted_image 的处理步骤如下:
- 第一步是对reshaped_image进行随机裁剪。原始的CIFAR-10 图像的尺寸是32 × 32 。随机裁剪出24 × 24 的小块进行训练。因为小块可以取在图像的任何位置,所以仅此一步就可以大大增加训练、集的样本数目。
- 第二步是对裁剪后的小块进行水平翻转。每张图片有50%的概率被水平翻转,还高50%的概率保持不变。
- 最后对得到的图片进行亮度和对比度的随机改变。
训练时,直接使用distorted_image 进行训练即可。
2.CIFAR-10 识别模型
与MNIST 识别模型一样,得到数据增强后的图像distorted_image 后,需要建立一个模型将图像识别出来。代码如下:
# 函数的输入参数为images,即图像的Tensor
# 输出的是图像各个类别的Logit
def inference(images):
# We instantiate all variables using tf.get_variable() instead of
# tf.Variable() in order to share variables across multiple GPU training runs.
# If we only ran this model on a single GPU, we could simplify this function
# by replacing all instances of tf.get_variable() with tf.Variable().
#
# 建立第一层卷积
with tf.variable_scope('conv1') as scope:
kernel = _variable_with_weight_decay('weights',
shape=[5, 5, 3, 64],
stddev=5e-2,
wd=0.0)
conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME')
biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.0))
pre_activation = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(pre_activation, name=scope.name)
# summary是将输出报告到TensorBoard,很快会学到TensorBoard的应用
_activation_summary(conv1)
# 第一卷积层的池化
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='SAME', name='pool1')
# 这是局部响应归一化层(LRN),现在的模型大多不采用
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,
name='norm1')
# 第二层卷积层
with tf.variable_scope('conv2') as scope:
kernel = _variable_with_weight_decay('weights',
shape=[5, 5, 64, 64],
stddev=5e-2,
wd=0.0)
conv = tf.nn.conv2d(norm1, kernel, [1, 1, 1, 1], padding='SAME')
biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.1))
pre_activation = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(pre_activation, name=scope.name)
_activation_summary(conv2)
# 局部响应归一化
norm2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,
name='norm2')
# 第二层卷积层的池化
pool2 = tf.nn.max_pool(norm2, ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1], padding='SAME', name='pool2')
# 全连接层1
with tf.variable_scope('local3') as scope:
# 后面不再做卷积了,所以把pool2进行reshape,方便做全连接
reshape = tf.reshape(pool2, [FLAGS.batch_size, -1])
dim = reshape.get_shape()[1].value
weights = _variable_with_weight_decay('weights', shape=[dim, 384],
stddev=0.04, wd=0.004)
biases = _variable_on_cpu('biases', [384], tf.constant_initializer(0.1))
# 全连接。输出relu(wx+b)
local3 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name=scope.name)
_activation_summary(local3)
# 全连接2
with tf.variable_scope('local4') as scope:
weights = _variable_with_weight_decay('weights', shape=[384, 192],
stddev=0.04, wd=0.004)
biases = _variable_on_cpu('biases', [192], tf.constant_initializer(0.1))
local4 = tf.nn.relu(tf.matmul(local3, weights) + biases, name=scope.name)
_activation_summary(local4)
