在windows下搭建spark1.x开发环境小记(winutils.exe找不到报错)
在windows下搭建spark1.x开发环境尝试小记
先说明安装的版本
idea20160204
jdk7
maven3.1.1
scala2.10.4
这里hadoop和spark的版本选了个较新2.6的:spark-1.6.3-bin-hadoop2.6;
因为spark2的用法出现了较大的变化,需要hadoop2.7。所以这次我们就用的是第一个等级的hadoop,选2.6。spark选了1.x。
整体的安装过程还算是顺利。但是里面也遇到了几个坑。
安装步骤
安装idea和idea的插件
检查java和maven,安装scala的运行环境
在idea中创建scala的工程
导入spark-1.6.3-bin-hadoop2.6的jar文件
调试程序
这个里面写入下面的代码,然后idea中创建application的应用,填写参数如下图
G:\spark-1.6.3-bin-hadoop2.6\spark-1.6.3-bin-hadoop2.6\README.md
G:\spark-1.6.3-bin-hadoop2.6\spark-1.6.3-bin-hadoop2.6\astron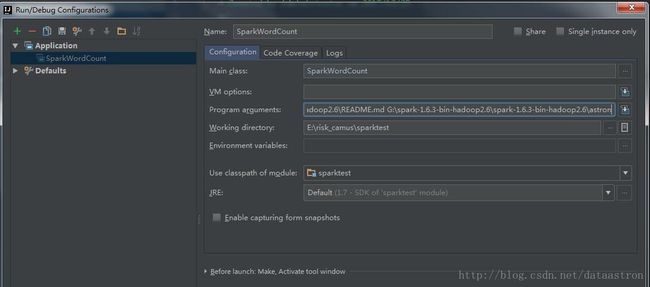
下面是程序
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount{
def main(args: Array[String]) {
//输入文件既可以是本地linux系统文件,也可以是其它来源文件,例如HDFS
if (args.length == 0) {
System.err.println("Usage: SparkWordCount " )
System.exit(1)
}
val conf = new SparkConf().setAppName("SparkWordCount").setMaster("local")
val sc = new SparkContext(conf)
//rdd2为所有包含Spark的行
val rdd2=sc.textFile(args(0)).filter(line => line.contains("Spark"))
//保存内容,在例子中是保存在HDFS上
rdd2.saveAsTextFile(args(1))
sc.stop()
}
}点击运行就会报个错
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/12/25 23:29:16 INFO SparkContext: Running Spark version 1.6.3
17/12/25 23:29:17 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/12/25 23:29:17 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:355)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:370)
at org.apache.hadoop.util.Shell.(Shell.java:363)
at org.apache.hadoop.util.StringUtils.(StringUtils.java:79)
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:104)
at org.apache.hadoop.security.Groups.(Groups.java:86)
at org.apache.hadoop.security.Groups.(Groups.java:66)
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:280)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:271)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:248)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:763)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:748)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:621)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2214)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2214)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2214)
at org.apache.spark.SparkContext.(SparkContext.scala:322)
at SparkWordCount$.main(SparkWordCount.scala:16)
at SparkWordCount.main(SparkWordCount.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
17/12/25 23:29:17 INFO SecurityManager: Changing view acls to: Administrator
17/12/25 23:29:17 INFO SecurityManager: Changing modify acls to: Administrator
17/12/25 23:29:17 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Administrator); users with modify permissions: Set(Administrator)
17/12/25 23:29:17 INFO Utils: Successfully started service 'sparkDriver' on port 14297.
17/12/25 23:29:18 INFO Slf4jLogger: Slf4jLogger started
17/12/25 23:29:18 INFO Remoting: Starting remoting提示的信息是缺少winutils.exe这个文件,至于为什么缺少这个文件,后面文章再分析。
解决方案是https://github.com/srccodes/hadoop-common-2.2.0-bin,下载整个git工程的zip,解压后。配置环境变量增加用户变量HADOOP_HOME,值是下载的zip包解压的目录,然后在系统变量path里增加$HADOOP_HOME\bin 即可。再次运行程序,正常执行。
把日志放在这里给大家参考。后面分析运行过程的时候要用到。
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
17/12/25 23:35:00 INFO SparkContext: Running Spark version 1.6.3
17/12/25 23:35:01 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/12/25 23:35:01 INFO SecurityManager: Changing view acls to: Administrator
17/12/25 23:35:01 INFO SecurityManager: Changing modify acls to: Administrator
17/12/25 23:35:01 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Administrator); users with modify permissions: Set(Administrator)
17/12/25 23:35:01 INFO Utils: Successfully started service 'sparkDriver' on port 1351.
17/12/25 23:35:02 INFO Slf4jLogger: Slf4jLogger started
17/12/25 23:35:02 INFO Remoting: Starting remoting
17/12/25 23:35:02 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@192.168.1.17:1364]
17/12/25 23:35:02 INFO Utils: Successfully started service 'sparkDriverActorSystem' on port 1364.
17/12/25 23:35:02 INFO SparkEnv: Registering MapOutputTracker
17/12/25 23:35:02 INFO SparkEnv: Registering BlockManagerMaster
17/12/25 23:35:02 INFO DiskBlockManager: Created local directory at C:\Users\Administrator\AppData\Local\Temp\blockmgr-1296ff30-a701-465d-8f1f-aaa72150ae05
17/12/25 23:35:02 INFO MemoryStore: MemoryStore started with capacity 2.4 GB
17/12/25 23:35:02 INFO SparkEnv: Registering OutputCommitCoordinator
17/12/25 23:35:02 INFO Utils: Successfully started service 'SparkUI' on port 4040.
