centos 7搭建hadoop环境及踩到的坑
一、修改主机名称
1.vi /etc/hostname
这个文件的内容便是主机名称,将其内容修改为你需要的主机名称
2.vi /etc/hosts
用于网络DNS解析,将127.0.0.1和::1对应的行修改为你需要的主机名称
3.hostnamectl
查看static hostname值是否为你需要的主机名称
二、静态IP解析
若域内没有DNS服务器,那么需要对每个主机设置静态IP解析,只需要修改/etc/hosts内容即可,在/etc/hosts添加IP映射,每一行为一个记录(IP地址+空格+主机名)
三、进行Linux无密码登录设置
($HOMEDIR)表示家目录,例如,/root ,/home/hadoop
hostnameA表示A的主机名称
username表示登录主机用的用户名
1.在每个计算机上生成公钥和私钥,命令为ssh-keygen -t rsa,需要提前安装了ssh
2.使用ssh_COPY_ID -i ($HOMEDIR)/.ssh/id_rsa.pub (username)@(hostnameA)将公钥集中到某个主机上
3.在hostnameA上使用命令 ssh-copy-id -i ($HOMEDIR)/.ssh/id_rsa.pub root@localhost
4.将hostnameA上的($HOMEDIR)/.ssh/authorized_keys复制至其他主机上scp ($HOMEDIR)/.ssh/authorized_keys(username)@(hostnameB):/root/.ssh/
5.使用ssh命令测试连接是否正常
四、首先需要理解hadoop的基本架构,下面两幅图分别为HDFS和YARN的基本结构图
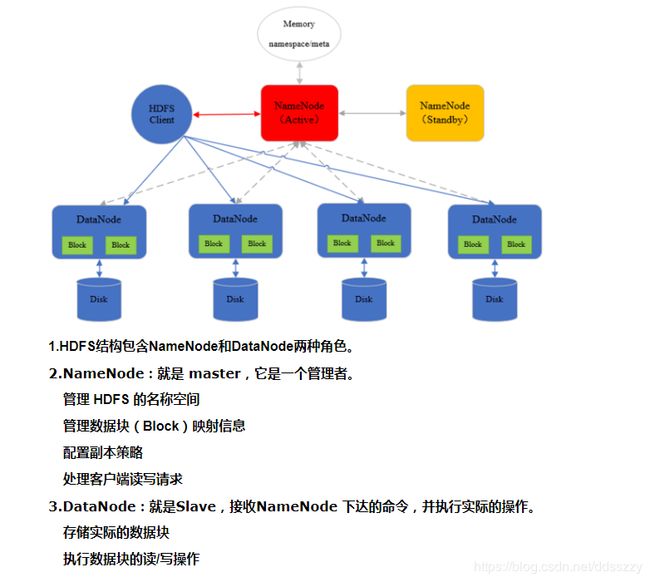

五、进行hadoop配置
配置文件位于hadoop解压后的目录下的etc/hadoop目录,我的集群中包含了bigdata-senior01.chybinmy.com,bigdata-senior02.chybinmy.com,bigdata-senior03.chybinmy.com,bigdata-senior04.chybinmy.com四台机器,将bigdata-senior01.chybinmy.com设置为namenode,其余为datanode,将bigdata-senior02.chybinmy.com设置为resourceManager,其余为NodeManager。在某一台机器上配置,所有文件均包含了xml头
core-site.xml文件
hdfs-site.xml文件
yarn-site.xml文件
mapred-site.xml文件
workers文件
bigdata-senior01.chybinmy.com
bigdata-senior02.chybinmy.com
bigdata-senior03.chybinmy.com
bigdata-senior04.chybinmy.com
hadoop-env文件增加一行
export JAVA_HOME=/usr/local/jdk-10.0.2
格式化hdfs本地系统
$HADOOP_HOME/bin/hdfs namenode -format
若是出现INFO common.Storage: Storage directory /usr/local/hadoop/tmp/namenode has been successfully formatted字样,表示格式化成功。
分发六个配置文件至其他主机。我使用SCP命令来分发的
在datanode节点开启datanode服务
$HADOOP_HOME/bin/hdfs --daemon start datanode
在NameNode节点开启NameNode服务
$HADOOP_HOME/bin/hdfs --daemon start namenode
出现错误:
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [bigdata-senior01.chybinmy.com]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
先暂停 hdfs服务:$HADOOP_HOME/sbin/stop-dfs.sh
编辑所有主机的/etc/hadoop下的hadoop-env.sh文件,
增加四行如下:
export HDFS_DATANODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
这四行的作用是指定可执行hdfs命令的用户
重新执行一下sh ./hadoop-env.sh
在resourceManager节点上开启resourceManager服务,运行命令$HADOOP_HOME/bin/yarn --daemon start resourcemanager