# linear layer(WX + b),
# We don't apply softmax here because
# tf.nn.sparse_softmax_cross_entropy_with_logits accepts the unscaled logits
# and performs the softmax internally for efficiency.
# 全连接 + Softmax分类
# 这里不显示进行Softmax变换,只输出变换前的Logit(即变量softmax_linear)
with tf.variable_scope('softmax_linear') as scope:
weights = _variable_with_weight_decay('weights', [192, NUM_CLASSES],
stddev=1/192.0, wd=0.0)
biases = _variable_on_cpu('biases', [NUM_CLASSES],
tf.constant_initializer(0.0))
softmax_linear = tf.add(tf.matmul(local4, weights), biases, name=scope.name)
_activation_summary(softmax_linear)
return softmax_linear模型代码虽然比较复杂,但本质不变,与手写体数字识别模型类似,都是输入图像,输入图像对应到各个类别的Logit。这里使用了两层卷积层,还在卷积层后面额外加了三层全连接层。
3.训练模型
用下列命令就可以训练模型:
python cifar10_train.py --train_dir cifar10_train/ --data_dir cifar10-data/–data_dir cifar10-data/的含义是指定cifar-10数据的保存位置。–train_dir cifar10_train/的作用是另外指定训练文件夹。训练文件夹的作用是保存模型的参数和训练日志信息。训练模型师,屏幕上会显示日志信息。
2018-07-20 11:24:55.600781: step 580, loss = 3.06 (101.0 examples/sec; 1.268 sec/batch)
2018-07-20 11:25:08.951224: step 590, loss = 2.94 (95.9 examples/sec; 1.335 sec/batch)
2018-07-20 11:25:22.078509: step 600, loss = 2.88 (97.5 examples/sec; 1.313 sec/batch)
2018-07-20 11:25:34.666919: step 610, loss = 3.23 (101.7 examples/sec; 1.259 sec/batch)
2018-07-20 11:25:47.301855: step 620, loss = 2.82 (101.3 examples/sec; 1.263 sec/batch)
2018-07-20 11:26:00.164454: step 630, loss = 2.84 (99.5 examples/sec; 1.286 sec/batch)
2018-07-20 11:26:13.360787: step 640, loss = 3.06 (97.0 examples/sec; 1.320 sec/batch)日志信息告诉我们当前时间和已训练的步数,还会显示当前的损失是多少(如loss=3.98)。理想的损失应该是一直下降的。日志里最后括号里的信息表示训练速度。智力的日志信息是在CPU下训练时输出的,如果使用GPU进行训练,那么训练速度会快很多。
在TensorFlow中查看训练进度
在训练的时候,常常想知道损失的变化,以及各层的训练状况。TensorFlow 提供了一个可视化工具TensorBoard 。使用TensorBoard 可以非常方便地观察损失的变化曲线,还可以观察训练速度等其他日志信息达到实时监控训练过程的目的。
要使用TensorBoard, 请打开另一个命令行窗口,切换到当前目录, 并输入以下命令·
tensorboard --logdir cifar10_train/TensorBoard默认在6006端口进行。打开浏览器,输入地址http://127.0.0.1:6006(或者http://localhost:6006),就可以看到TensorBoard的主页面,如下图所示

单击total_loss_1,就可以看到loss的变化曲线,变化曲线会根据时间实时变动,非常便于实时监测。还可以华东左侧工具栏中的“Smoothing”滑动条,它的功能是平滑损失曲线,方便更好的观察损失曲线的整体变化情况
单击learning_rate,可以监控学习率的变化。观察学习率时,应当把“Smoothing”滑条拖曳至0,因为学习率是确定的,并不存在噪声,因此也不需要平滑处理。
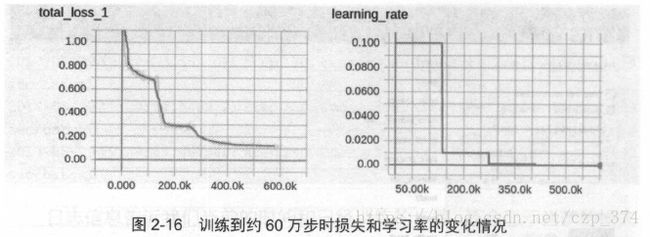
从上图可以看出,在深度模型的训练当中,通常使用比较大的学习率(如0.1),这样可以帮助模型在初期以比较快的速度收敛。之后再逐步降低学习率(如降低至0.01或0.001)。在CIFAR-10识别模型的训练中,学习率从0.1开始递减,依次是0.0、0.001、0.0001。每次递减否可以让损失更进一步地下降。
除了上述功能外,在TensorBoard 中还可以监控模型的训练速度。展开global_ step 选项卡,对应的图形为每秒训练步数的情况。如图2 -17 所示,每秒大概训练8~ 11 步, 变化不是特别大。在实际训练过程中,如果训练速度发生较大的变化,或者出现训练速度随程序运行而越来越慢的情形,就可能是程序中出现了错误,需要进行检查。

最后,简要介绍TensorBoard显示训练信息的原理。在指定的训练文件夹cifar10_train 下,可以找到一个以events.out 开头的文件。实际上,在训练模型时,程序会源源不断地将日志信息写入这个文件中。运行TensorBoard时只要指定训练、文件夹,TensorBoard 会自动搜索到这个文件, 井在网页中显示相应的信息。