Hive默认的执行引擎是Hadoop提供的MapReduce,而MapReduce的缺点是读写磁盘太多,为了提高Hive执行某些SQL的效率,有必要将Hive的执行引擎替换为Spark,这就是Hive On Spark。不过Hive On Spark的环境搭建的确是有点麻烦,主要是因为Hive和Spark的版本不能随意搭配,首先Spark必须是without-hive版本才可以(编译时用特殊命令申明排除掉某些jar包)。要拥有这样的Spark的版本,你可以自己编译,但是要自己编译还得做很多准备工作,也是较为麻烦和费时的。其次拥有了without-hive版本的Spark,还得选择合适的Hive版本才可以,也就是说Hive和Spark必须使用恰当的版本,才能搭建Hive On Spark环境。
在之前的几篇文章描述了hadoop、hbase以及hive的安装配置,本篇注意介绍如何通过spark连接Hive读写数据。由于Hive对spark版本有着严格要求,具体对应版本可以下载hive源码里面,搜索pom.xml文件里面的spark版本,如果版本不对,启动hive后会报错。具体错误如下:
Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create spark client.)' FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.spark.SparkTask这里的hive 2.3.2里对应的spark版本如下图所示: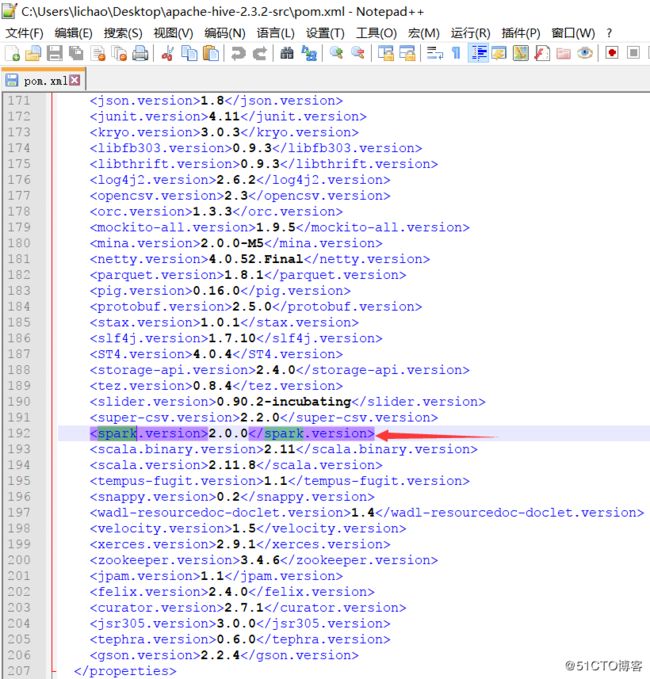
用到的软件版本如下表所示:
| 名称 | 版本 | 下载地址 |
|---|---|---|
| Hadoop | 2.9.0 | download |
| Hbase | 1.2.6 | download |
| Hive | 2.3.2 | download |
| spark | 2.0.0 | download |
| scala | 2.11.8 | spark自带 (download) |
一、Spark安装配置
1、Hive配置
默认情况下,Hive的execution engine为mr,需要修改为spark。编辑hive-site.xml文件:
hive.execution.engine
spark
Expects one of [mr, tez, spark].
Chooses execution engine. Options are: mr (Map reduce, default), tez, spark. While MR
remains the default engine for historical reasons, it is itself a historical engine
and is deprecated in Hive 2 line. It may be removed without further warning.
