Spark运行环境之SparkEnv和通信工具RpcEnv
Spark在运行时Driver端和Executor端需要互相通信,那么这种通信是如何进行的?
在SparkEnv中有两个方法createDriverEnv,createExecutorEnv,分别用于创建Driver端和Executor端的SparkEnv对象。
看一下SparkEnv对象的结构,从下面的代码中可以看到SparkEnv包含了Spark中很多重要组件,比如用于通信的RpcEnv,用于序列化的SerializerManager,还包括ShuffleManager、BroadcastManager、BlockManager,MemoryManager等用于管理Shuffle,broadcast,block和memory的组件。
class SparkEnv (
val executorId: String,
private[spark] val rpcEnv: RpcEnv,
val serializer: Serializer,
val closureSerializer: Serializer,
val serializerManager: SerializerManager,
val mapOutputTracker: MapOutputTracker,
val shuffleManager: ShuffleManager,
val broadcastManager: BroadcastManager,
val blockManager: BlockManager,
val securityManager: SecurityManager,
val metricsSystem: MetricsSystem,
val memoryManager: MemoryManager,
val outputCommitCoordinator: OutputCommitCoordinator,
val conf: SparkConf)
接下来的文章中主要从Driver端和Executor端两个角度的源码来分析SparkEnv对象的生成过程,以及其中的RpcEnv是如何实现Driver端和Executor端通信的。
在此之前,插入一个题外话,原生的Spark代码中,由于SparkEnv的限制会使得同一JVM中无法共存多个SparkContext,如果不解决SparkEnv上的限制的话,会由于Driver端和Executor端Broadcast等组件的不匹配导致SparkContext环境异常。原因如下所示,SparkEnv的伴生对象中有一个SparkEnv类型的对象,当Driver端或者Executor端构建SparkEnv时,会SparkEnv.set该对象,然后在多个地方直接通过SparkEnv.get方法来获取该对象。如果存在多个SparkContext,那么后面创建的SparkContext触发的SparkEnv.set操作会将之前的env覆盖。当执行任务时就会出现SparkEnv中各组件不匹配了。
object SparkEnv extends Logging {
@volatile private var env: SparkEnv = _
...
def set(e: SparkEnv) {
env = e
}
/**
* Returns the SparkEnv.
*/
def get: SparkEnv = {
env
}
...
}
一、SparkEnv的创建
1、调用栈分析
(1)Driver端
Driver端创建SparkEnv对象是在SparkContext中进行的,调用栈如下,
SparkContext#createSparkEnv
----> SparkEnv.createDriverEnv
--------> SparkEnv.create
(2)Executor端
Executor端创建SparkEnv对象的过程是,
CoarseGrainedExecutorBackend#run
----> SparkEnv.createExecutorEnv
--------> SparkEnv.create
Executor启动过程
Spark在启动时,将Executor端的启动命令通过Yarn分发到各节点,然后在本地启动CoarseGrainedExecutorBackend进程,这部分的逻辑可以参考,
CoarseGrainedExecutorBackend的入口是其main方法,使用方法如下Usage: CoarseGrainedExecutorBackend [options] Options are: --driver-url--executor-id --hostname --cores --app-id --worker-url --user-class-path 启动命令在
ExecutorRunnable#prepareCommand中生成,这个方法的调用是由ExecutorRunnable#startContainer触发的,从方法名看,这个是启动Executor节点的地方。val commands = prefixEnv ++ Seq( YarnSparkHadoopUtil.expandEnvironment(Environment.JAVA_HOME) + "/bin/java", "-server") ++ javaOpts ++ Seq("org.apache.spark.executor.CoarseGrainedExecutorBackend", "--driver-url", masterAddress, "--executor-id", executorId, "--hostname", hostname, "--cores", executorCores.toString, "--app-id", appId) ++ userClassPath ++ Seq( s"1>${ApplicationConstants.LOG_DIR_EXPANSION_VAR}/stdout", s"2>${ApplicationConstants.LOG_DIR_EXPANSION_VAR}/stderr")上面就是在各个节点上启动Executor服务的命令,可以在机器上看到以下形式的java进程