17/12/25 23:35:02 INFO SparkUI: Started SparkUI at http://192.168.1.17:4040
17/12/25 23:35:02 INFO Executor: Starting executor ID driver on host localhost
17/12/25 23:35:02 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 1374.
17/12/25 23:35:02 INFO NettyBlockTransferService: Server created on 1374
17/12/25 23:35:02 INFO BlockManagerMaster: Trying to register BlockManager
17/12/25 23:35:02 INFO BlockManagerMasterEndpoint: Registering block manager localhost:1374 with 2.4 GB RAM, BlockManagerId(driver, localhost, 1374)
17/12/25 23:35:02 INFO BlockManagerMaster: Registered BlockManager
17/12/25 23:35:03 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 153.6 KB, free 2.4 GB)
17/12/25 23:35:03 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 13.9 KB, free 2.4 GB)
17/12/25 23:35:03 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:1374 (size: 13.9 KB, free: 2.4 GB)
17/12/25 23:35:03 INFO SparkContext: Created broadcast 0 from textFile at SparkWordCount.scala:19
17/12/25 23:35:03 WARN : Your hostname, USER-20160916LZ resolves to a loopback/non-reachable address: fe80:0:0:0:0:5efe:c0a8:111%19, but we couldn't find any external IP address!
17/12/25 23:35:04 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
17/12/25 23:35:04 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
17/12/25 23:35:04 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
17/12/25 23:35:04 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
17/12/25 23:35:04 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
17/12/25 23:35:04 INFO FileInputFormat: Total input paths to process : 1
17/12/25 23:35:04 INFO SparkContext: Starting job: saveAsTextFile at SparkWordCount.scala:21
17/12/25 23:35:04 INFO DAGScheduler: Got job 0 (saveAsTextFile at SparkWordCount.scala:21) with 1 output partitions
17/12/25 23:35:04 INFO DAGScheduler: Final stage: ResultStage 0 (saveAsTextFile at SparkWordCount.scala:21)
17/12/25 23:35:04 INFO DAGScheduler: Parents of final stage: List()
17/12/25 23:35:04 INFO DAGScheduler: Missing parents: List()
17/12/25 23:35:04 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[3] at saveAsTextFile at SparkWordCount.scala:21), which has no missing parents
17/12/25 23:35:04 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 65.0 KB, free 2.4 GB)
17/12/25 23:35:04 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 22.5 KB, free 2.4 GB)
17/12/25 23:35:04 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:1374 (size: 22.5 KB, free: 2.4 GB)
17/12/25 23:35:04 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1006
17/12/25 23:35:04 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[3] at saveAsTextFile at SparkWordCount.scala:21)
17/12/25 23:35:04 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
17/12/25 23:35:04 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, partition 0,PROCESS_LOCAL, 2172 bytes)
17/12/25 23:35:04 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
17/12/25 23:35:04 INFO HadoopRDD: Input split: file:/G:/spark-1.6.3-bin-hadoop2.6/spark-1.6.3-bin-hadoop2.6/README.md:0+3359
17/12/25 23:35:04 INFO FileOutputCommitter: Saved output of task 'attempt_201712252335_0000_m_000000_0' to file:/G:/spark-1.6.3-bin-hadoop2.6/spark-1.6.3-bin-hadoop2.6/astron/_temporary/0/task_201712252335_0000_m_000000
17/12/25 23:35:04 INFO SparkHadoopMapRedUtil: attempt_201712252335_0000_m_000000_0: Committed
17/12/25 23:35:04 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2337 bytes result sent to driver
17/12/25 23:35:04 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 248 ms on localhost (1/1)
17/12/25 23:35:04 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
17/12/25 23:35:04 INFO DAGScheduler: ResultStage 0 (saveAsTextFile at SparkWordCount.scala:21) finished in 0.260 s
17/12/25 23:35:04 INFO DAGScheduler: Job 0 finished: saveAsTextFile at SparkWordCount.scala:21, took 0.336883 s
17/12/25 23:35:04 INFO SparkUI: Stopped Spark web UI at http://192.168.1.17:4040
17/12/25 23:35:04 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
17/12/25 23:35:04 INFO MemoryStore: MemoryStore cleared
17/12/25 23:35:04 INFO BlockManager: BlockManager stopped
17/12/25 23:35:04 INFO BlockManagerMaster: BlockManagerMaster stopped
17/12/25 23:35:04 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
17/12/25 23:35:04 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
17/12/25 23:35:04 INFO SparkContext: Successfully stopped SparkContext
17/12/25 23:35:04 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
17/12/25 23:35:04 INFO ShutdownHookManager: Shutdown hook called
17/12/25 23:35:04 INFO ShutdownHookManager: Deleting directory C:\Users\Administrator\AppData\Local\Temp\spark-931d8206-5e34-47a5-bbd9-52de2967ab1b此demo的功能是过滤readme文件中含有spark的行。输出文件可以看到,一共有17行是包含spark单词的。注意重复执行会报错。需要删除生成的目录再执行。
