利用python进行数据分析----- 第一天,准备工作。DataFrame,Series,Matplotlib
目录
工具
创建变量
删除变量
获取数据
下载地址:
引入文件:
转换为json:
解析数据
单个对象输出
获取所有时区
引入自定义函数
使用函数:
获取数量前十的时区,倒序:
使用pandas对时区进行计数
获取数量前十的时区:
替代填补缺失值:
绘制水平条形图
解析Agent字符串
构建间接索引进行统计
生成条形堆积图
比例分布
有问题留言,互助
工具
进行数据处理分析有很多公具,精通一种即可,本实验只要使用pycharm.
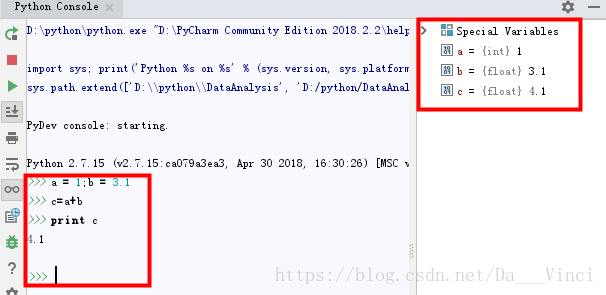
创建变量
打开pycharm,新建项目,点击python console进入交互式窗口
重叠的箭头可以输入指令,special variables是已经创建的变量。
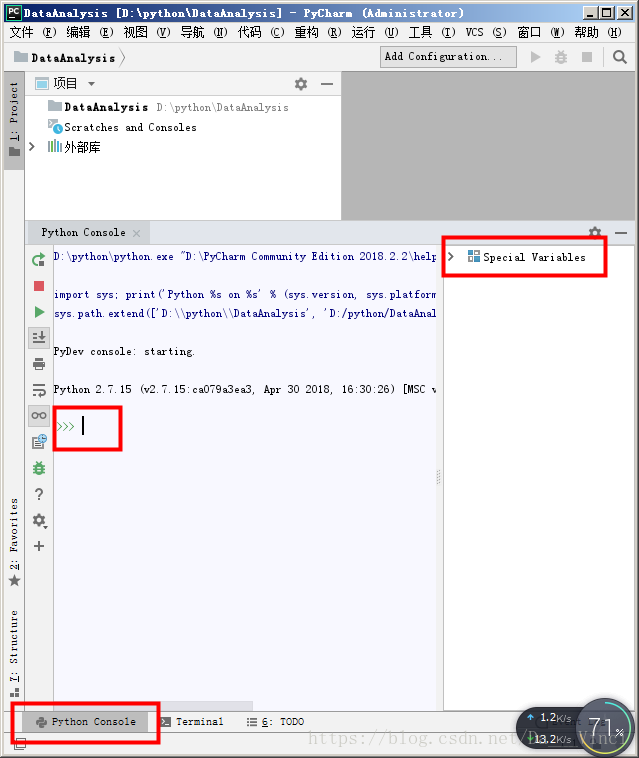
每当输入一行数据,按一下回车键,就会执行该语句,也相当于程序在一句一句的执行写好的代码。右边的special variables可以看到user创建的变量,包含了变量的类型
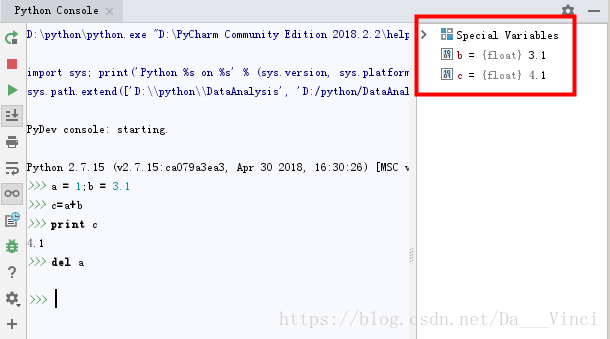
删除变量
获取数据
下载地址:
http://1usagov.measuredvoice.com/2013/
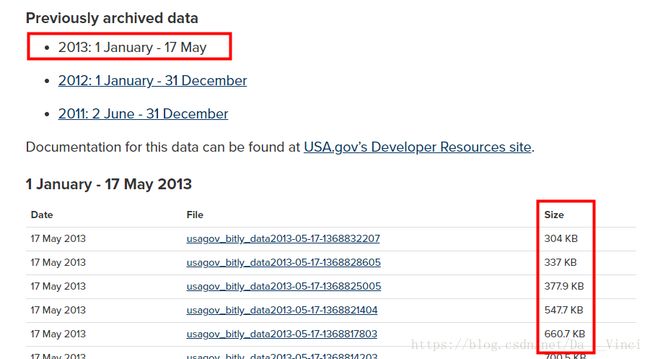
下载后为压缩文件,加压后将后缀改为txt,或json,便于处理。顺便名字也改一下。

引入文件:
path:代表文件路径的字符串,open(路径)文件加载函数,readline(),打印open函数读取到的第一行数据。
>>> path = 'data/data1.txt'
>>> open(path).readline()
'{ "a": "Mozilla\\/5.0 (Linux; U; Android 4.1.2; en-us; HTC_PN071 Build\\/JZO54K) AppleWebKit\\/534.30 (KHTML, like Gecko) Version\\/4.0 Mobile Safari\\/534.30", "c": "US", "nk": 0, "tz": "America\\/Los_Angeles", "gr": "CA", "g": "15r91", "h": "10OBm3W", "l": "pontifier", "al": "en-US", "hh": "j.mp", "r": "direct", "u": "http:\\/\\/www.nsa.gov\\/", "t": 1368832205, "hc": 1365701422, "cy": "Anaheim", "ll": [ 33.816101, -117.979401 ] }\n'
转换为json:
import:导入包指令。
records=[?],创建名称为recoeds的数组
json.loads(?) 将参数转化为json数据
for line in open(path) 打开制定路径文件,for语句循环赋值给line
最后将line逐个写入records.
records[0] 输出索引为0的数组元素
>>> import json
>>> records = [json.loads(line) for line in open(path)]
>>> records[0]
{u'a': u'Mozilla/5.0 (Linux; U; Android 4.1.2; en-us; HTC_PN071 Build/JZO54K) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30', u'c': u'US', u'nk': 0, u'tz': u'America/Los_Angeles', u'gr': u'CA', u'g': u'15r91', u'h': u'10OBm3W', u'cy': u'Anaheim', u'l': u'pontifier', u'al': u'en-US', u'hh': u'j.mp', u'r': u'direct', u'u': u'http://www.nsa.gov/', u't': 1368832205, u'hc': 1365701422, u'll': [33.816101, -117.979401]}