184629 CoarseGrainedExecutorBackend --driver-url spark://[email protected]:3990 --executor-id 93 --hostname hostname --cores 4 --app-id application_1530195947232_7897078 --user-class-path file:/data1/nodemanager/usercache/master/appcache/application_1530195947232_7897078/container_e33_1530195947232_7897078_01_000159/__app__.jar再看一下Executor启动时是如何获取到Driver端的
SparkConf配置的。SparkConf对象在创建SparkEnv时会用到。val executorConf = new SparkConf val port = executorConf.getInt("spark.executor.port", 0) // 创建一个RpcEnv,从Driver请求 val fetcher = RpcEnv.create( "driverPropsFetcher", hostname, port, executorConf, new SecurityManager(executorConf), clientMode = true) val driver = fetcher.setupEndpointRefByURI(driverUrl) val cfg = driver.askWithRetry[SparkAppConfig](RetrieveSparkAppConfig) val props = cfg.sparkProperties ++ Seq[(String, String)](("spark.app.id", appId)) fetcher.shutdown() // 新建一个SparkConf对象,将Rpc获取的参数都赋给该对象 val driverConf = new SparkConf() for ((key, value) <- props) { // this is required for SSL in standalone mode if (SparkConf.isExecutorStartupConf(key)) { driverConf.setIfMissing(key, value) } else { driverConf.set(key, value) } }
Executor启动时就会通过CoarseGrainedExecutorBackend#run方法生成SparkEnv对象。所以上面要先分析Executor的启动过程。
Driver端生成SparkEnv的过程可以直接查看SparkContext中的逻辑,这个过程比较简单。
2、SparkEnv#create
上面Driver端和Executor端的调用栈,最终都是进入到了同一个方法SparkEnv#create方法中。只要搞清楚了这个方法的逻辑,也就知道了Driver端和Executor端是如何构建SparkEnv对象的了。
源代码如下,只保留其中的关键逻辑。
/* Driver端调用该方法时传入的参数如下:
* executorId: driver
* bindAddress: spark.driver.bindAddress参数指定,默认与spark.driver.host参数相同,取driver主机名
* advertiseAddress: spark.driver.host参数指定,默认取driver主机名
*
* Executor端调用该方法时传入的参数如下:
* conf: driverConf 从driver端获取的SparkConf对象
* executorId: Executor启动时的编号,例如--executor-id 93
* bindAddress: Executor所在主机名,例如--hostname hostname
* advertiseAddress: 和bindAddress相同
*/
private def create(
conf: SparkConf,
executorId: String,
bindAddress: String,
advertiseAddress: String,
port: Int,
isLocal: Boolean,
numUsableCores: Int,
ioEncryptionKey: Option[Array[Byte]],
listenerBus: LiveListenerBus = null,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
// 判断是不是driver端,driver端的识别符号是“driver”
val isDriver = executorId == SparkContext.DRIVER_IDENTIFIER
// 根据是否driver,生成不同的systemName用于构建rpcEnv对象,driver端为"sparkDriver",executor端为"sparkExecutor"
val systemName = if (isDriver) driverSystemName else executorSystemName
// 创建RpcEnv对象,下一节中详细分析
val rpcEnv = RpcEnv.create(systemName, bindAddress, advertiseAddress, port, conf, securityManager, clientMode = !isDriver)
val serializer = ...
val serializerManager = ...
val closureSerializer = ...
val broadcastManager = ...
val mapOutputTracker = ...
val shuffleManager = ...
val useLegacyMemoryManager = ...
val memoryManager: MemoryManager = ...
val blockManagerPort = ...
val blockTransferService = ...
val blockManager = ...
val metricsSystem = ...
val outputCommitCoordinator = ...
val outputCommitCoordinatorRef = ...
