达观数据王子豪:这5个例子,小学生都能秒懂分类算法
分类算法作为数据挖掘、机器学习中重要的研究领域,在新闻分类、黄反广告识别、情感分析、观点挖掘等应用实践中都有着广泛的应用。如何将朴素贝叶斯、决策树、支持向量机这些常见的分类算法通俗易懂地讲给对人工智能感兴趣的人?达观研究院的这篇分类算法科普文章,以日常生活为例子,让小学生都能秒懂分类算法。

试想,8岁的小明是你刚上小学的儿子,长得可爱,古灵精怪,对世界充满好奇。
这天饭后,刚写完家庭作业的小明看到你在书桌前对着电脑眉头紧锁,便跑了过来问你:“爸爸(妈妈),你在做什么呀?”。
身为算法工程师的你正为公司的一个分类项目忙得焦头烂额,听到小明的问话,你随口而出:“分类!”
“分类是什么?”
听到儿子的追问,你的视线终于离开屏幕,但想说的话还没出口又咽了回去……
0 分类是什么?
简单来说,分类就是对事物进行区分的过程和方法。
在你眼里乖巧的小明是一个好孩子,同时你也想确保他会在学校做一名“好学生”而不是“坏学生”。这里的区分“好学生”和“坏学生”就是一个分类任务,关于这点,达观研究院可以帮你回答小明的疑问。
1 K最邻近
“别和其他坏学生在一起,否则你也会和他们一样。” —— 家长

这句话通常来自家长的劝诫,但它透露着不折不扣的近邻思想。在分类算法中,K最近邻是最普通也是最好理解的算法。它的主要思想是通过离待预测样本最近的K个样本的类别来判断当前样本的类别。
家长们希望孩子成为好学生,可能为此不惜重金购买学区房或者上私立学校,一个原因之一是这些优秀的学校里有更多的优秀学生。与其他优秀学生走的更近,从K最近邻算法的角度来看,就是让目标样本与其他正样本距离更近、与其他负样本距离更远,从而使得其近邻中的正样本比例更高,更大概率被判断成正样本。
2 朴素贝叶斯
“根据以往抓获的情况来看,十个坏学生有九个爱打架。” —— 教导主任

说这句话的训导主任很有可能就是通过朴素贝叶斯算法来区分好、坏学生。
“十个坏学生有九个爱打架”就意味着“坏学生”打架的概率P(打架|坏学生)=0.9,假设根据训导处历史记录坏学生占学生总数P(坏学生)=0.1、打架发生的概率是P(打架)=0.09,那么这时如果发生打架事件,就可以通过贝叶斯公式判断出当事学生是“坏学生”的概率P(坏学生|打架)=P(打架|坏学生)×P(坏学生)÷P(打架)=1.0,即该学生100%是“坏学生”。

朴素贝叶斯算法成立的一个前提是满足特征间条件独立假设。假如教导主任还管学生早恋问题,那么他通过“打架”和“早恋”两种特征来判断学生的前提必须是——在已知学生“好坏”的情况下“打架”和“早恋”之间没有关联。这样的假设可能和实际情况不符合,但让训导主任判断起来更加简单粗暴。
3 决策树
“先看抽不抽烟,再看染不染头发,最后看讲不讲脏话。” ——社区大妈

社区大妈经验丰富,有一套自己的判断逻辑。假设“抽烟”、“染发”和“讲脏话”是社区大妈认为的区分“好坏”学生的三项关键特征,那么这样一个有先后次序的判断逻辑就构成一个决策树模型。在决策树中,最能区分类别的特征将作为最先判断的条件,然后依次向下判断各个次优特征。决策树的核心就在于如何选取每个节点的最优判断条件,也即特征选择的过程。
而在每一个判断节点,决策树都会遵循一套IF-THEN的规则:
IF “抽烟” THEN -> “坏学生”
ELSE
IF “染发” THEN -> “坏学生”
ELSE IF “讲脏话” THEN -> “坏学生”
ELSE -> “好学生”
4 逻辑回归
“上课讲话扣1分,不交作业扣2分,比赛得奖加5分。” ——纪律委员

班上的纪律委员既勤恳又严格,总是在小本本上记录同学们的每一项行为得分。在完成对每一项行为的评分后,纪律委员根据最终加总得到的总分来判断每位同学的表现好坏。
上述的过程就非常类似于逻辑回归的算法原理。我们称逻辑回归为一种线性分类器,其特征就在于自变量x和因变量y之间存在类似y=ax+b的一阶的、线性的关系。假设“上课讲话”、“不交作业”和“比赛得奖”的次数分别表示为x1、x2、和x3,且每个学生的基础分为0,那么最终得分y=-1*x1-2*x2+5*x3+0。其中-1、-2和5分别就对应于每种行为在“表现好”这一类别下的权重。
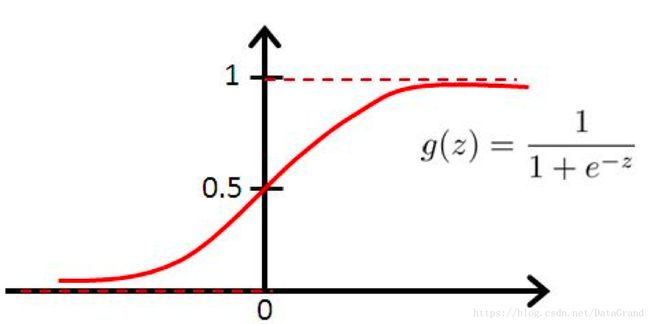 Sigmoid函数图像
Sigmoid函数图像
对于最终得分y,逻辑回归还通过Sigmoid函数将其变换到0-1之间,其含义可以认为是当前样本属于正样本的概率,即得分y越高,属于“表现好”的概率就越大。也就是说,假如纪律委员记录了某位同学分别“上课讲话”、“不交作业”和“比赛得奖”各一次,那么最终得分y=-2-1+5=2,而对2进行Sigmoid变换后约等于0.88,即可知该同学有88%的概率为“好学生”。
5 支持向量机
“我想个办法把表现差的学生都调到最后一排。” ——班主任
即使学生们再不情愿,班主任也有一万个理由对他们的座位作出安排。对于“坏学生”,一些班主任的采取的做法是尽量让他们与“好学生”保持距离,即将“坏学生”们都调到教室的最后一排。这样一来,就相当于在学生们之间画了一条清晰的分割界线,一眼就能区分出来。
支持向量机的思想就是如此。支持向量机致力于在正负样本的边界上找到一条分割界线(超平面),使得它能完全区分两类样本的同时,保证划分出的间隔尽量的大。如果一条分割界线无法完全区分(线性不可分),要么加上松弛变量进行适当的容忍,要么通过核函数对样本进行空间上的映射后再进行划分。对于班主任来讲,调换学生们的座位就相当于使用了核函数,让原本散落在教室里的“好”、“坏”学生从线性不可分变得线性可分了。
6 结束语
分类和分类算法的思想其实无处不在。而在实际工程中,分类算法的应用需要关注的地方还有很多。达观数据在中文文本分类方面拥有丰富的实践经验和心得。想了解这方面的内容,敬请期待下一篇文章《中文文本分类——你需要了解的10项关键内容》。
关于作者
王子豪:达观数据高级NLP算法工程师,负责达观数据文本挖掘和NLP算法的开发及应用,在文本分类、观点挖掘和情感分析等领域有丰富实践经验。