解析数据
单个对象输出
>>> records[0]['tz']
u'America/Los_Angeles'获取所有时区
if ‘tz’ in rec : 判断rec数组是否存在tz属性
>>> time_zone = [rec['tz'] for rec in records if 'tz' in rec]
引入自定义函数
count是一个字典,x和count[x]组成一个键值对
def get_counts(sequence):
counts = {}
for x in sequence:
if x in counts:
counts[x] +=1
else:
counts[x] = 1
return counts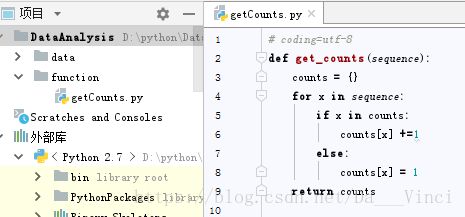
在系统中引入路径即可使用自定义函数
>>> sys.path.append('D:\\python\\DataAnalysis\\function')
>>> from getCounts import get_counts使用函数:
>>> counts = get_counts(time_zone)
>>> print counts
{u'': 636, u'Europe/Lisbon': 8, u'America/Bogota': 16, u'America/Edmonton': 9, u'Australia/Tasmania': 1, u'Europe/Tallinn': 1, u'Asia/Calcutta': 6, u'Australia/South': 4, u'Europe/Skopje': 1, u'Europe/Copenhagen': 4, u'America/St_Lucia': 1, u'Europe/Amsterdam': 15, u'Europe/Zaporozhye': 1, u'America/Phoenix': 40, u'Europe/Moscow': 35, u'America/El_Salvador': 2, u'Europe/Madrid': 21, u'America/Argentina/Buenos_Aires': 11, u'America/Mazatlan': 2, u'America/Rainy_River': 33, u'Europe/Paris': 27, u'Europe/Stockholm': 4, u'America/Monterrey': 4, u'Europe/Athens': 1, u'America/Indianapolis': 50, u'America/Regina': 3, u'America/Mexico_City': 22, u'America/Puerto_Rico': 184, u'Asia/Manila': 4, u'Europe/Sarajevo': 1, u'Europe/Berlin': 24, u'Europe/Zurich': 5, u'Africa/Casablanca': 1, u'Asia/Karachi': 1, u'Europe/Rome': 19, u'Asia/Harbin': 4, u'Australia/West': 9, u'Asia/Kuching': 1, u'Europe/Warsaw': 2, u'Europe/Jersey': 1, u'Australia/Canberra': 7, u'Pacific/Honolulu': 12, u'America/St_Johns': 1, u'Europe/Oslo': 3, u'Asia/Hong_Kong': 5, u'America/Guadeloupe': 1, u'America/Nassau': 1, u'Europe/Prague': 1, u'Australia/NSW': 32, u'America/Halifax': 7, u'America/Jamaica': 1, u'Asia/Singapore': 4, u'America/Manaus': 2, u'America/Los_Angeles': 421, u'Asia/Amman': 1, u'Europe/Bratislava': 3, u'America/Vancouver': 23, u'Atlantic/Reykjavik': 1, u'Asia/Novokuznetsk': 