val envInstance = new SparkEnv(
executorId,
rpcEnv,
serializer,
closureSerializer,
serializerManager,
mapOutputTracker,
shuffleManager,
broadcastManager,
blockManager,
securityManager,
metricsSystem,
memoryManager,
outputCommitCoordinator,
conf)
envInstance
}
二、RpcEnv测试
接下来首先做一个小测试,通过spark-core提供的功能,模拟测试Rpc通信的过程。
1、构建后端服务
首先需要有一个长时间运行的后端服务,服务端完整代码如下所示,首先通过RpcEnv.create方法构造一个RpcEnv对象,然后通过RpcEnv.setupEndpoint方法向该对象中set一个自定义的HelloworldEndpoint,该类需要继承自RpcEndpoint。在RpcEndpoint中有一些方法可以覆盖实现,比如onStart可以增加一些服务启动时的逻辑功能,onStop可以增加一些服务停止时的功能,receiveAndReply可以处理客户端发送过来的请求。
object HelloworldServer {
def main(args: Array[String]) {
// 初始化RpcEnv环境
val conf = new SparkConf
val rpcEnv: RpcEnv = RpcEnv.create("hello-server", "localhost", 52345, conf, new SecurityManager(conf))
// 当前RpcEnv设置后端服务
val helloEndpoint: RpcEndpoint = new HelloEndpoint(rpcEnv)
rpcEnv.setupEndpoint("hello-service", helloEndpoint)
// 等待客户端访问该后端服务
rpcEnv.awaitTermination()
}
}
class HelloEndpoint(override val rpcEnv: RpcEnv) extends RpcEndpoint {
override def onStart(): Unit = {
println("start hello endpoint")
}
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case SayHi(msg) => {
println(s"receive $msg")
context.reply(s"hi, $msg")
}
case SayBye(msg) => {
println(s"receive $msg")
context.reply(s"bye, $msg")
}
}
override def onStop(): Unit = {
println("stop hello endpoint")
}
}
case class SayHi(msg: String)
case class SayBye(msg: String)
运行效果如下图所示,

2、构建前端请求
后端服务稳定运行后,我们如何访问该服务,接下来看一下客户端的代码,
object HelloworldClient {
def main(args: Array[String]) {
// 初始化RpcEnv环境
val conf = new SparkConf
// 这里的rpc环境主机需要指定本机,端口号可以任意指定
val rpcEnv = RpcEnv.create("hello-client", "localhost", 52346, conf, new SecurityManager(conf))
// 根据Server端IP + Port获取后端服务的引用,得到的是RpcEndpointRef类型对象
val endpointRef = rpcEnv.setupEndpointRef(RpcAddress("localhost", 52345), "hello-service")
// 1、客户端异步请求
// 客户端通过RpcEndpointRef#ask方法异步访问服务端,服务端通过RpcEndpoint#receiveAndReply方法获取到该请求后处理
val future = endpointRef.ask[String](SayBye("neo"))
// 客户端请求成功/失败时的处理方法
future.onComplete {
case scala.util.Success(value) ⇒ println(s"Got the result = $value")
case scala.util.Failure(e) => println(s"Got error: $e")
}
// 客户端等待超时时间
Await.result(future, Duration("5s"))
// 2、客户端同步请求
val resp = endpointRef.askWithRetry[String](SayHi("hehe"))
print(resp)
}
}
运行效果如下,可以看到52436端口被用来启动了一个hello-client服务,接下来就是通过获取的EndpointRef连接到上面启动的Driver上。


代码的关键是RpcEnv.setupEndpointRef,通过一个RpcAddress类指定server服务的主机名和端口号,并且要指定访问server上的哪个服务,下面代码中的hello-service必须与上面保持一致。如果写的不是hello-service可以看到报错如下,客户端还是正常连接到了服务端的端口,但是无法在服务端找到spark://hello-x@localhost:52345服务。
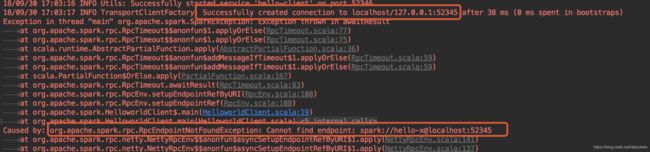
总结来说就是,服务端需要通过RpcEnv.setupEndpoint设置一个RpcEndpoint的具体实现类,该类有一些必须实现的方法处理客户端的请求。客户端通过RpcEnv.setupEndpointRef的方式获取服务端RpcEndpoint服务的引用,得到的RpcEndpointRef对象有send,ask,askSync等方法去访问服务。
三、RpcEnv分析
Spark中Driver端和Executor端通信主要通过RpcEnv来实现。两端的RpcEnv对象创建过程在SparkEnv#create方法中已经看到过了。
有关Rpc的代码在org.apache.spark.rpc包中,其中还有一个名为netty的子package。下面过程中涉及到的类主要有。这些不同类型的对象主要可以分为三类,分别是
- 环境相关,主要包括
RpcEnv,NettyRpcEnv,RpcEnvConfig,NettyRpcEnvFactory, - Server相关,主要是
RpcEndpoint,ThreadSafeRpcEndpoint, - Client相关,代表
RpcEndpoint的引用,比如RpcEndpointRef,NettyRpcEndpointRef
1、RpcEnv生成调用栈
生成RpcEnv对象的基本调用过程如下所示,最终是通过NettyRpcEnvFactory#create方法得到了一个NettyRpcEnv对象,NettyRpcEnv继承自RpcEnv类。
SparkEnv#create
----> RpcEnv#create
