Faster_rcnn论文阅读及caffe训练实践(1)——理论简要介绍部分
最近因为公司工作需要,所以需要训练一个人脸检测模型,于是查询了一些物体识别的方法。发现业界目前主流的方法主要是rcnn系列(最新代表作faster-rcnn) ,以及ssh yolo等,考虑到实验难度,我选取了开源并且支持caffe的faster_rcnn作为人脸检测的起点。这篇文章也是主要介绍faster_rcnn理论及实践相关的入门类文章。
由于本人功底有限加上已经有很多讲rcnn的文章,我这篇文章主要是个人学习体会的一个总结,观看者如果有所疑惑,可以共同探讨学习。
0.目标检测的目标是什么?


首先说说目标检测是为了干啥,通过一个例子来说明。假设我们有一张图片如上,我们想检测出人脸(目标的一种),我们这张图片是400*400分辨率的,人脸的宽高是200,人脸目标的中心点(大致在鼻子附近)坐标为(195,243),那么这张图片的人脸检测的label=(x,y,w,h)=(195,243,200,200),也就是图片中红色框框。 通过这个例子可以说明目标检测/人脸检测做了一件什么事情。
1.一种简单的使用滑动窗口检测方法
讲完目标检测的概念之后,我们来设想一种比较简单的目标检测方法来当作介绍rcnn之前的开胃菜。
比如我们有一张图片,我们通过滑动窗口的方法,从上到下从左到右依次选取图片,比如一个400×400的图片,有一个200×200的滑动窗口,步长为100,那么可以得到3×3共9个 候选框。然后依次将这9个候选框放到图片分类模型中,就可以得到9个候选框的分类结果,比如我们有4种类别(人,狗,车,背景)。那么一张输入图片,最终可以得到9个候选框,每个候选框对应四个概率(人、狗、车,背景)的概率。
在上述的目标检测的方法,实际上是包含一个特征框选取+图片识别两个过程。其实这种思想和rcnn就已经很接近了,下面具体来介绍rcnn系列方法。
2.rcnn系列之rcnn
rcnn系列是rgb大神的著作(后续还有kaiming he / jian sun等大神),这里先拿系列的第一篇rcnn作为开始。
首先rcnn有些地方很像是我们刚才提到的那个比较简单的检测方法。下面通过简述rcnn主要过程。
步骤1. 使用select search(理论上也可以使用其他候选框生成方法),在一张图片中生成n张候选检测框(比如2000张)。
步骤2.将这些生成的候选框通过一个cnn(alexnet,resnet,googlenet等)图像识别网络进行识别,该网络可以通过imagnet等识别训练集预训练得到,如果你做人脸检测任务,那这一步应该采用人脸识别数据进行训练。
步骤3.使用步骤2的模型,进行特征提取(特征层一般采用分类fc之前那一层),并使用svm进行二分类训练(0代表是该类,1代表不是该类)。同时训练一个精修器进行回归,修正回归框的坐标(就是上面提到的label=(x,y,w,h)=(195,243,200,200),)。
示意图如下:

应该说rcnn训练过程中还有很多细节没有提到,但是因为我们这里主要还是使用faster-rcnn所以,rcnn就简单介绍到这里。
rcnn特点:可以看出rcnn和使用滑动窗口进行检测的方法很类似,多了主要几步a.多了一个回归精修 b.使用了sst替代单纯的滑动窗口生成候选框 c.使用svm+cnn特征来进行分类而不是直接用cnn+softmax。
rcnn优缺点:优点主要是开创了使用深度学习进行目标检测的先河 缺点主要是候选框生成速度较慢,而且多了对候选框的cnn特征提取有很多可以简化的重复计算。
为了解决rcnn的缺点,于是就有了fast-rcnn和faster-rcnn等文章。
3.rcnn系列之fast-rcnn
R-CNN与Fast RCNN的区别:
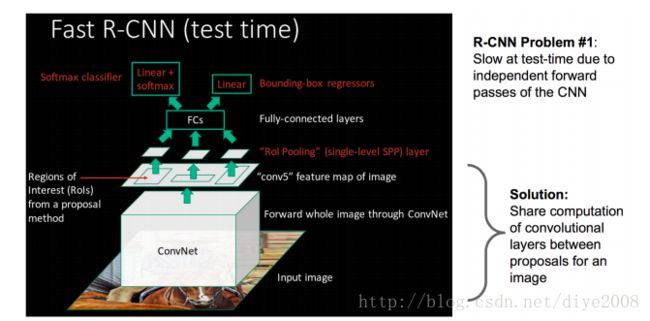
rcnn即使使用了selective search等预处理步骤来提取潜在的bounding box(候选回归框)作为输入,但是RCNN仍会有严重的速度瓶颈,因为有候选框特征的重复计算。于是作者提出了一个叫做ROI Pooling的网络,这个网络层可以把不同大小的输入映射到一个固定尺度的特征向量,conv、pooling、relu等操作都不需要固定size的输入,因此,在原始图片上执行这些操作后,虽然输入图片size不同导致得到的feature map尺寸也不同,不能直接接到一个全连接层进行分类,但是可以加入了的ROI Pooling层,对每个region都提取一个固定维度的特征表示,再通过正常的softmax进行类型识别。另外,之前RCNN的处理流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression,而在Fast-RCNN中,作者把bbox regression放进了神经网络内部,与region分类和并成为了一个multi-task模型,实际实验也证明,这两个任务能够共享卷积特征,并相互促进。
rcnn方法:许多候选框(2000张)->CNN->得到每个候选框的特征-->分类+回归
fast-rcnn方法:一张完整图片->CNN->得到每张候选框的特征(比如第5层)-->分类+回归
示意图如下,重点是cnn的第5层才进行ss
4.rcnn系列之faster_rcnn
首先说下fast_rcnn的缺点,虽然解决rcnn中大量候选框重复特征计算的问题,但是候选框选取操作仍然比较费时。于是有了根据神经网络(rpn网络)进行候选框选取的faster_rcnn.
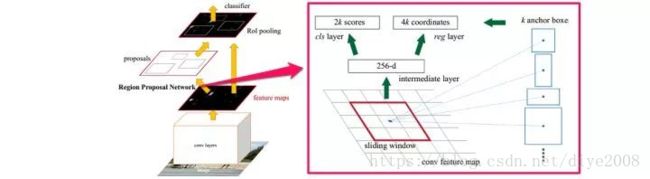
rcnn的具体位置如上图所示,放在回归精修器+分类器 和 图片输入层 这两部分之间,rpn本身也有两个损失函数,分别用来回归候选框的位置和候选框是否有物体等。
于是faster_rcnn(含rpn部分)共四个损失函数:
• RPN calssification(该候选框是否有物体0/1)
• RPN regression(候选框位置回归)
• Fast R-CNN classification(faster_rcnn最终的物体类别划分,eg(人,车,狗,背景))
• Fast R-CNN regression(候选框位置精修)
这样到此为止就简要介绍了一下faster_rcnn系列进行物体检测的理论。具体不明之处可以参考论文地址如下:
https://arxiv.org/abs/1506.01497