1, u'America/Sao_Paulo': 29, u'America/Port_of_Spain': 1, u'Asia/Tokyo': 102, u'Asia/Jakarta': 4, u'Africa/Johannesburg': 2, u'Europe/Riga': 1, u'Chile/Continental': 16, u'Asia/Taipei': 1, u'Asia/Istanbul': 5, u'Australia/Victoria': 23, u'Europe/Bucharest': 3, u'Asia/Bangkok': 3, u'Africa/Ceuta': 6, u'America/Costa_Rica': 6, u'America/Winnipeg': 4, u'America/Chicago': 686, u'America/La_Paz': 4, u'Africa/Cairo': 3, u'Europe/Brussels': 14, u'Asia/Dubai': 1, u'Asia/Jerusalem': 1, u'Pacific/Auckland': 9, u'America/Argentina/Cordoba': 2, u'America/Caracas': 13, u'America/Panama': 2, u'America/Guayaquil': 4, u'Asia/Kuala_Lumpur': 3, u'America/Denver': 89, u'Asia/Riyadh': 5, u'Europe/Ljubljana': 1, u'Asia/Vladivostok': 1, u'Asia/Phnom_Penh': 1, u'Africa/Gaborone': 1, u'Europe/London': 85, u'America/Montevideo': 3, u'America/Managua': 3, u'Asia/Qatar': 1, u'Asia/Pontianak': 1, u'America/Tijuana': 1, u'America/Argentina/Catamarca': 1, u'Australia/Queensland': 10, u'America/Santo_Domingo': 4, u'Europe/Samara': 2, u'Asia/Yekaterinburg': 2, u'America/Asuncion': 1, u'Europe/Vienna': 6, u'America/New_York': 903, u'Europe/Dublin': 9, u'Europe/Sofia': 1, u'America/Montreal': 8, u'America/Anchorage': 8, u'Asia/Seoul': 3}
获取数量前十的时区,倒序:
sort()排序函数,详细说明见http://www.runoob.com/python/att-list-sort.html
# coding=utf-8
def top_counts(count_dict,n):
value_key_pairs = [(count,tz) for tz,count in count_dict.items()]
value_key_pairs.sort()
return value_key_pairs[-n:]>>> from topCounts import top_counts
>>> top_counts(counts,10)
[(40, u'America/Phoenix'), (50, u'America/Indianapolis'), (85, u'Europe/London'), (89, u'America/Denver'), (102, u'Asia/Tokyo'), (184, u'America/Puerto_Rico'), (421, u'America/Los_Angeles'), (636, u''), (686, u'America/Chicago'), (903, u'America/New_York')]
使用pandas对时区进行计数
DataFrame函数将数据表示为一个表格。
>>> from pandas import DataFrame,Series
>>> import pandas as pd;import numpy as np
>>> frame = DataFrame(records)