--------> NettyRpcEnvFactory#create
RpcEnv#create
在RpcEnv中有两个create方法,该方法的实现以及在SparkEnv中的调用方式如下,
/**
* systemName: sparkDeiver/sparkExecutor
* bindAddress: Driver端IP地址,或者Executor端的IP地址
* advertiseAddress: Driver端IP地址,或者Executor端的IP地址
* port: Executor端为空,Driver端启动时的端口号
*/
val rpcEnv = RpcEnv.create(systemName, bindAddress, advertiseAddress, port, conf, securityManager, clientMode = !isDriver)
// 定义
def create(
name: String,
host: String,
port: Int,
conf: SparkConf,
securityManager: SecurityManager,
clientMode: Boolean = false): RpcEnv = {
create(name, host, host, port, conf, securityManager, 0, clientMode)
}
def create(
name: String,
bindAddress: String,
advertiseAddress: String,
port: Int,
conf: SparkConf,
securityManager: SecurityManager,
numUsableCores: Int,
clientMode: Boolean): RpcEnv = {
val config = RpcEnvConfig(conf, name, bindAddress, advertiseAddress, port, securityManager,
numUsableCores, clientMode)
new NettyRpcEnvFactory().create(config)
}
该方法执行完成后,会在Driver端和Executor各启动一个RpcEnv环境。接下来看怎么使用这个RpcEnv环境。
四、RpcEnv使用
RpcEnv生成后,接下来主要在RpcEndpoint和RpcEndpointRef中使用。
1、在心跳中的使用
接下来以心跳为例,分析Spark中的RpcEnv通信过程。
(1)Driver端启动HeartbeatReceiver服务定期接受Executor端请求
在构建SparkContext对象时,其中有几行关于HeartbeatReceiver的代码。实际上HeartbeatReceiver是一个RpcEndpointRef实现类。
_heartbeatReceiver = env.rpcEnv.setupEndpoint(HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
...
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
...
env.rpcEnv.stop(_heartbeatReceiver)
通过主动调用RpcEnv.setupEndpoint可以将一个RpcEndpoint对象绑定到该RpcEnv上。在这里,最终调用的是NettyRpcEnv.setupEndpoint方法得到一个RpcEndpointRef对象。
// NettyRpcEnv中
override def setupEndpoint(name: String, endpoint: RpcEndpoint): RpcEndpointRef = {
dispatcher.registerRpcEndpoint(name, endpoint)
}
在Dispatcher中,生成一个NettyRpcEndpointRef对象并返回给调用方后,还会将该对象存入一个Map中,待后面使用,该Map的key是ndpointData类型的,该类型有一个name属性是在生成该RpcEndpoint时指定的,在心跳这里name = HeartbeatReceiver。
// Dispatcher中
private val endpoints: ConcurrentMap[String, EndpointData] =
new ConcurrentHashMap[String, EndpointData]
private val endpointRefs: ConcurrentMap[RpcEndpoint, RpcEndpointRef] =
new ConcurrentHashMap[RpcEndpoint, RpcEndpointRef]
...
def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef = {
val addr = RpcEndpointAddress(nettyEnv.address, name)
val endpointRef = new NettyRpcEndpointRef(nettyEnv.conf, addr, nettyEnv)
synchronized {
if (stopped) {
throw new IllegalStateException("RpcEnv has been stopped")
}
if (endpoints.putIfAbsent(name, new EndpointData(name, endpoint, endpointRef)) != null) {
throw new IllegalArgumentException(s"There is already an RpcEndpoint called $name")
}
val data = endpoints.get(name)
endpointRefs.put(data.endpoint, data.ref)
receivers.offer(data) // for the OnStart message
}
endpointRef
}
在HeartbeatReceiver.onStart方法中,启动了一个名为"heartbeat-receiver-event-loop-thread"的线程,以参数spark.network.timeoutInterval设置的时间间隔定期的调用自己的ask方法处理超时的节点。
(2)Executor端定期汇报心跳
(a)Executor发送心跳信息的完整过程
Executor上启动一个名为“driver-heartbeater”的线程,以参数spark.executor.heartbeatInterval设置的时间间隔(默认为10s)定期通过Executor.reportHeartBeat方法向Driver发送心跳Heartbeat对象。整个过程如下所示,
private[spark] case class Heartbeat(
executorId: String,
accumUpdates: Array[(Long, Seq[AccumulatorV2[_, _]])], // taskId -> accumulator updates
blockManagerId: BlockManagerId)
/** 向Driver汇报心跳,心跳中包括active状态的task信息 **/
private def reportHeartBeat(): Unit = {
...