另外,需要修改hive二进制程序,加入以下内容,否则会出现如下报错:
Exception in thread "main" java.lang.NoClassDefFoundError: scala/collection/Iterablehadoop@bdi:~$ vi $HIVE_HOME/bin/hive
CLASSPATH=${CLASSPATH}:${HIVE_LIB}/*.jar
for f in ${HIVE_LIB}/*.jar; do
CLASSPATH=${CLASSPATH}:$f;
done
--新加的内容
for f in ${SPARK_HOME}/jars/*.jar; do
CLASSPATH=${CLASSPATH}:$f;
done2、spark安装
hadoop@bdi:~$ wget https://www.apache.org/dyn/closer.lua/spark/spark-2.0.0/spark-2.0.0-bin-hadoop2.7.tgz
hadoop@bdi:~$ cd /u01
hadoop@bdi:/u01$ tar -xzf /home/hadoop//spark-2.0.0-bin-hadoop2.7.tgz
hadoop@bdi:/u01$ mv spark-2.0.0 spark
编辑环境变量,加入以下内容
hadoop@bdi:~$ vi .bashrc
export SPARK_HOME=/u01/spark
export CLASSPATH=$CLASSPATH:$SPARK_HOME/jars/*
export PATH=$PATH:$HIVE_HOME/bin:$SPARK_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/sbin创建spark配置文件:
hadoop@bdi:/u01/spark/conf$ cp spark-defaults.conf.template spark-env.sh
hadoop@bdi:/u01/spark/conf$ vi spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_152
export SCALA_HOME=/u01/scala
export HADOOP_HOME=/u01/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_LAUNCH_WITH_SCALA=0
export SPARK_WORKER_MEMORY=4g
export SPARK_DRIVER_MEMORY=4g
export SPARK_MASTER_IP=192.168.120.95
export SPARK_MASTER_WEBUI_PORT=18080
export SPARK_WORKER_DIR=/u01/spark/work
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_PORT=7078
export SPARK_LOG_DIR=/u01/spark/log
export SPARK_PID_DIR='/u01/spark/run'
export SPARK_DIST_CLASSPATH=$(/u01/hadoop/bin/hadoop classpath)
export HIVE_HOME=/u01/hive
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop:$HIVE_HOME/conf
export HIVE_CONF_DIR=/u01/hive/conf复制mysql的jdbc驱动到spark的jars目录(1.x版本前是lib目录):
hadoop@bdi:~$ cp /u01/hive/lib/mysql-connector-java-5.1.44-bin.jar /u01/spark/jars为了让Spark能够访问Hive,需要把Hive的配置文件hive-site.xml拷贝到$SPARK_HOME/conf:
hadoop@bdi:~$ cp /u01/hive/conf/hive-site.xml /u01/spark/conf/启动spark的master服务:
hadoop@bdi:~$ $SPARK_HOME/sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /u01/spark/log/spark-hadoop-org.apache.spark.deploy.master.Master-1-bdi.out
master的端口是7077,如下:
hadoop@bdi:~$ netstat -antpl|grep 7077
tcp 0 0 192.168.120.95:54654 192.168.120.95:7077 TIME_WAIT -
tcp6 0 0 192.168.120.95:7077 :::* LISTEN 19696/java
停止用以下命令:
hadoop@bdi:~$ $SPARK_HOME/sbin/stop-master.sh