>>> frame
_heartbeat_ ... u
0 NaN ... http://www.nsa.gov/
1 NaN ... http://answers.usa.gov/system/selfservice.cont...
2 NaN ... http://www.saj.usace.army.mil/Media/NewsReleas...
3 NaN ... https://nationalregistry.fmcsa.dot.gov/
4 NaN ... http://www.peacecorps.gov/learn/howvol/ab530gr...
5 NaN ... https://petitions.whitehouse.gov/petition/repe...
6 NaN ... http://pld.dpi.wi.gov/files/pld/images/LinkWI.png
7 NaN ... http://www.nasa.gov/multimedia/imagegallery/im...
8 NaN ... http://www.nsa.gov/
9 NaN ... http://www.nasa.gov/mission_pages/sunearth/new...
10 NaN ... http://www.dodlive.mil/index.php/2013/05/the-2...
11 NaN ... http://doggett.house.gov/index.php/news/571-do...
12 NaN ... http://www.peacecorps.gov/learn/howvol/ab530gr...
13 NaN ... http://www.fws.gov/cno/press/release.cfm?rid=493
14 NaN ... http://www.cancer.gov/PublishedContent/Images/...
15 NaN ... http://www.army.mil/article/103380/
16 NaN ... http://pld.dpi.wi.gov/files/pld/images/LinkWI.png
17 NaN ... http://www.nws.noaa.gov/com/weatherreadynation...
18 NaN ... http://fastlane.dot.gov/2013/05/new-locomotive...
19 NaN ... http://apod.nasa.gov/apod/ap130517.html
20 NaN ... http://www.ice.gov/news/releases/1305/130516sa...
21 NaN ... http://www.dodlive.mil/index.php/2013/05/the-2...
22 NaN ... http://pld.dpi.wi.gov/files/pld/images/LinkWI.png
23 NaN ... http://doggett.house.gov/index.php/news/571-do...
24 NaN ... http://pld.dpi.wi.gov/files/pld/images/LinkWI.png
25 NaN ... http://answers.usa.gov/system/selfservice.cont...
26 NaN ... http://answers.usa.gov/system/selfservice.cont...
27 NaN ... http://answers.usa.gov/system/selfservice.cont...
28 NaN ... http://answers.usa.gov/system/selfservice.cont...
29 NaN ... http://answers.usa.gov/system/selfservice.cont...
... ... ...