val message = Heartbeat(executorId, accumUpdates.toArray, env.blockManager.blockManagerId)
try {
val response = heartbeatReceiverRef.askWithRetry[HeartbeatResponse](
message, RpcTimeout(conf, "spark.executor.heartbeatInterval", "10s"))
if (response.reregisterBlockManager) {
logInfo("Told to re-register on heartbeat")
env.blockManager.reregister()
}
heartbeatFailures = 0
} catch {
...
}
}
上面主要调用了RpcEndpointRef.askWithRetry方法,将由具体的RpcEndpoint.receiveAndReply方法接收该请求并作出响应,在心跳这个示例中,是由HeartbeatReceiver.receiveAndReply方法来处理请求的。
(b)Executor连接到Driver的HeartBeatReceiver
在reportHeartBeat()方法中有主要用到了一个heartbeatReceiverRef对象,该对象的生成如下,
private val heartbeatReceiverRef =
RpcUtils.makeDriverRef(HeartbeatReceiver.ENDPOINT_NAME, conf, env.rpcEnv)
在RpcUtils.makeDeiverRef方法中可以看到,最终也是类似于上面Server启动时注册那样,通过rpcEnv.setupEndpointRef来获取一个RpcEndpointRef对象。
def makeDriverRef(name: String, conf: SparkConf, rpcEnv: RpcEnv): RpcEndpointRef = {
val driverHost: String = conf.get("spark.driver.host", "localhost")
val driverPort: Int = conf.getInt("spark.driver.port", 7077)
Utils.checkHost(driverHost, "Expected hostname")
rpcEnv.setupEndpointRef(RpcAddress(driverHost, driverPort), name)
}
rpcEnv.setupEndpointRef的调用栈如下,
RpcEnv.setupEndpointRef
--> RpcEnv.setupEndpointRefByURI
----> NettyRpcEnv.asyncSetupEndpointRefByURI
所以,在NettyRpcEnv.asyncSetupEndpointRefByURI可以找到Executor获取RpcEndpointRef的过程。
def asyncSetupEndpointRefByURI(uri: String): Future[RpcEndpointRef] = {
val addr = RpcEndpointAddress(uri)
val endpointRef = new NettyRpcEndpointRef(conf, addr, this)
val verifier = new NettyRpcEndpointRef(
conf, RpcEndpointAddress(addr.rpcAddress, RpcEndpointVerifier.NAME), this)
verifier.ask[Boolean](RpcEndpointVerifier.CheckExistence(endpointRef.name)).flatMap { find =>
if (find) {
Future.successful(endpointRef)
} else {
Future.failed(new RpcEndpointNotFoundException(uri))
}
}(ThreadUtils.sameThread)
}
Client端通过name, host, port三者组合连接到Server起的Rpc服务上。在前面的示例中,这三个参数组成的URI内容为spark://hello-server@localhost:52345。
2、Executor和Driver通信
整个过程大致是这样的,在Driver端会启动一个CoarseSchedulerBackend.DriverEndpoint,在Executor端会启动一个CoarseExecutorBackend,这两者都是RpcEndpoint的子类。
Driver端的DriverEndpoint启动好后,就可以由DriverEndpoint.receiveAndReply方法准备好了处理有关Executor启动、停止等的逻辑,并且由于在Executor启动时发送的信号中获得了Executor的Ref,可以在其他方法中直接调用比如LaunchTask等动作,Driver通过这种方式向Executor发送各种指令。
Executor端通过org.apache.spark.deploy.yarn包中的一些类触发了Executor启动命令后,会在本机启动CoarseExecutorBackend,启动的第一时间就通过CoarseExecutorBackend.onStart方法向Driver报告,这时候,该Executor的引用就已经被Driver记录了。后面,当接受Driver传递过来的一系列动作时,均由CoarseExecutorBackend.receive方法进行处理,在这个方法中可以处理的信号类型有,RegisteredExecutor,RegisterExecutorFailed,StopExecutor,LaunchTask,KillTask,Shutdown。这些事件类型从字面意思就可以直接理解。
CoarseSchedulerBackend和CoarseExecutorBackend涉及到的事件信号类型都记录在CoarseGrainedClusterMessage中。
(1)Driver端启动CoarseSchedulerBackend服务
