深度学习在视频行为识别中应用
深度学习在最近十来年特别火,几乎是带动AI浪潮的最大贡献者。互联网视频在最近几年也特别火,短视频、视频直播等各种新型UGC模式牢牢抓住了用户的消费心里,成为互联网吸金的又一利器。当这两个火碰在一起,会产生什么样的化学反应呢?
不说具体的技术,先上一张福利图,该图展示了机器对一个视频的认知效果。其总红色的字表示objects, 蓝色的字表示scenes,绿色的字表示activities。
图1
人工智能在视频上的应用主要一个课题是视频理解,努力解决“语义鸿沟”的问题,其中包括了:
· 视频结构化分析:即是对视频进行帧、超帧、镜头、场景、故事等分割,从而在多个层次上进行处理和表达。
· 目标检测和跟踪:如车辆跟踪,多是应用在安防领域。
· 人物识别:识别出视频中出现的人物。
· 动作识别:Activity Recognition,识别出视频中人物的动作。
· 情感语义分析:即观众在观赏某段视频时会产生什么样的心理体验。
短视频、直播视频中大部分承载的是人物+场景+动作+语音的内容信息,如图1所示,如何用有效的特征对其内容进行表达是进行该类视频理解的关键。传统的手工特征有一大堆,目前效果较好的是iDT(Improved Dense Trajectories) ,在这里就不加讨论了。深度学习对图像内容的表达能力十分不错,在视频的内容表达上也有相应的方法。下面介绍最近几年主流的几种技术方法。
1、基于单帧的识别方法
一种最直接的方法就是将视频进行截帧,然后基于图像粒度(单帧)的进行deep learninig 表达, 如图2所示,视频的某一帧通过网络获得一个识别结果。图2为一个典型的CNN网络,红色矩形是卷积层,绿色是归一化层,蓝色是池化层 ,黄色是全连接层。然而一张图相对整个视频是很小的一部分,特别当这帧图没有那么的具有区分度,或是一些和视频主题无关的图像,则会让分类器摸不着头脑。因此,学习视频时间域上的表达是提高视频识别的主要因素。当然,这在运动性强的视频上才有区分度,在较静止的视频上只能靠图像的特征了。
图2
2、基于CNN扩展网络的识别方法
它的总体思路是在CNN框架中寻找时间域上的某个模式来表达局部运动信息,从而获得总体识别性能的提升。图3是网络结构,它总共有三层,在第一层对10帧 (大概三分之一秒)图像序列进行MxNx3xT的卷积(其中 MxN是图像的分辨率,3是图像的3个颜色通道,T取4,是参与计算的帧数,从而形成在时间轴上4个响应),在第2、3层上进行T=2的时间卷积,那么在第3层包含了这10帧图片的所有的时空信息。该网络在不同时间上的同一层网络参数是共享参数的。
它的总体精度在相对单帧提高了2%左右,特别在运动丰富的视频,如摔角、爬杆等强运动视频类型中有较大幅度的提升,这从而也证明了特征中运动信息对识别是有贡献的。在实现时,这个网络架构可以加入多分辨的处理方法,可以提高速度。
图3
3、双路CNN的识别方法
这个其实就是两个独立的神经网络了,最后再把两个模型的结果平均一下。上面一个就是普通的单帧的CNN,而且文章当中提到了,这个CNN是在 ImageNet的数据上pre-train,然后在视频数据上对最后一层进行调参。下面的一个CNN网络,就是把连续几帧的光流叠起来作为CNN的输入。 另外,它利用multi-task learning来克服数据量不足的问题。其实就是CNN的最后一层连到多个softmax的层上,对应不同的数据集,这样就可以在多个数据集上进行 multi-task learning。网络结构如图4所示。
