#【Yolo的听课笔记三】CNN与图像高级应用
#【Yolo的听课笔记三】CNN与图像高级应用
我是刚刚接触计算机视觉的小白Yolo,很多知识都处于摸索阶段。为了记录自己的学习历程,我在这里把自己的学习内容进行总结.
听课笔记系列是为了整理自己在各个课程中的笔记,主要是回顾课堂内容,也融入了一些自己的理解和网上资料。
本笔记来自于七月在线,详细课程介绍请点击 深度学习第四期
目录
文章目录
- 目录
- 背景介绍
- 图像的识别和定位
- 语义分割
- 转置卷积
背景介绍
CNN是一种应用非常广泛的神经网络,在计算机视觉的各个领域都有广泛的应用,图像识别、目标检测、图像分割这些高级应用的实质都是运用了卷积神经网络CNN。以在图像识别为例,在ImageNet挑战赛上,2011年之前所使用的方法基本上都是传统的图像识别,2012年,Alexnet神经网络横空出世,大幅降低了图像识别的误差,从那一年开始,CNN开始称霸这个领域,图像识别效果不断发展,并在2015年正式超过了人类的识别能力。

接下来,将详细的对各个高级应用进行研究讨论。
图像的识别和定位
###图像相关任务
物体识别主要是运用计算机识别物体,包括对物体进行框选和分类两个过程。
相关任务包括如下几类:
- 图片识别
对物体进行分类,确定物体的种类。 - 图片识别+定位
在对物体进行分类的基础上,用boundingbox框选出物体的位置,从而实现定位。
图像的识别实质是一个分类的过程,对于一张输入的图片,我们将其中的物体分类为C个类别中的其中一个。在这个过程中,输入为图像,输出为图像的标签,我们用分类的准确率来对识别效率进行比较。而在图像的定位部分,输出为图像的边界框 ( x , y , w , h ) (x,y,w,h) (x,y,w,h),其中 x x x, y y y为边界框的左上角或中心点坐标, w w w表示边界框的宽, h h h表示图像的高度。定位的评比标准为IOU交并准则, 它定义了两个bounding box的重叠度,如下图所示
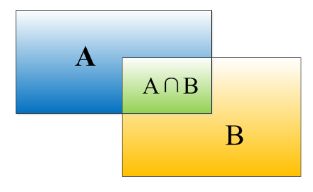
就是矩形框A、B的重叠面积占A、B并集的面积比例。 - 物体检测
当图像上有多个物体时,同时对多个物体进行框选 - 图像分割
在对物体进行框选的基础上,检验物体的边缘,知道每个像素点的位置。
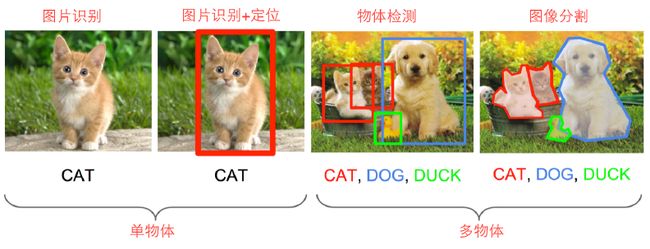
著名的ImageNet挑战赛其实就包括图像的识别和定位两个过程。

图片识别:从C个种类中选出一个,属于分类问题,我们可以使用softmax函数来完成分类。
物体定位:这个过程其实是一个属于监督学习,首先给出一个groundtruth作为标准答案,然后计算标准答案和预估答案之间的误差,最终得到的 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)为一组连续值。
###思路1:看作回归问题
我们可以把识别+定位问题看成是一个回归问题。该过程的具体步骤如下:
步骤1:首先我们考虑解决较为简单问题,先搭一个可以识别图像的神经网络,为了减少训练的困难,首先我们选择一个已经训练好的神经网络,如AlexNet 、VGG 、Google、Lenet或 ResNet,然后在这个神经网络上进行fine-tune,从而得到相应的参数(这个过程可以看成是一个迁移学习的过程)。

步骤2:对于上述已经预训练好的模型,我们将神经网络的最后一层去掉,加一个四个输出的层即可以实现定位,加一个分类层即可以实现分类。得到的两组结果一组用于分类,一组用于定位,从而将该神经网络变成classification + regression模式。