3929 NaN ... http://www.nasa.gov/mission_pages/station/expe...
3930 NaN ... http://gsaauctions.gov/gsaauctions/aucdsclnk?s...
3931 NaN ... http://gsaauctions.gov/gsaauctions/aucdsclnk?s...
3932 NaN ... http://www.nsa.gov/
3933 NaN ... http://science.nasa.gov/science-news/science-a...
3934 NaN ... http://www.nsa.gov/
3935 NaN ... http://cms3.tucsonaz.gov/files/police/media-re...
3936 NaN ... http://www.irs.gov/uac/Newsroom/Tax-Relief-for...
3937 NaN ... http://www.jpl.nasa.gov/news/news.php?release=...
3938 NaN ... http://www.jpl.nasa.gov/news/news.php?release=...
3939 NaN ... http://www.doe.gov/articles/energy-department-...
3940 NaN ... http://www.nsa.gov/
3941 NaN ... http://pld.dpi.wi.gov/files/pld/images/LinkWI.png
3942 NaN ... http://fwp.mt.gov/hunting/hunterAccess/openFie...
3943 NaN ... http://science.nasa.gov/media/medialibrary/201...
3944 NaN ... http://gsaauctions.gov/gsaauctions/aucdsclnk?s...
3945 NaN ... http://inws.wrh.noaa.gov/weather/alertinfo/103...
3946 NaN ... http://pld.dpi.wi.gov/files/pld/images/LinkWI.png
3947 NaN ... http://doggett.house.gov/index.php/news/571-do...
3948 NaN ... http://www.nasa.gov/mission_pages/mer/news/mer...
3949 NaN ... http://fastlane.dot.gov/2013/05/new-locomotive...
3950 NaN ... http://studentaid.ed.gov/repay-loans/understan...
3951 NaN ... http://doggett.house.gov/index.php/news/571-do...
3952 NaN ... http://doggett.house.gov/index.php/news/571-do...
3953 1.368836e+09 ... NaN
3954 NaN ... http://inws.wrh.noaa.gov/weather/alertinfo/103...
3955 NaN ... http://pld.dpi.wi.gov/files/pld/images/LinkWI.png
3956 NaN ... http://www.doe.gov/articles/energy-department-...
3957 NaN ... http://www.jpl.nasa.gov/news/news.php?release=...
3958 NaN ... http://science.nasa.gov/media/medialibrary/201...
[3959 rows x 18 columns]>>> frame['tz'][:10]
0 America/Los_Angeles
1
2 America/Phoenix
3 America/Chicago
4
5 America/Indianapolis
6 America/Chicago
7
8 Australia/NSW
9
Name: tz, dtype: object
获取数量前十的时区:
value_counts() 统计元素个数
>>> tz_counts = frame['tz'].value_counts()
>>> tz_counts[:10]
America/New_York 903
America/Chicago 686
636
America/Los_Angeles 421
America/Puerto_Rico 184
Asia/Tokyo 102
America/Denver 89
Europe/London 85
America/Indianapolis 50
America/Phoenix 40
Name: tz, dtype: int64
替代填补缺失值:
如果frame['tz‘]不存在,则填充为missing,frame['tz']是个空白字符串,表示没有获取到用户信息
>>> clean_tz = frame['tz'].fillna('missing')