参考Spark Scheduler模块源码分析之TaskScheduler和SchedulerBackend,在YarnClientSchedulerBackend.start方法中调用了CoarseSchedulerBackend.start方法,然后接下来一系列调用栈如下所示,
CoarseSchedulerBackend.start
--> createDriverEndpointRef
----> createDriverEndpoint
------> DriverEndpoint.receiveAndReply
在DriverEndpoint.receiveAndReply方法中,关于Executor的处理方法有三个,分别是RegisterExecutor,StopExecutors,RemoveExecutor,在这个方法中会注册一个executorRef,通过该对象向Executor发送信号。
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
// 注册Executor
case RegisterExecutor(executorId, executorRef, hostname, cores, logUrls) =>
// 如果是已经启动过的Executor,则向Executor发送由于ID重复导致注册失败的信息
if (executorDataMap.contains(executorId)) {
executorRef.send(RegisterExecutorFailed("Duplicate executor ID: " + executorId))
context.reply(true)
} else {
// If the executor's rpc env is not listening for incoming connections, `hostPort`
// will be null, and the client connection should be used to contact the executor.
val executorAddress = if (executorRef.address != null) {
executorRef.address
} else {
context.senderAddress
}
logInfo(s"Registered executor $executorRef ($executorAddress) with ID $executorId")
addressToExecutorId(executorAddress) = executorId
totalCoreCount.addAndGet(cores)
totalRegisteredExecutors.addAndGet(1)
val data = new ExecutorData(executorRef, executorRef.address, hostname,
cores, cores, logUrls)
// This must be synchronized because variables mutated
// in this block are read when requesting executors
CoarseGrainedSchedulerBackend.this.synchronized {
executorDataMap.put(executorId, data)
if (currentExecutorIdCounter < executorId.toInt) {
currentExecutorIdCounter = executorId.toInt
}
if (numPendingExecutors > 0) {
numPendingExecutors -= 1
logDebug(s"Decremented number of pending executors ($numPendingExecutors left)")
}
}
// 向Executor发送注册Executor成功的信息
executorRef.send(RegisteredExecutor)
// Note: some tests expect the reply to come after we put the executor in the map
context.reply(true)
// 并且记入Listener中
listenerBus.post(
SparkListenerExecutorAdded(System.currentTimeMillis(), executorId, data))
makeOffers()
}
// Driver停止
case StopDriver =>
...
// Executor全部停止
case StopExecutors =>
logInfo("Asking each executor to shut down")
for ((_, executorData) <- executorDataMap) {
executorData.executorEndpoint.send(StopExecutor)
}
context.reply(true)
// 移除Executor
case RemoveExecutor(executorId, reason) =>
// We will remove the executor's state and cannot restore it. However, the connection
// between the driver and the executor may be still alive so that the executor won't exit
// automatically, so try to tell the executor to stop itself. See SPARK-13519.
executorDataMap.get(executorId).foreach(_.executorEndpoint.send(StopExecutor))
removeExecutor(executorId, reason)
context.reply(true)
case RetrieveSparkAppConfig =>
...