步骤3:在回归部分,我们利用欧氏距离计算损失,并使用SGD(随机梯度下降法)进行优化。
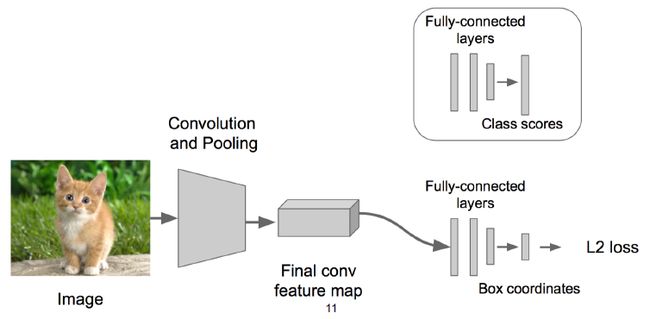
步骤4:在预测阶段,我们把2个“头部”模块拼上,即可实现相应的功能。拼接上“分类"模块,就可以对图像进行分类;拼接上“定位"模块,就可以对图像进行定位。如果要同时实现分类和定位,则同时拼接两个头即可。

这里其实会涉及到一个问题,Regression的模块部分加在什么位置?它即可以加在最后的卷积层之后,也可以加在全连接层之后,客观的讲,这两种拼接方式都有应用,且各有利弊,使用时根据实际情况进行选择即可。

接下来我们讨论另一个问题,这个过程可以进行泛化吗?
答案是肯定的,比如还是刚刚那只猫的图像,我们可以对其进行更加细致的操作,框选出猫的四只爪子,两只眼睛和一个鼻子,这个过程和之前完全相同,无非是进行输出的连续值组数变多而已。一个物体对应一个四元组 [ x ′ y ′ w ′ h ′ ] \begin{bmatrix} {x}'\\ {y}'\\ {w}'\\ {h}' \end{bmatrix} ⎣⎢⎢⎡x′y′w′h′⎦⎥⎥⎤,则四只爪子,两只眼睛和一个鼻子相当于七个物体,对应七个四元组。进一步来说,我们可以将提前规定一个物体有K个组成部分,把这个问题看成是K个部分的回归,从而实现对物体更细致的识别。
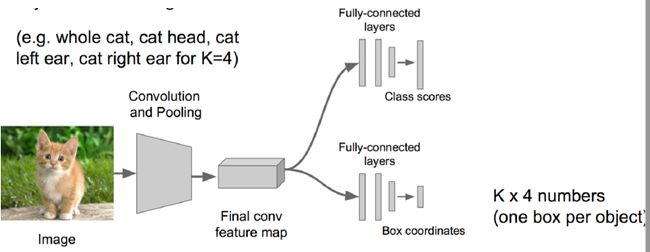
我们可以利用这种方法进行人体的姿态识别,把人看成是有若干个关节组成的火柴人,人的每一个关节都是固定的,对K个组成部分(关节)做回归预测=> 首尾相接的线
段。

