串匹配问题与KMP算法
目录
问题
蛮力算法
KMP算法-主算法
KMP算法-生成next表
KMP算法-复杂度分析
KMP算法-next表改进
问题
在现实中经常遇到这样的需求:
给一个较长的串T,长n,和一个较短的串P,长m,设计算法判断P中是否包含T,若有,返回T中和P匹配的子串起点的下标。
蛮力算法
最容易想到的就是两个串头部对齐,两个指针i、j表示T和P中进行匹配的元素的下标(初始化为0),逐个元素比对,遇到比对失败(称这种情况为失配)则将P右移一步(P的滑动是通过指针的回退实现的,i每次回退到对齐位置的下一格,j每次回到0),再重新开始匹配,直到找到T中匹配的子串(匹配成功)或直到T头部到n-m处的情况下(可能匹配的最后位置)还出现失配(匹配失败),算法结束。代码如下
public int bruteForce(char [] T, char [] P) {
int n = T.length, m = P.length;
int i = 0, j = 0;
while(i < m && j < n) {
if(T[i] == P[j]) {
i++; j++;
}else {
i -= j - 1;//每次回退j都回到0, 失配时走了j步
j = 0;
}
}
return i - j;//i-j就是对齐的位置
}这种算法简单粗暴,逐次比对,被称为蛮力算法。表现与数据情况有关:字符集越小,局部匹配的概率就越大,回退次数就越多,浪费掉的运算就越多。不难看出蛮力算法的时间复杂度是O(n*m)。有没有更快的方法呢?
KMP算法-主算法
我们观察一下蛮力算法匹配的过程。每一次失配,都要把j回退到0重新匹配,每一次都是新的开始。而前面虽然有局部匹配的前缀,但是信息都被丢弃掉了,进行了大量的无效运算。如果能充分利用失配时局部匹配的信息,就能大幅加快匹配的速度。比如图中的情况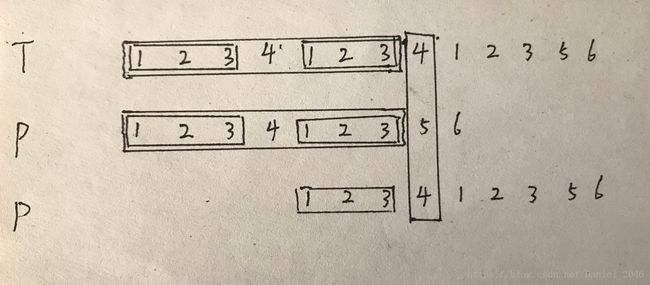
这种情况属于“对于P的真前缀P[0 , j),存在长度为 t 的真前缀P[0 , t)和真后缀P[j - t , j)完全匹配,且 t 是满足条件的最大长度”。同时,因为t时长度为j的子串P[0 , j)的真前缀、真后缀的长度,所以t < j。
再看一下示意图,参与比对的T[i - j, i)和P[0 , j)是完全相同的,在P向右逐步滑动的过程中,任何时刻有两种可能:P和T[i - j, i)对齐的部分完全匹配 or 不完全匹配。对于完全匹配的情况,就可以跳过T[i - j, i)从T[i]开始进行比对;而不完全匹配的情况则一定存在失配,需要继续滑动,也就没有研究的必要。所以,我们的目标就是跳过不完全匹配的情况,从而加快匹配速度。
而“对于P的真前缀P[0 , j),存在长度为 t 的真前缀P[0 , t)和真后缀P[j - t , j)完全匹配,且 t 是满足条件的最大长度”就是解决问题的关键。在这种情况下,可以通过向右滑动P,把令P[0 , t)占据P[j - t , j)的位置,P[0 , t) == P[j - t , j)、P[j - t , j) == T[j - t , j),此时P[0 , t)和T[j - t , j)必然是完全匹配的,可以直接省略这一段,直接从刚刚失配的T[i](即P[t])开始继续比对。代码主体如下:
public int kmp(char [] T, char [] P) {
int n = T.length, m = P.length;
int i = 0, j = 0;
int [] next = makeNext(P);
while(j < m || i < n) {
if(j < 0 || T[i] == P[j]) {//j<0一定要写在前面,具体意思暂时不用明白,下面会讲
i++; j++;
}else {
j = next[j];
}
}
return i - j;
} KMP算法-生成next表