在nodeManager上起开nodeManager服务,运行命令$HADOOP_HOME/bin/yarn --daemon start nodemanager
在nodeManager上运行命令$HADOOP_HOME/sbin/start-yarn.sh ,出现错误
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
在nodeManager的hadoop-env.sh中,增加两行:
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
再次运行$HADOOP_HOME/bin/yarn --daemon start nodemanager
在ResourceManager上运行$HADOOP_HOME/bin/mapred --daemon start historyserver
Use --illegal-access=warn
当hadoop启动命令执行结束后,可以通过查看webUI来检查hadoop运行状况:
namenode查看网址为172.168.0.5:9870
错误:
stopping yarn daemons
no resourcemanager to stop
bigdata-senior04.localdomain: no nodemanager to stop
bigdata-senior02.localdomain: no nodemanager to stop
bigdata-senior03.localdomain: no nodemanager to stop
bigdata-senior01.localdomain: no nodemanager to stop
原因:
中,将下划线"_"写成了横杠"-"
错误:
INFO client.RMProxy: Connecting to ResourceManager at bigdata-senior02.localdomain/172.168.0.6:8081
INFO ipc.Client: Retrying connect to server: bigdata-senior02.localdomain/172.168.0.6:8081
同时jps命令下有nodeManager,无resourceManger,说明resourceManger没有启动起来,通过查看日志/usr/local/hadoop-2.8.4/logs/yarn-root-resourcemanager-bigdata-senior02.chybinmy.com.log发现不能初始化FairScheduler
我将
注释掉之后就没事儿了,后来发现应该把value值写为org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler,连官网都不能信啊
错误:使用hadoop fs -put命令上传文件
WARN ipc.Client: Failed to connect to server: bigdata-senior01.localdomain/172.168.0.5:8020:
命令应该为 hadoop fs -put ./shakespeare.txt hdfs://172.168.0.5:9000/或者hadoop fs -put ./shakespeare.txt /
错误:status=ERROR, status message , ack with firstBadLink as 172.168.0.8:50010
原因:172.168.0.8防火墙未关闭
错误:
java.io.IOException: org.apache.hadoop.yarn.exceptions.InvalidResourceRequestException: Invalid resource request, requested memory < 0, or requested memory > max configured, requestedMemory=1536, maxMemory=256
原因:
程序申请的内存资源超出了yarn的设置。在程序中添加两行代码:
修改etc/hadoop/yarn-site.xml里面yarn.nodemanager.resource.memory-mb的值,使其大于mapreduce.map.memory.mb和mapreduce.reduce.memory.mb的值即可
错误:PipeMapRed.waitOutputThreads(): subprocess failed with code 2
原因:从window系统向linux系统传送文件时,当以binary方式传送就会出现错误,修改为text传送,即正确,当然传送之后需要设置可执行权限。根本上是文件格式出了问题
错误:PipeMapRed.waitOutputThreads(): subprocess failed with code 1
原因:程序内部问题,本地就是失败的,出现了异常