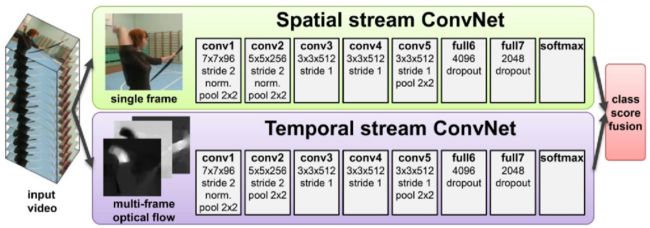
图4
4、基于LSTM的识别方法
它的基本思想是用LSTM对帧的CNN最后一层的激活在时间轴上进行整合。这里,它没有用CNN全连接层后的最后特征进行融合,是因为全连接层后的高层特征进行池化已经丢失了空间特征在时间轴上的信息。相对于方法2,一方面,它可以对CNN特征进行更长时间的融合,不对处理的帧数加以上限,从而能对更长时长的视频进行表达;另一方面,方法2没有考虑同一次进网络的帧的前后顺序,而本网络通过LSTM引入的记忆单元,可以有效地表达帧的先后顺序。网络结构如图5所示。
图5
图 5中红色是卷积网络,灰色是LSTM单元,黄色是softmax分类器。LSTM把每个连续帧的CNN最后一层卷积特征作为输入,从左向右推进时间,从下到上通过5层LSTM,最上的softmax层会每个时间点给出分类结果。同样,该网络在不同时间上的同一层网络参数是共享参数的。在训练时,视频的分类结果在每帧都进行BP(back Propagation),而不是每个clip进行BP。在BP时,后来的帧的梯度的权重会增大,因为在越往后,LSTM的内部状态会含有更多的信息。
在实现时,这个网络架构可以加入光流特征,可以让处理过程容忍对帧进行采样,因为如每秒一帧的采样已经丢失了帧间所隐含的运动信息,光流可以作为补偿。
5、3维卷积核(3D CNN)法
3D CNN 应用于一个视频帧序列图像集合,并不是简单地把图像集合作为多通道来看待输出多个图像(这种方式在卷积和池化后就丢失了时间域的信息,如图6上), 而是让卷积核扩展到时域,卷积在空域和时域同时进行,输出仍然是有机的图像集合(如图6下)。
图6
实现时,将视频分成多个包含16帧的片段作为网络的输入(维数为3 × 16 × 128 × 171)。池化层的卷积核的尺寸是d x k x k, 第一个池化层d=1,是为了保证时间域的信息不要过早地被融合,接下来的池化层的d=2。有所卷积层的卷积核大小为3x3x3,相对其他尺寸的卷积核,达到了精度最优,计算性能最佳。网络结构如图7所示。这个是学习长度为16帧(采样后)视频片段的基础网络结构。对于一个完整的视频,会被分割成互相覆盖8帧的多个16帧的片段,分别提取他们的fc6特征,然后进行一个简单平均获得一个4096维的向量作为整个视频的特征。
图7
通过可视化最后一个卷积层对一个连续帧序列的特征表达,可以发现,在特征开始着重表达了画面的信息,在特征的后面着重表达的是运动信息,即在运动处有相对显著的特征。如图8。
图8
和单帧图特征在视频测试集上进行对比,3D CNN有更强的区分度,如图9。
图9
6、阿里聚安全内容安全(阿里绿网)
阿里聚安全内容安全(阿里绿网)基于深度学习技术及阿里巴巴多年的海量数据支撑, 提供多样化的内容识别服务,能有效帮助用户降低违规风险。其产品包括:ECS站点检测服务、OSS图片鉴黄服务、内容检测API服务。针对多媒体内容中的违规视频内容,绿网致力于提供一整套内容安全的垂直视频解决方案。以下是一些诸如图像识别,视频识别(人物动作识别)公开的训练、评测数据集。
· UCF-101
一共13320个视频, 共101个类别。
· HMDB51
一共7000个视频片段,共51个类别。
200类,10,024个训练视频,4,926个交叉验证视频,5,044 个测试视频。

· 1M sport
1.2 million个体育视频,有487个已标记的类,每类有1000到3000个视频。