>>> clean_tz[clean_tz == ''] = 'Unknow'
>>> tz_count = clean_tz.value_counts()
>>> tz_count[:10]
America/New_York 903
America/Chicago 686
Unknow 636
America/Los_Angeles 421
America/Puerto_Rico 184
missing 120
Asia/Tokyo 102
America/Denver 89
Europe/London 85
America/Indianapolis 50
Name: tz, dtype: int64绘制水平条形图
matplotlib详细用法见其他博文 https://blog.csdn.net/u013084616/article/details/79064408
>>> tz_count[:10].plot(kind='barh',rot=0)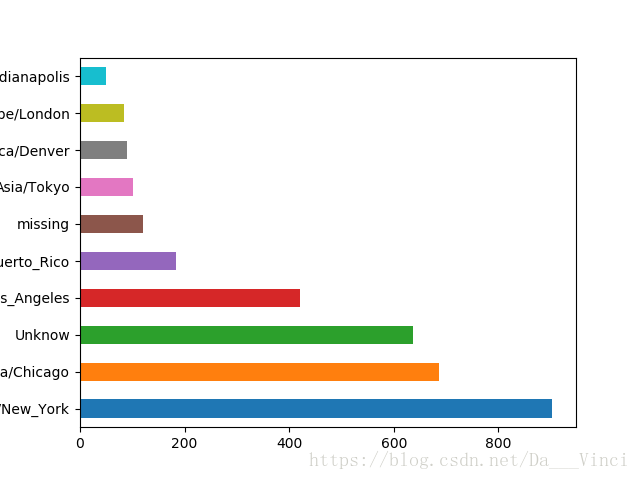
解析Agent字符串
for循环取出frame中的a列数据,通过空格符分隔并获取分隔后的第一个字符串
>>> result = Series(x.split()[0] for x in frame.a.dropna())
>>> result[:5]
0 Mozilla/5.0
1 Mozilla/4.0
2 Mozilla/5.0
3 Mozilla/5.0
4 Opera/9.80
dtype: object如果包含 windows 字符,就分为windiws组,反之Not Windows
>>> cframe = frame[frame.a.notnull()]
>>> operating_system = np.where(cframe['a'].str.contains('Windows'),'Windows','Not Windiws')
>>> operating_system[:10]
array(['Not Windiws', 'Windows', 'Windows', 'Not Windiws', 'Not Windiws',
'Windows', 'Windows', 'Not Windiws', 'Not Windiws', 'Windows'],
dtype='|S11')unstack()用于对计算结果进行重塑
>>> by_tz_os = cframe.groupby(['tz',operating_system])
>>> agg_counts = by_tz_os.size().unstack().fillna(0)
>>> agg_counts[:10]
Not Windiws Windows
tz
484.0 152.0
Africa/Cairo 0.0 3.0
Africa/Casablanca 0.0 1.0
Africa/Ceuta 4.0 2.0
Africa/Gaborone 0.0 1.0
Africa/Johannesburg 2.0 0.0
America/Anchorage 5.0 3.0
America/Argentina/Buenos_Aires 4.0 7.0
America/Argentina/Catamarca 1.0 0.0
America/Argentina/Cordoba 0.0 2.0构建间接索引进行统计
>>> indexer = agg_counts.sum(1).argsort()
>>> indexer[:10]
tz
55
Africa/Cairo 101
Africa/Casablanca 100
Africa/Ceuta 36
Africa/Gaborone 97
Africa/Johannesburg 42
America/Anchorage 43
America/Argentina/Buenos_Aires 44
America/Argentina/Catamarca 47
America/Argentina/Cordoba 50
dtype: int64
>>> count_subset = agg_counts.take(indexer)[-10:]
>>> count_subset
Not Windiws Windows
tz
America/Phoenix 22.0 18.0
America/Indianapolis 29.0 21.0
Europe/London 62.0 23.0
America/Denver 41.0 48.0
Asia/Tokyo 88.0 14.0
America/Puerto_Rico 93.0 91.0
America/Los_Angeles 207.0 214.0
484.0 152.0
America/Chicago 343.0 343.0
America/New_York 550.0 353.0生成条形堆积图
>>> count_subset.plot(kind = 'barh',stacked = True)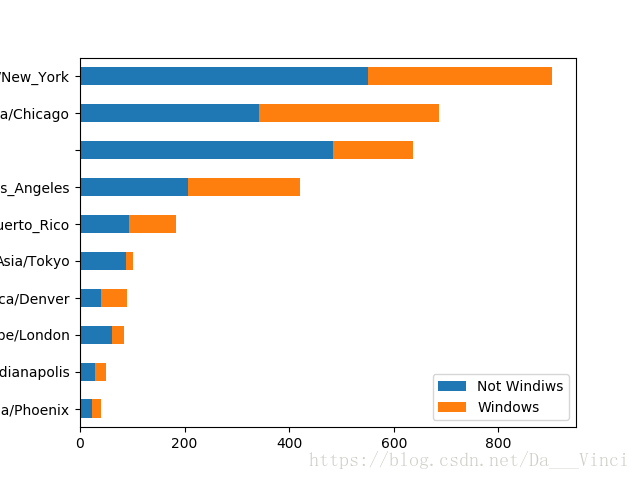
比例分布
>>> normed_subset = count_subset.div(count_subset.sum(1),axis=0)
>>> normed_subset.plot(kind='barh',stacked = True)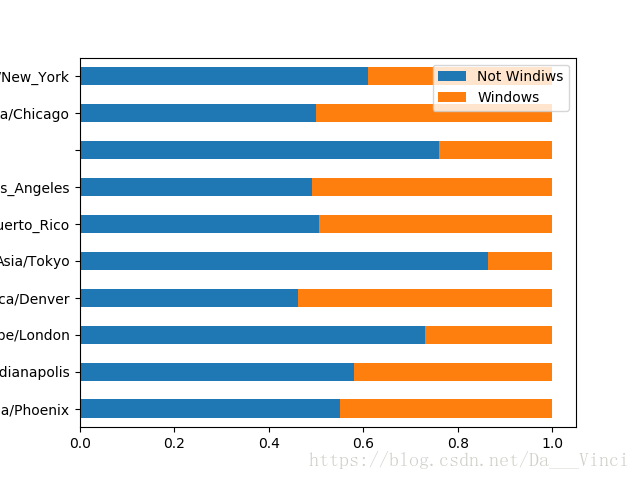
有问题留言,互助