}
Driver端服务启动好之后,就可以针对不同的请求事件进行不同的动作了。比如启动Task的LaunchTask动作。这里注意,待启动的Task并不是在这里随机分配给任意Executor执行的,而是在生成Task描述信息TaskDescription时,就已经根据一定的策略以及当前Executors的现状分配好了。具体可以参考Spark Scheduler模块源码分析之TaskScheduler和SchedulerBackend
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = ser.serialize(task)
// 首先确保Task相关信息序列化后的大小不超过 spark.rpc.message.maxSize MB,默认为128MB,超过该参数大小的Task无法分配执行
if (serializedTask.limit >= maxRpcMessageSize) {
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit, maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
// 获取Executor的引用,在统计信息中减去即将分配的core数
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
logDebug(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
// 向Executor发送LaunchTask事件
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
(2)Executor端启动CoarseGrainedExecutorBackend服务
这是在Executor端启动的一个服务,长时间运行,可以接收和处理Driver端发送的请求。结合前面的Executor启动过程,当通过Yarn将启动CoarseGrainedExecutorBackend进程发送到其他节点后的具体调用栈如下,
CoarseGrainedExecutorBackend.main
--> CoarseGrainedExecutorBackend.run
在run方法中,首先会在本地创建一个SparkEnv,然后在SparkEnv.rpcEnv上注册一个CoarseGrainedExecutorBackend服务,这个过程如下所示,
// 创建Executor端SparkEnv
val env = SparkEnv.createExecutorEnv(
driverConf, executorId, hostname, port, cores, cfg.ioEncryptionKey, isLocal = false)
// 启动后台服务。
env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend(
env.rpcEnv, driverUrl, executorId, hostname, cores, userClassPath, env))
workerUrl.foreach { url =>
env.rpcEnv.setupEndpoint("WorkerWatcher", new WorkerWatcher(env.rpcEnv, url))
}
env.rpcEnv.awaitTermination()
在CoarseGrainedExecutorBackend.onStart方法中,有一些启动Executor时就需要运行的逻辑,建立一个Driver端RpcEndpointRef。
@volatile var driver: Option[RpcEndpointRef] = None
...
override def onStart() {
logInfo("Connecting to driver: " + driverUrl)
// 通过Driver端的host和port连接到Driver
rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap { ref =>
// This is a very fast action so we can use "ThreadUtils.sameThread"
driver = Some(ref)
ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls))
}(ThreadUtils.sameThread).onComplete {
// This is a very fast action so we can use "ThreadUtils.sameThread"
case Success(msg) =>
// Always receive `true`. Just ignore it
case Failure(e) =>
exitExecutor(1, s"Cannot register with driver: $driverUrl", e, notifyDriver = false)
}(ThreadUtils.sameThread)
}
然后通过该Ref访问CoarseGrainedExecutorBackend.ask方法发送一个RegisterExecutor信号用于注册Executor,这里就会由Executor连接到Driver端,告诉Driver这里已经启动好了一个Executor实例,并且把自己的Ref也通过注册信号告诉Driver,这样Driver就可以通过知道Executor的引用发送各种动作指令了。
在CoarseGrainedExecutorBackend.receive方法中,当接收到Driver端传来的各种请求时,Executor端会有不同的响应。在接收到RegisteredExecutor对象时,会生成一个Executor对象。
override def receive: PartialFunction[Any, Unit] = {
// 启动Executor
case RegisteredExecutor =>
logInfo("Successfully registered with driver")
try {
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false)
} catch {
case NonFatal(e) =>
exitExecutor(1, "Unable to create executor due to " + e.getMessage, e)
}
// Executor失败
case RegisterExecutorFailed(message) =>
...
// 启动Task
case LaunchTask(data) =>
...
// 杀死Task
case KillTask(taskId, _, interruptThread) =>
...
// 停止Executor
case StopExecutor =>
...
// 停止
case Shutdown =>
...
}
(3)Executor获取Task相关文件
Executor在通过CoarseGrainedExecutorBackend.receive响应LaunchTask事件时,将会进入Executor.launch方法。在这个方法中,得到一个TaskRunner对象。
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit = {
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
runningTasks.put(taskId, tr)
threadPool.execute(tr)
}
TaskRunner是Executor的内部类,接下来进入TaskRunner.run。在这个方法中,首先通过Task.deserializeWithDependencies反序列化Task信息,获取依赖的File文件和Jar文件,然后调用updateDependencies(taskFiles, taskJars)方法就可以在Executor端拉取文件。调用栈如下,
Executor.updateDependencies
--> Util.fetchFile
----> Util.doFetchFile
------> Util.downloadFile // 对于所有走NettyRpcEnv的master模式
在Util.downloadFile方法中,接收到的是一个InputStream对象,对应一个输出到本地的OutputStream就可以将该文件下载到本地。
所以,重点看一下Util.doFetchFile方法中的逻辑。
Util.doFetchFile
--> NettyRpcEnv.openChannel
看看在NettyRpcEnv.openChannel中如何获取输入文件流,在方法的开头可以看到基本上是通过主机名+端口号+文件路径通过网络从Driver端直接拉取的。
override def openChannel(uri: String): ReadableByteChannel = {
val parsedUri = new URI(uri)
require(parsedUri.getHost() != null, "Host name must be defined.")