###思路2: 图窗+识别与整合
类似刚才的classification + regression思路,首先我们取不同的大小的“框”,让框出现在不同的位置,在不同的位置我们都可以认为是进行一个分类问题,判定得分,按照得分高低对“结果框”做抽取和合并。这里需要注意的是,我们最终得到的边框不一定就是这个进行滑动的窗口,在检测物体的过程中,会根据实际的检测情况进行缩放。如下图的右下角猫,黑色边框截取的猫头部并不完整,神经网络会检测到这个现象对黑色边框进行微调,让边框能更好的选出物体。
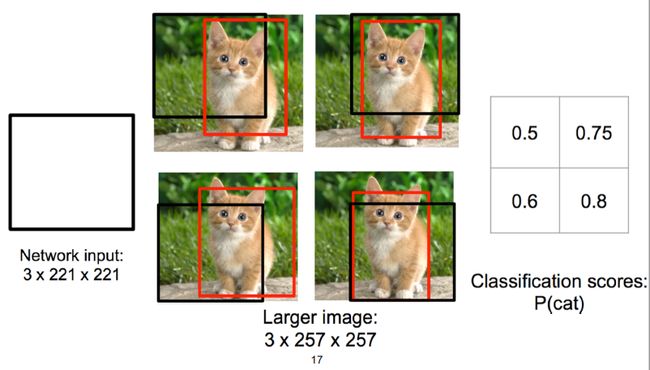
在实际应用时,窗口的大小可以视为是一种超参数,我们可以使用各种不同大小的窗口进行滑动,甚至会在窗口上再做一些“回归”的事情。
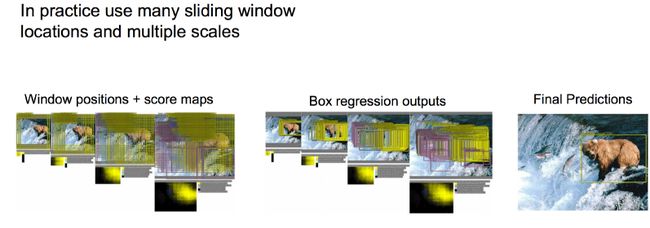
但这个过程并不是非常完美,在窗口滑动的过程中,每个位置我们都需要进行回归运算,会消耗大量的计算力,“参数多”与“计算慢”是我们迫切需要解决的两个问题。经过仔细考虑之后我们发现,在窗口滑动的过程中,其实窗口之间会发生重叠,有一部分图框的运算会重复,如果可以解决这个问题,我们就可以节省大量的计算资源。
我们可以用多卷积核的卷积层替换全连接层,其中每个卷积核的大小都是 1 ∗ 1 1*1 1∗1,这么做可以大量减少参数量,而且替换成 1 ∗ 1 1*1 1∗1的卷积核不会影响计算结果。

由于图框的重叠,测试和识别阶段的计算其实是可复用的(小卷积),因此,如果能很好的利用这一部分复用,我们可以对计算进行加速。我们使用的 1 ∗ 1 1*1 1∗1卷积核把全连接层替换为全卷积层,最终得到的结果相同,但是全连接层不能进行复用,用全卷积层可以进行复用,因此这么做可以对计算进行加速。

##物体识别
当图像中有多个物体存在时,这时候我们称为物体识别问题。我们很容易想到如果我们知道图像中同样多少物体时,只需要输出的连续值增加为原来的多少倍就行,但问题是,如果我们不知道图像中到底含有多少物体时,问题就会变得很棘手,因为神经网络的输出需要事先确定。


