NLP 学习笔记 05 (Log-linear Models)
==============================================================
== all is based on the open course nlp on coursera.org week 7,week 8 lecture ==
================================================================
1.The Language Modeling Problem
现在抛开我们之前讲的马尔科夫模型的假设,对于一门语言的定义,肯定不能简单依赖于每个单词的前两个单词,这是常识。比如英语中的动词形态就和主语有关。那么我会怎么考虑一个语言模型呢,很可能是下面这样一个情况:

我们之前讲的Trigram模型也可以用这样的形式来表示:
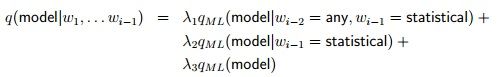
那么我们要用我们增加的一些定义,一种naive的方法就是选取一些参数来生成模型:

可以想象,这是很难驾驭的。但是我们可以用这样的模型来理论上地表示一些例子。
而下面要讲的Log-Liner Model就可以加入这些信息,并使其可操作。
2.Log-linear models
2.1 Define
我们首先用对Language Model的描述来引入log-linear model,Log-linear model其实是可以引入到很多问题里面的。
这里我先作如下定义:

然后我们定义feature(参数),一个参数就是一个函数,把x,y映射到一个具体的值

一般来讲,我们设定一个参数值选择为binary的值,要么为1,要么为0
然后假设我们有m个不同的参数,对于一组(x,y),我们就有一个长度为m的参数值向量:
比如在language model中我们有这样一系列的参数:

在实际中,这些参数的数量是非常多的,为了方便,我们常常用简便的方式来表示一些类似的参数:

其中N(u,v,w)把每一组u,v,w映射为一个不同的整数,这一组参数的数量就是不同u,v,w的数量,其实这也就是trigram model的定义,只不过我们用另一种方式表达出来而已。
2.2 Result
这样我们就得到了一组m个参数,同时我们再定义一个长度为m的向量v,然后我们就可以把(x,y)映射为一个“score”(得分)了:

其实就是数学中的向量的点乘。
2.3 Further Define
我们接下来再进一步用log-linear model来表示我们的Language model:
我们有一个X是input空间,Y是一个有限的词语空间,我们使:

这就是我们的log-linear模型下的语言模型了,注意e的指数其实就是我们上面所说的"score"
为什么叫log linear 模型呢?我们对两边取log看一下:
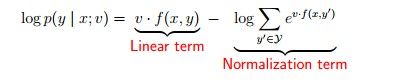
一目了然了是吧
2.4 for other problem
除了Language Model,log liner的方法还可以用到其他问题上,比如说tagging problem(这个问题的描述在之前的日志有讲:点击打开)
我们要做的是重新设计feature函数,以及改变一下 history的的定义(也就是上面的x),上面我们是使x=w1,w2…wi-1
在tagging problem中我们使:

这样就是 tagging problem 的log linear模型了,所以说log linear可以应用于比较广的范围。下面我们会详细讲 Tagging Problem中的log-linear model
3.Maximum-Likelihood Estimation for Log-liner Model
3.1 introduction
下面介绍下怎么从训练数据中得到参数,选择的方法叫做ML(最大似然估计)
我们有的就是一系列的x和y
首先选择v:
其中L(v)为:

它叫做似然函数。
有了似然函数,我们就可以选择一种叫做Gradient Ascent的方法,也就是求使L函数最大的v
这个其实就是梯度上升,就是在L上对v求导,得到梯度,然后一步步用梯度趋近最大值(这其实和梯度下降是相似的,具体可以见这里的部分内容)

然后我们每次迭代使v加上 (β乘以这个导数),β是学习时选择的参数,叫做学习速率。
3.2 Regularization
如果L只是简单地上面那种形式,算法很可能会过拟合,一些v会变成非常大来更好地增大似然函数,但这种增大是畸形的,叫做overfitting
解决的方法很多,最简单的一种就是加入regularization的部分,也就是:

这样的话如果v过大就会招致penalty
那么:

########下面的课程相对细讲了log linear model对于Tagging和Parse问题的方案,我选简单的写一个=========
########其实模型都是相似的===============================================================
4、Log-Linear Models for History-based Parsing
4.1回顾下Log-Linear Taggers
好吧,这段我懒了,没有写log linera tagger的内容,所以在这补充总结一下,其实也不是很复杂

大概就是这样的一个模型,可以看出其实就是2.4的内容。
4.2 History-Based Models
有了tag以后,我们可能还会有需求去求的一个parse,也就是语法树,一步步来。
假设我们能够将一颗树表示为一系列的decisions,假设为m个,我们有:
注意这里的m不一定是句子的长度,我们可以做很多decision来表示句子树的结构
然后我们定义:
那么对于一棵树的probability就是:

Over------就这么简单,关键是我们要怎么来设计我们的decision
注意和4.1对比一下,我们如果把decision换成tag的内容,就变成了Tagger的问题
4.3Ratnaparkhi's Parser:
再继续我们的内容之前,先放一个例子在这,好继续描述:

下面主要讲的是一个叫做Ratnaparkhi的人的model,好吧,又是一个90后的model……
他的模型主要分三层:
1. Part-of-speech tags
这部分就是简单的tag的model,每个decision就是一个tag的选择

2. Chunks
Chunks其实就是短语部分的模型:

也就是上面那一排tag,其正式点的定义就是:所有儿子都是
Part-of-speech tags的节点
如何表示它的decision呢?我们用SART和JOIN来表示

一目了然?再加上第一层的模型,现在我们的decision已经有2*n个了:

3. Remaining structure
Remaining structure,我们看一下这颗tree还有什么remaining了呢?更高层的树的结构
我们将用Check来在第二层的基础上来表示这棵树:Check=NO 或者 YES
首先我们跑一次第二层,Check一直设置为NO,不增加什么操作,直到:
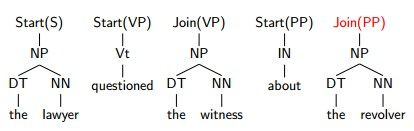
我们设置Check=YES,那么发生奇迹的时刻到了,看到没,一组Start和Join消失了,取而代之的是一个Chunk:PP

我们再继续,CHECK继续为NO:

看到没,在选择Check为YES的时候就把上一个start的部分合并成一个符号!!!
这样继续到最后,我们就得到了最终的decision:

4.4 Applying a Log-Linear Model
其实比较简单,就是di作为输入,而作为history
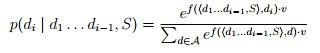
其中A表示所有可能的action(decision)
那么现在还有一个最大的问题,怎么设计我们的 f ?!!
Ratnaparkhi的模型中主要还是关联了decision的部分,我们同样可以对decision进行trigram或者bigram模型的设计,这是和以前的定义一样的,然后将各部分混杂起来就会得到很多的f了。
4.5 Search Problem
在POS tagging问题中我们能够使用Viterbi algorithm的原因是我们有如下假设:
但是现在的decision可能依靠之前的任意一个decision,动态规划是没辙了。。。。
这一部分会在下一周的课程讲到。^_^