hash trick在机器学习中的使用
一、为什么需要hash trick?
在工业界,数据经常不仅是量大,而且维度也很高,所以出现很多具体的大规模的机器学习问题,比如点击率预测问题。在CTR中,特征涉及到广告主和用户等。大多特征都可以看做categorical。对categorical feature一般使用1-of-c编码方式(统计里称为dummy coding)。对于取值为实数的特征我们可以进行离散化处理(实际应用中一般也不直接把连续值的特征直接交由模型处理)。可能有的特征对应的取值非常多,所以这种编码方式就容易导致维度非常高(维数灾难问题)。当然也有其他原因造成该问题维度很高,比如将不同特征做笛卡尔积产生新的特征(参考链接6中提到很多广告公司宣称使用的几十上百亿特征都是用这个方法搞出来的)。
那如何降维呢?我们可以首先去除特征中不频繁的值,这样特征对应的取值减少,维数会降低。但是这种方法需要对数据进行预处理。至于PCA等常见的降维方法,由于数据量实在太大而不太适合使用。而hash trick是一种越来越受欢迎的降维方法。它不需要进行数据预处理,实现简单直接。
对于一些非线性问题,我们可以将输入空间映射到高维的特征的空间,使问题变成一个线性问题。使用kernel trick可以通过低维度的样本点的核函数计算得到高维度中向量的内积。但是在文本分类问题中,就会碰到一个问题。文本分类问题也是一个典型的高维问题,而且由于手工添加的一些非线性特征,原始的输入空间就线性可分,这样就没必要在将输入映射到更高位的特征空间了。而是需要使用降维方法。hash trick和kernel trick的作用相反。
二、hash trick的实现过程
哈希技巧具体实现时,可以有两个策略:
1.对每个特征f均进行转换,结果为![]() 。这样最终总共维度为:
。这样最终总共维度为:
![]()
2、对所有特征哈希到同一个空间。这里假设原本有n维,最后输出为d维。如果n < d ,我们称之为压缩表示(compressed representation),此时肯定有多个原始维度冲突的情形,但实验表明这对问题求解影响不大(参考链接1提到)。
首先讲Count-Min sketch算法的使用。第一次接触Count-min算法还是用在数据流中做统计频繁元素出现次数。这里只涉及count步,没涉及min步。最终的结果向量里面每一位的取值就是哈希到该位的原始特征数目。
我们将特征向量u每一位哈希到k个桶(也就是k维向量w)中,哈希后的值就是该桶里元素的总和。这里Pr(h(i)=j)=1/k,其中j={1,2,…,k}。我们假设![]() 。则最终w的每一位的取值为
。则最终w的每一位的取值为

上面这种是简单的版本。可以基于此做些许修改,一般称为Vowpal Wabbit。其中![]() 是将i均匀哈希到{-1,1}中的每个元素。
是将i均匀哈希到{-1,1}中的每个元素。
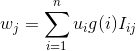
这种降维方法是否会损失原始特征的表达能力呢?这个实际实验效果最能说明问题。
注:在论文里和博客会提到修改版本是简单版本的无偏估计的改进。他们所说的无偏估计是把count-min sketch或者Vowpal Wabbit作为估计两个高维向量内积来说的,跟这里应用到特征哈希问题关系不大。
三、基于最小哈希的hash trick的实现。
这里再介绍一种基于最小哈希Min Hash的hash trick。这种方法要求数据必须是binary data。对特征向量x进行随机转换进行一次MinHash,得到哈希结果,取哈希结果(二进制表示)的最后b位。就是b-bit Min Hash的过程。该过程重复k次。这样每个样本就可以用k*b位进行表示。一般选k>=200,b>=8时效果接近原本方法,但处理的时间和空间要求大大降低。
举个例子,如果k=3,某个样本的最小哈希的结果为{12013,25964,20191},二进制表示为{10111011101101,110010101101100,100111011011111}。设b=2,则只取哈希结果最后两位,{01,00,11},十进制就是{1,0,3}。接着把每个b-bit哈希的结果拓展成2^b=4位,也就是{0010,0001,1000},一共需要k*2^b=12位。我们把最终得到的{0010,0001,1000}喂给一些分类器(Liblinear等)即可。
四、总结
整体来讲,hash trick可以作为一种降维方法,实现简单,所需计算量小,效果较好。hash trick可以保持原有特征的稀疏性(preserve sparsity)。缺点是哈希后学习到的模型很难检验,无法对模型参数做解释。
五、参考链接
1.Simple and scalable response prediction for display advertising 。
2.Feature Hashing for large scale multitask learning。经典。
3.Hashing algorithm for large scale learning。介绍最小哈希在特征哈希的作用。
4.http://www.cnblogs.com/kemaswill/p/3903099.html。
5.http://hunch.net/~jl/projects/hash_reps/。有微博大牛转发过这条链接。是hash trick应用在机器学习中论文总结。
6.https://breezedeus.github.io/2014/11/20/breezedeus-feature-hashing.html。结合实际项目谈在multi-task中的应用,总结的挺好。