我们可以将其看成是分类问题,滑窗在图片上进行滑动,每滑到一个位置用CNN来判断物体的类别。但是这个过程涉及到不同大小、不同位置和不同比例的边框,而且还需要对框内的物体进行很多次分类,因此计算量非常大。
我们知道,每个图像有不同的像素点,然后用聚类方法将各个像素点进行聚类,得到一定的区域,这个区域就是候选框(可能有物体存在的区域),然后对候选框进行分类。
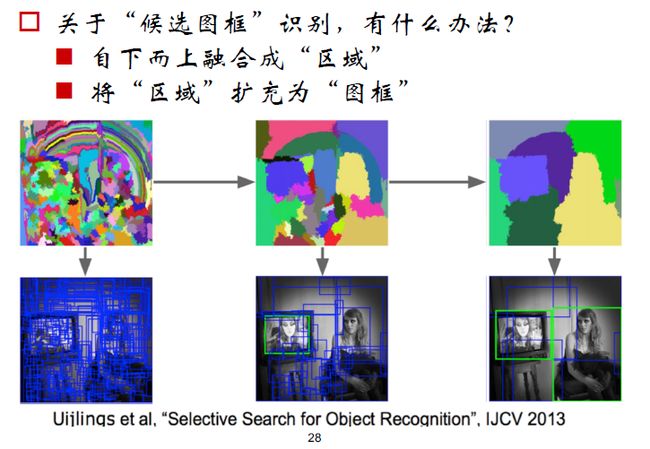
###RCNN
RCNN是一种基于选择性搜索的物体识别方法,先得到图像的候选区域(在2000个候选框左右),然后利用监督学习对候选框进行微调,用SVM对框内物体进行分类。
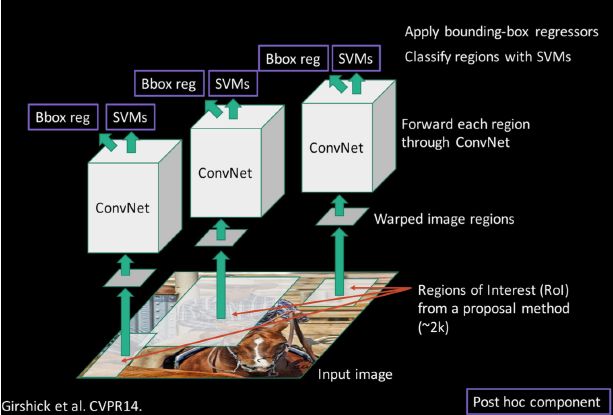
该过程的详细流程如下:
步骤1:首先找一个预训练好的模型(Alexnet,VGG),然后针对你的场景做fine-tune
步骤2:对模型进行必要的调整,比如20个物体类别+1个背景
步骤3:用“图框候选算法”抠出图窗,对图像进行Resize(图片的大小不一定相同,但是全连接层对输入图像的大小有一定的要求,因此我们需要将图像resize到一定大小),后用CNN做前向运算,取第5个池化层做特征,存储抽取的特征到硬盘/数据库上。
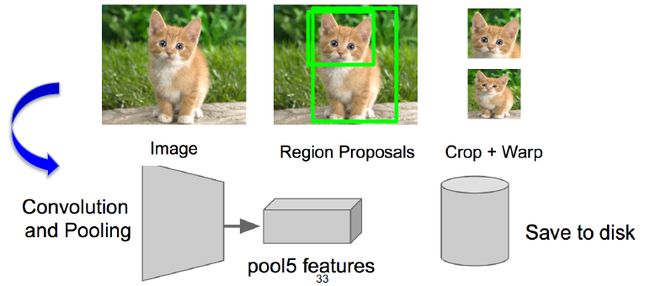
步骤4:训练SVM识别是某个物体或者不是(这是一个2分类问题)
步骤5:根据候选框内物体是否完整,神经网络会对边框进行 bbox regression,微调图窗区域。

###Fast-RCNN
RCNN处理一张需要的时间在40秒左右,非常缓慢。我们对RCNN的结构进行重新审视后发现,它所耗费的时间主要是因为对于所有的候选框都需要进行resize,都需要通过CNN。因此,Fast-Rcnn主要是针对这个过程进行改进。主要有如下两种:
- 共享图窗计算
Fast-RCNN指出R-CNN耗时的原因是CNN是在每一个Proposal上单独进行的,没有共享计算,便提出将基础网络在图片整体上运行完毕后,再传入R-CNN子网络,共享了大部分计算。
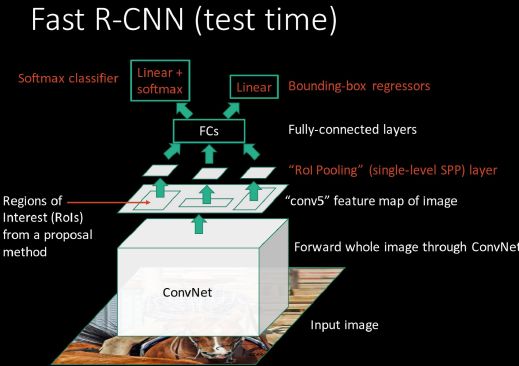
2 . 直接做成端到端的系统 :
R-CNN中用于分类的方法是SVM,用于边框校准的是bbox(线性模型),多个阶段导致需要的时间比较长。因此在fast-RCNN中,我们用全连接层来完成这两个操作,将两个损失进行加权,其中权重是一个超参数。