require(parsedUri.getPort() > 0, "Port must be defined.")
require(parsedUri.getPath() != null && parsedUri.getPath().nonEmpty, "Path must be defined.")
val pipe = Pipe.open()
val source = new FileDownloadChannel(pipe.source())
try {
val client = downloadClient(parsedUri.getHost(), parsedUri.getPort())
val callback = new FileDownloadCallback(pipe.sink(), source, client)
client.stream(parsedUri.getPath(), callback)
} catch {
case e: Exception =>
pipe.sink().close()
source.close()
throw e
}
source
}
(4)Driver端通过RpcEnv发送Jar包和文件
在任务提交时,Jar文件通过参数spark.jars设置,如果是On Yarn模式还可以通过spark.yarn.dist.jars参数设置。File文件通过spark.files参数设置。
SparkContext启动好SparkEnv后(该对象中包含前面生成的RpcEnv对象)后的代码如下,下面代码在SparkContext中。将jar或者文件添加到RpcEnv.fileServer中。
val replUri = _env.rpcEnv.fileServer.addDirectory("/classes", new File(path))
_conf.set("spark.repl.class.uri", replUri)
def addJar(path: String) {
...
key = env.rpcEnv.fileServer.addJar(new File(path))
...
}
...
def addFile(path: String, recursive:Boolean): Unit = {
...
env.rpcEnv.fileServer.addFile(new File(uri.getPath))
...
}
接下来只需要看两点:如何将文件信息传递给executor,RpcEnv.fileServer是什么
a) 如何将文件信息传递给Executor
上一步是通过反序列化Task信息,获取该Task需要的File文件和Jar文件,那么Task所需要的文件就是在序列化的时候就已经注册好了的。这段逻辑在Task.serializeWithDependencies中,调用栈如下,
// 参考 https://blog.csdn.net/dabokele/article/details/51932102#t16
TaskSetManager.resourceOffer
--> Task.serializeWithDependencies
看一下Task.serializeWithDependencies的调用过程,Files和Jars都是在SparkContext中准备的。SparkContext调用addJar和adFile方法后,会将jar信息和file信息记入addFiles和addJars对象中,这两个对象都是Map类型。key是RpcEnv.fileServer中添加的文件路径,对于走Netty的,是以“spark://host:port/files/…”格式的一个文件路径。
Task.serializeWithDependencies(task, sched.sc.addedFiles, sched.sc.addedJars, ser)
b) RpcEnv.fileServer是什么
在RpcEnv中有一个fileServer属性,该属性是RpcEnvFileServer类型。在实际使用的NettyRpcEnv中的fileServer属性是NettyStreamManager类型的。所以,Driver端通过SparkContext.addJar和SparkContext.addFile方法都间接的调用了NettyStreamManager.addJar和NettyStreamManager.addFile方法。可以看一下NettyStreamManager.addJar的逻辑,
override def addFile(file: File): String = {
val existingPath = files.putIfAbsent(file.getName, file)
require(existingPath == null || existingPath == file,
s"File ${file.getName} was already registered with a different path " +
s"(old path = $existingPath, new path = $file")
s"${rpcEnv.address.toSparkURL}/files/${Utils.encodeFileNameToURIRawPath(file.getName())}"
}
override def addJar(file: File): String = {
val existingPath = jars.putIfAbsent(file.getName, file)
require(existingPath == null || existingPath == file,
s"File ${file.getName} was already registered with a different path " +
s"(old path = $existingPath, new path = $file")
s"${rpcEnv.address.toSparkURL}/jars/${Utils.encodeFileNameToURIRawPath(file.getName())}"
}
override def addDirectory(baseUri: String, path: File): String = {
val fixedBaseUri = validateDirectoryUri(baseUri)
require(dirs.putIfAbsent(fixedBaseUri.stripPrefix("/"), path) == null,
s"URI '$fixedBaseUri' already registered.")
s"${rpcEnv.address.toSparkURL}$fixedBaseUri"
}
其中rpcEnv.address的逻辑如下,这里得到的是一个RpcAddress对象,
override lazy val address: RpcAddress = {
if (server != null) RpcAddress(host, server.getPort()) else null
}
从这里可以看到,在NettyRpcEnv中有一个NettyStreamManager对象,该对象是RpcEnvFileServer的子类。即在RpcEnv中有一个RpcEnvFileServer服务在运行,供Executor节点通过host+port+path的方式拉取文件。