stopping org.apache.spark.deploy.master.Master启动master时会一并启动MasterUI服务,端口为18080,如图所示: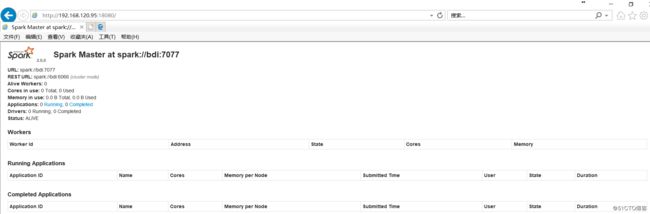
验证spark是否支持hive: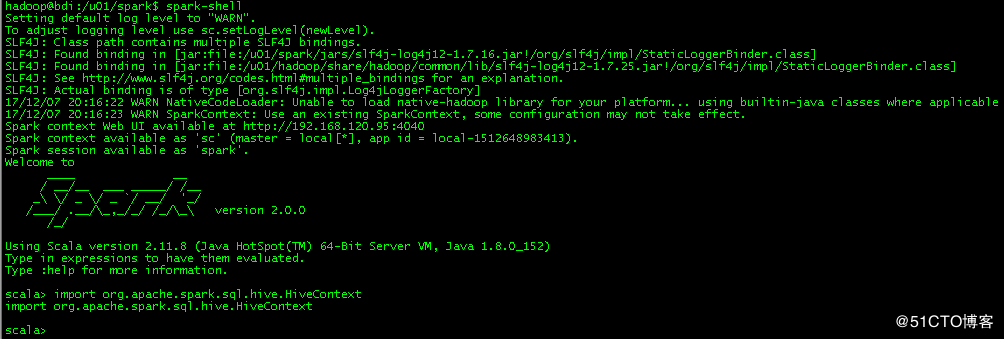
如果出现以下报错,则说明当前spark不支持hive:
scala> import org.apache.spark.sql.hive.HiveContext
:25: error: object hive is not a member of package org.apache.spark.sql
import org.apache.spark.sql.hive.HiveContext
^ 运行spark-shell命令:
到此,spark已安装成功,可以使用。
二、连接Hive读写数据
在操作之前,确保启动了Hadoop、Hive、MySQL和spark-shell。
1、spark读数据
scala> import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.hive.HiveContext
scala> val hiveCtx = new HiveContext(sc)
hiveCtx: org.apache.spark.sql.hive.HiveContext = org.apache.spark.sql.hive.HiveContext@74bcff71
scala> val userinfoRDD = hiveCtx.sql("select id,name,gender,age from hivedb.userinfo").rdd
userinfoRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[17] at rdd at :28
scala> userinfoRDD.foreach(t => println("Name:"+t(1)+",Gender:"+t(2)+",Age:"+t(3)))
Name:jason,Gender:M,Age:20
Name:candon123,Gender:F,Age:23 如上,已成功读取。
2、spark写数据
当前的userinfo上有2条数据,如下:
hive> use hivedb;
OK
Time taken: 5.977 seconds
hive> select *from userinfo;
OK
1 candon123 F 23
1 jason M 20
Time taken: 0.379 seconds, Fetched: 2 row(s)
hive> 执行以下命令,向userinfo插入2条数据:
scala> import org.apache.spark.sql.{SQLContext, Row}
scala> import org.apache.spark.sql.types.{StringType, IntegerType, StructField, StructType}
scala> import org.apache.spark.sql.hive.HiveContext
scala> import hiveContext.implicits._
//下面我们设置两条数据表示两个用户信息
scala> val hiveCtx = new HiveContext(sc)
scala> val userinfoRDD = sc.parallelize(Array("3 michal M 26","4 ChengCheng M 27")).map(_.split(" "))
//下面要设置模式信息
scala> val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age", IntegerType, true)))
//下面创建Row对象,每个Row对象都是rowRDD中的一行
scala> val rowRDD = userinfoRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt))
//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
scala> val userinfoDataFrame = hiveCtx.createDataFrame(rowRDD, schema)
//下面注册临时表
scala> userinfoDataFrame.registerTempTable("tempTable")
//把临时表中的数据插入到Hive数据库中的hivedb.userinfo表
scala> hiveCtx.sql("insert into hivedb.userinfo select * from tempTable")Hive中进行查询验证: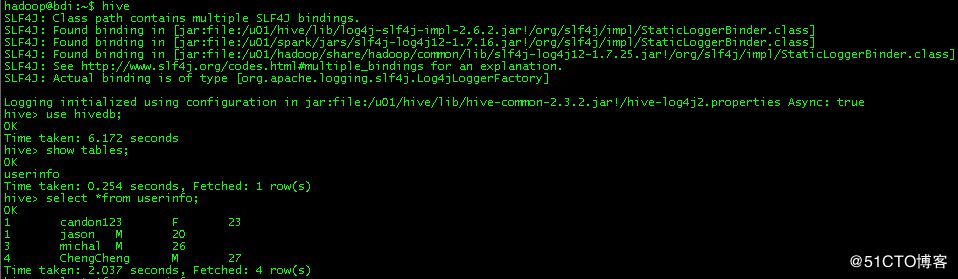
参考文献:
1、Linux搭建Hive On Spark环境
2、Spark入门:连接Hive读写数据