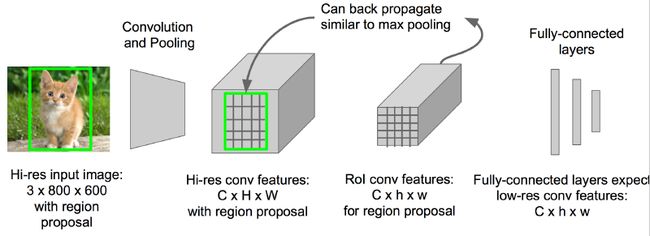
在用边框对图像中的物体进行框选时,原图中的区域大小不同,会导致输入全连接层的大小不同。那么这个维度不匹配问题应该如何解决呢?我们在原图得到的feature map上划分格子,然后对其进行池化,选出相同大小的区域输入全连接层中。
映射关系显然是可以还原回去的,conv5中的点(子矩阵)对应原图的区域。
###Faster-RCNN
在RCNN和fast-RCNN中,候选框均由selective search完成,而selective search不能再CPU上进行,我们考虑候选区域的生成能不能在神经网络上进行。

在这里我们使用RPN来完成候选框的生成,在feature map上选择不同长宽比和大小的子图,它对应回原图的是不同大小的区域,我们可以用和这个方法进行分类和回归。

从RCNN到Faster-RCNN,这一系列都是双阶段的目标检测方法,即先生成候选区域,然后在对候选区域进行分类。而Yolo和SSD都是属于单阶段目标检测方法。把原图画成一定数目的格子,对每个格子基于不同的base box考虑他的confidence,即是否有物体存在。

语义分割
语义分割是对像素点进行分类,主要有如下三种方法。
滑窗处理
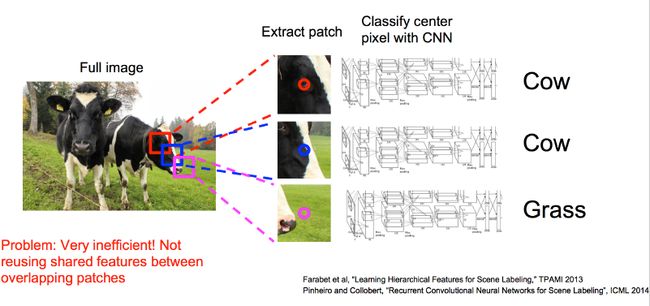
全卷积网络
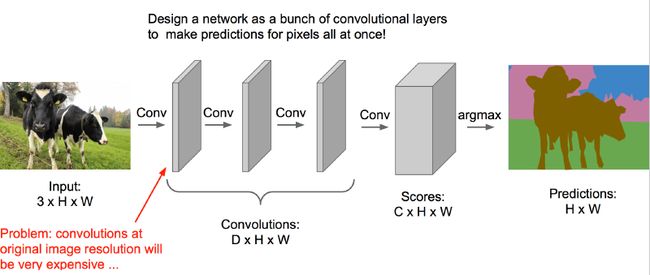
“下采样”与“上采样”的全卷积网络
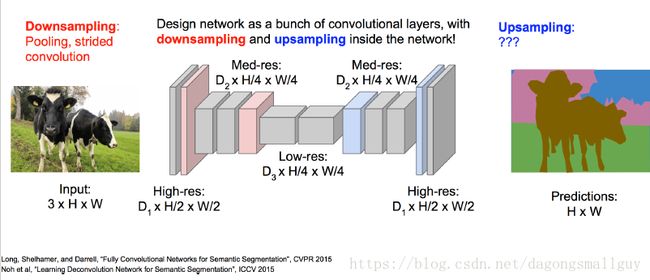
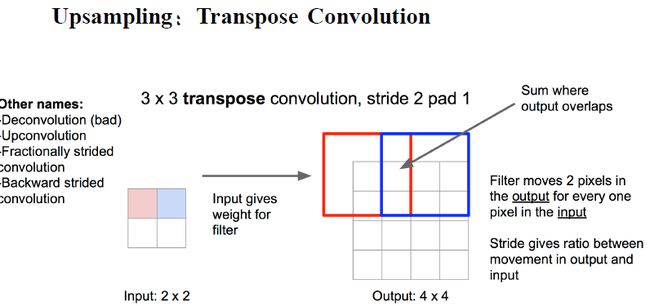
转置卷积
转置卷积是卷积的逆操作对于给定的一个数,我们给定一个权重,相当于对他进行放大。