CUDA结构简介
基本概念:
GPU: Graphic Processing Unit;图形处理单元;
GPGPU: General Purpose computations on GPU;通用计算图形处理单元;
CPU与GPU的相同点:
(1)都是计算机体系结构中的重要组成部分;
(2)都是超大规模集成电路元件;
(3)都能够完成浮点运能功能;
CPU与GPU的不同之处:
(1)GPU的设计目的与CPU不同;CPU的微架构是按照兼顾“指令并行执行”和“数据并行运算”的思路而设计,其大部分晶体管主要用于构建控制电路和Cache,并且其内部有大约%5是ALU,控制电路则更为复杂;二GPU的控制电路则相对简单的对,而且对Cache的需求较小,所以可以把大部分的晶体管都用于计算单元。GPU的40%都是ALU;
(2)延迟不同,CPU的内存延迟是GPU的1/10;
(3)内存带宽不同;GPGPU的内存带宽是CPU的10倍;
(4)GPGPU具有更大的执行单元;
(5)线程轻重程度不同;CPU线程是软件管理的粗粒度重线程,当 CPU 线程被中断或者由于等待资源就绪状态就变为等待状态,操作系统就需要保存当前线程的上下文,并装载另外一个线程的上下文。这种机制使得CPU切换线程的代价十分高昂,通常需要数百个时钟周期。而GPU线程是硬件管理的细粒度轻线程,可以实现零开销的线程切换。当一个线程因为访问片外存储器或者同步指令开始等待以后,可以立即切换到另外一个处于就绪状态的线程,用计算来隐藏延迟,并且线程数目越多,隐藏延迟的效果越好。
(6)CPU属于“多核”,而GPU则属于“众核”;CPU 的每个核心具有取指和调度单元构成的完整前端,因而其核心是多指令流多数据流(Multiple Instruction Multiple Data,MIMD)的,每个 CPU 核心可以在同一时刻执行自己的指令,与其他的核心完全没有关系。但这种设计增加了芯片的面积,限制了单块芯片集成的核心数量。GPU的每个流多处理器才能被看作类似于 CPU 的单个核心,每个流多处理器以单指令流多线程方式工作,只能执行相同的程序。尽管 GPU 运行频率低于CPU,但由于其流处理器数目远远多于 CPU 的核心数,我们称之为“众核”,其单精度浮点处理能力达到了同期 CPU 的十倍之多。
(7)内存与寄存器之间的不同;目前的 CPU 内存控制器一般基于双通道或者三通道技术,每个通道位宽64bit;而GPU则有数个存储器控制单元,这些控制单元具备同时存取数据的能力,从而使得总的存储器位宽达到了 512bit。这个差异导致了GPU全局存储器带宽大约是同期CPU最高内存带宽的5倍;
(8)缓存机制不同;CPU 拥有多级容量较大的缓存来尽量减小访存延迟和节约带宽,但缓存在多线程环境下容易产生失效反应,每次线程切换都需要重建缓存上下文,一次缓存失效的代价是几十到上百个时钟周期。同时,为了实现缓存与内存中数据的一致性,还需要复杂的逻辑控制,CPU 缓存机制导致核心数过多会引起系统性能下降。在GPU 中则没有复杂的缓存体系与一致性机制,GPU 缓存的主要目的是随机访问优化和减轻全局存储器的带宽压力。
综上,GPU 是以大量线程实现面向吞吐量的数据并行计算,适合于处理计算密度高、逻辑分支简单的大规模数据并行负载;而 CPU 则有复杂的控制逻辑和大容量的缓存减小延迟,擅长复杂逻辑运算。
GPU的一些缺点:
1. 显示芯片的运算单元数量很多,因此对于不能高度并行化的工作,所能带来的帮助就不大。
2. 显示芯片目前通常只支持 32 bits 浮点数,且多半不能完全支持 IEEE 754 规格, 有些运算的精确度可能较低。目前许多显示芯片并没有分开的整数运算单元,因此整数运算的效率较差。
3. 显示芯片通常不具有分支预测等复杂的流程控制单元,因此对于具有高度分支的程序,效率会比较差。
4. 目前 GPGPU 的程序模型仍不成熟,也还没有公认的标准。例如 NVIDIA 和 AMD/ATI 就有各自不同的程序模型。
最后,需要提醒的是,GPU最近几年的发展势头很凶猛,以至于OpenCV2.4已经开始考虑利用GPU来加速程序的运算了;而大名鼎鼎的NVIDIA公司前段时间也宣布开始和OpenCV进行合作推进计算机视觉算法的GPU加速;
CUDA架构:
随着显卡的发展,GPU越来越强大,而且GPU为显示图像做了优化。在计算上已经超越了通用的CPU。如此强大的芯片如果只是作为显卡就太浪费了,因此NVidia推出CUDA,让显卡可以用于图像渲染和计算以外的目的(例如这里提到的通用并行计算)。CUDA即Compute Unified Device Architecture,是NVidia利用GPU平台进行通用并行计算的一种架构,它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。开发人员可以利用C言、OpenCL、Fortran、c++等为CUDA架构编写程序。它们同CUDA之间的关系如下图所示:

上图就很好的反映出了CUDA与应用程序接口(API)以及各种语言编译器的关系,其中的DX11计算也就是Direct Compute。包括CUDA自家编译器所采用的C语言扩展、OpenCL应用程序接口、Fortran甚至C++等都可以运行在CUDA架构之上,未来CUDA还将支持更多的语言。在整个产业的共同推动下,GPU计算可谓是前途无量!
从CUDA体系结构的组成来说,它包含了三个部分:开发库、运行期环境和驱动。
(1)开发库是基于CUDA技术所提供的应用开发库。
(2)运行期环境提供了应用开发接口和运行期组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。
(3)驱动部分是CUDA-enable的GPU的设备抽象层,提供硬件设备的抽象访问接口。CUDA提供运行期环境也是通过这一层来实现各种功能的。目前于CUDA开发的应用必须有NVIDIA CUDA-enable的硬件支持。CPU,GPU,应用程序,CUDA开发库,运行环境,驱动之间的关系如下图所示:

在 CUDA 的架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片(GPU)上执行的部份。Device 端的程序又称为 "kernel"。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。由于 CPU 存取显卡内存时只能透过 PCI Express 接口,因此速度较慢(PCI Express x16 的理论带宽是双向各 4GB/s),因此不能经常进行这类动作,以免降低效率。

在 CUDA 架构下,显示芯片执行时的最小单位是 thread。数个thread 可以组成一个 block。一个 block 中的 thread 能存取同一块共享的内存,而且可以快速进行同步的动作。不同 block 中的 thread 无法存取同一个共享的内存,因此无法直接互通或进行同步。因此,不同 block 中的 thread 能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的 thread 数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个 block 中的 thread 顺序执行,而非同时执行。不同的 grid 则可以执行不同的程序(即 kernel)。Grid、block 和 thread 的关系,如下图所示:

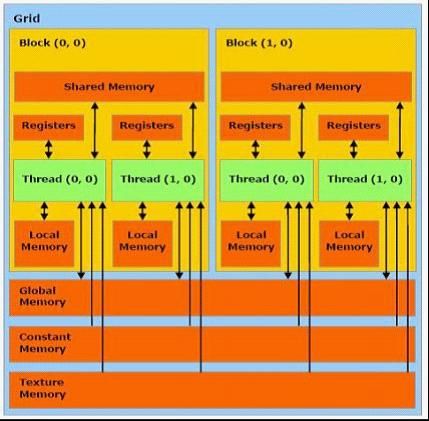
每个 thread 都有自己的一份 register 和 local memory 的空间。同一个 block 中的每个 thread 则有共享的一份 share memory。此外,所有的 thread(包括不同 block 的 thread)都共享一份 global memory、constant memory、和 texture memory。不同的 grid 则有各自的 global memory、constant memory 和 texture memory。如下图所示:
由于显示芯片大量并行计算的特性,它处理一些问题的方式,和一般 CPU 是不同的。主要的特点包括:
1. 内存存取 latency (等待时间)的问题:CPU 通常使用 cache 来减少存取主内存的次数,以避免内存 latency 影响到执行效率。显示芯片则多半没有 cache(或很小),而利用并行化执行的方式来隐藏内存的 latency(即,当第一个 thread 需要等待内存读取结果时,则开始执行第二个 thread,依此类推)。
2. 分支指令的问题:CPU 通常利用分支预测等方式来减少分支指令造成的 pipeline(流水线) bubble。显示芯片则多半使用类似处理内存 latency 的方式。不过,通常显示芯片处理分支的效率会比较差。
因此,最适合利用 CUDA 处理的问题,是可以大量并行化的问题,才能有效隐藏内存的 latency,并有效利用显示芯片上的大量执行单元。使用 CUDA 时,同时有上千个 thread 在执行是很正常的。因此,如果不能大量并行化的问题,使用 CUDA 就没办法达到最好的效率了。在这个过程中,CPU担任的工作为控制 GPU执行,调度分配任务,并能做一些简单的计算,而大量需要并行计算的工作都交给 GPU 实现。另外需要注意的是,由于 CPU 存取显存时只能通过 PCI-Express 接口,速度较慢,因此不能经常进行,以免降低效率。通常可以在程序开始时将数据复制进GPU显存,然后在 GPU内进行计算,直到获得需要的数据,再将其复制到系统内存中。