要实现“令P[0 , t)占据P[j - t , j)的位置”,那么当任意P[j]失配时,必须知道现在P要滑动到什么位置,也就是指针j要回退到什么位置。方法是:构建一个next表,在里面保存在P的每个下标位置失配的时候,j要回退到的位置。
再次说明next表中元素的含义。对于任一 next[j] = t,表示“对于P的真前缀P[0 , j),存在长度为 t 的真前缀P[0 , t)和真后缀P[j - t , j)完全匹配,且 t 是满足条件的最大长度”。 P[t]正是上述前缀的下一个元素。
在对比时,有两种可能:P[j] == P[next[j]] 、P[j] != P[next[j]]。
当P[j] == P[next[j]],很自然地将t增加1,next[j + 1] = next[j] + 1。
当P[j] != P[next[j]],要找到下一个尽可能长,可以对齐一部分P的比对位置。也就是说找到在当前的P[0 , j)上自匹配的真前缀和真后缀换过来。目标位置就是next[j]。如果再不行,就是next[next[j]],以此类推,和主算法的思路是一样的。事实上生成next表的过程就是P自身对子串进行匹配的过程。t < j,故next[j]一定在 j 前面,所以可以用递推法生成next表,。
public int[] makeNext(char[] P) {
int m = P.length;
int [] next = new int[m];
int j = 0, t = -1;
next[0] = t;
while(j < m - 1) {
if(t < 0 || P[t] == P[j]) {//如果比对成功
next[j] = t;
}else {
t = next[t];
}
}
return next;
}解释一下代码。为什么t的初始值为-1?这个算法假象地在P[0]的前面放置了一个可以和任何元素匹配的通配符 * ,秩为-1,这里用t < 0表示和通配符比对成功,(t < 0 || P[t] == P[j]) 就是所有比对成功的情况。有了这个通配符,就可以开始递推next表下面的每一个t了,每一次比较在最坏情况下也会在-1位置和这个通配符比对成功。
KMP算法-复杂度分析
设置一个观察值k = 2 * i - j。
对于主算法,k初值为0,单调递增,每次迭代不管进入哪种分支,k都递增1(i、j同时+=1 或 i不变j+=1),所以k可以用来指示迭代次数。i最大为 n-1, j最小为 -1。当算法结束,有 k <= 2(n - 1) - (-1)。时间复杂度O(n)。
生成next表的过程和主算法思路相似,不难得出时间复杂度O(m)。
所以整体的复杂度为O(n+m),线性复杂度,比O(n*m)的蛮力算法快得多。
KMP算法-next表改进
上面的算法已经很快了,但还有改进余地。想象一下这种情况
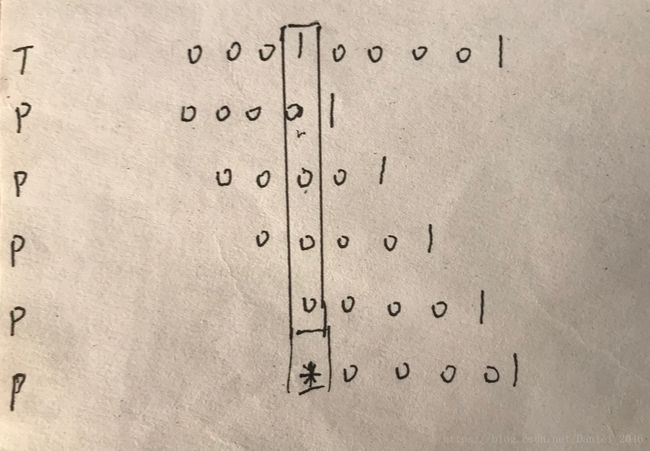
用上面的makeNext(),这个P的next表为{-1, 0, 1, 2, 3}。令P按照这样的规则滑动,我们会发现重复的元素0被多次用来和1进行比对,这让算法退化到了蛮力算法的水平。
而既然已经知道了0和1不匹配,完全可以就不再让和0相同的元素被拿来同已知和0不匹配的元素1进行比对。也就是说,即使不能保证下一个对齐上来和T[i]比对的元素一定等于T[i],起码要保证它一定不等于当前的P[j]。
public int[] makeBetterNext(char[] P) {
int m = P.length;
int [] next = new int[m];
int j = 0, t = -1;
next[0] = t;
while(j < m - 1) {
if(t < 0 || P[t] == P[j]) {
++j; ++t;
next[j] = P[j] != P[t]? t: next[t]; //next表相邻两元素一定不同,除非是两个-1
}else {
t = next[t];
}
}
return next;
}这样改动之后,避免了很多明知不可能成功却“以卵击石”的尝试,算法的效率得到进一步提高。